 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
Контакты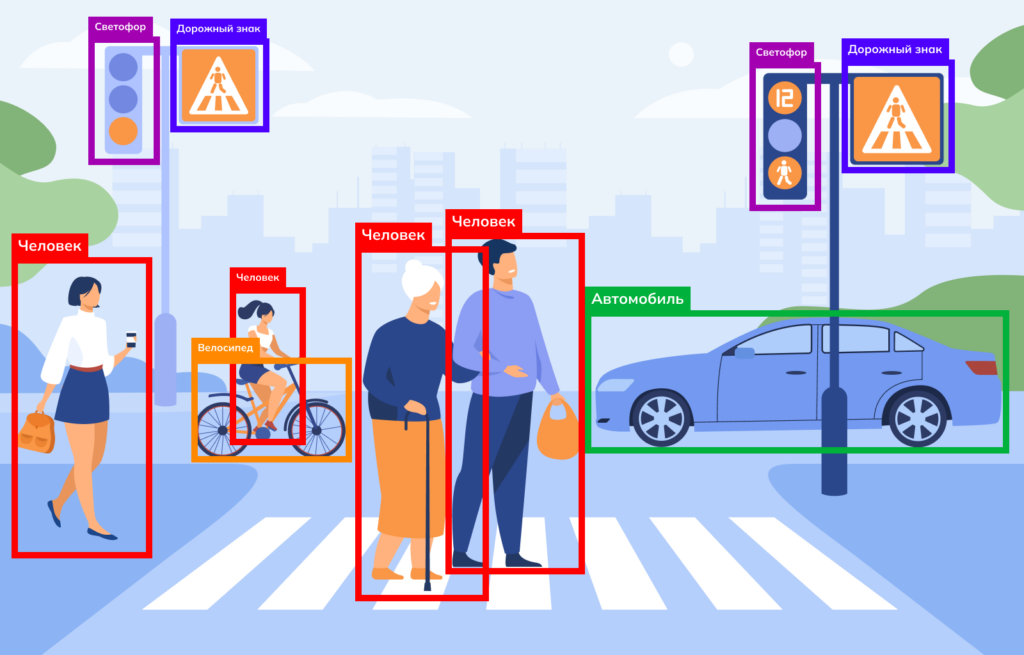
Что такое детекция объектов?
Детекция объектов (Object Detection) — это задача компьютерного зрения, направленная на поиск и локализацию отдельных объектов на изображении или в видеопотоке.
Процесс включает два основных шага:
- Определение наличия объектов — модель анализирует изображение и определяет, какие объекты присутствуют и к какому классу они относятся.
- Локализация объектов — каждому найденному объекту присваивается ограничивающая рамка (bounding box). Эта рамка представляет собой четырехугольник, который очерчивает границы объектов, указывая их местоположение и размеры с помощью набора параметров:
- x_min, y_min и x_max, y_max — координаты верхнего левого и нижнего правого угла. Указывают, где начинается и заканчивается bounding box на изображении. Позволяют точно определить положение рамки относительно всего изображения.
- x, y — координаты центра bounding box.
Width, height — ширина и высота рамки — разница между x_max и x_min и y_max и y_min соответственно.

Сравнение с другими задачами компьютерного зрения
Детекция объектов — это лишь одна из задач компьютерного зрения. Чтобы лучше понять ее особенности, важно провести сравнение с другими схожими задачами: классификацией изображений и сегментацией.
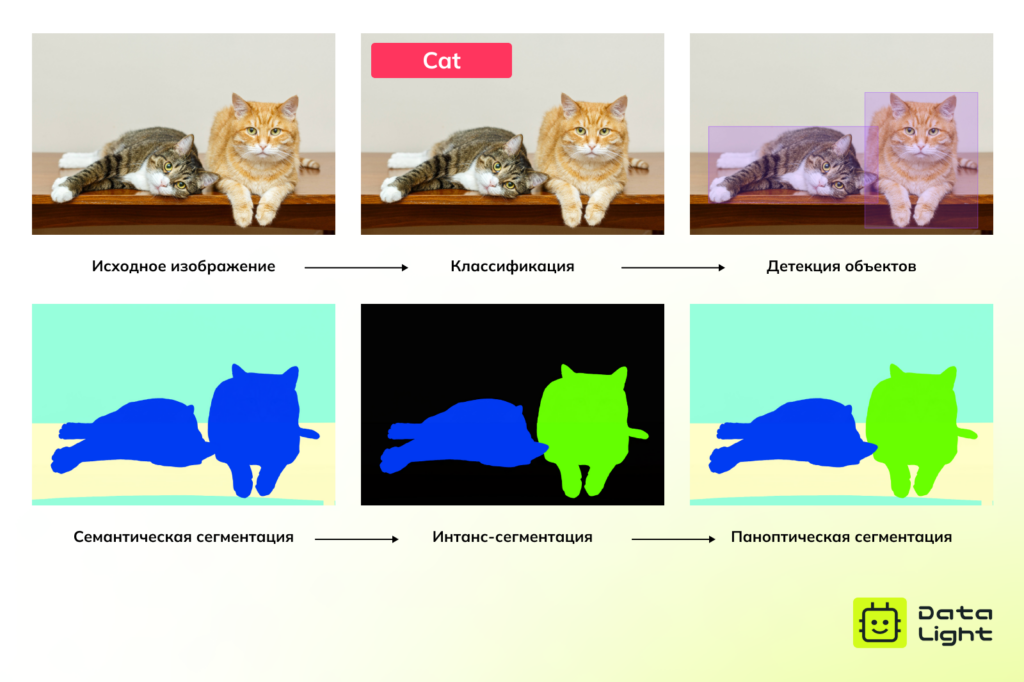
Классификация — это базовая задача компьютерного зрения. Ее цель — определить, какие объекты присутствуют на изображении, и присвоить им соответствующие метки классов. Однако классификация не дает информации о том, где именно находятся объекты.
Детекция объектов, в отличие от классификации, не только определяет классы объектов, но и локализует их на изображении. Например, модель может одновременно определить, что на изображении есть кот и указать координаты его местоположения с помощью ограничивающей рамки.
Сегментация решает более детализированную задачу: вместо того, чтобы просто обвести объект рамкой, она определяет его точные границы на уровне пикселей, создавая маску для каждого объекта.
Различают три типа сегментации:
- Семантическая сегментация — определяет, к какому классу относится каждый пиксель изображения, но не различает отдельные объекты внутри одного класса. Например, на изображении с котами каждый кот будет помечен одинаково.
- Инстанс-сегментация — различает объекты одного класса (два разных кота), но игнорирует фоновые объекты, не относящиеся к целевым классам.
- Паноптическая сегментация — объединяет принципы семантической и инстанс-сегментации. Она определяет класс каждого пикселя и различает отдельные объекты внутри одного класса, включая целевые и фоновые объекты.
Применение детекции объектов
Детекция объектов — это мощный инструмент, который находит применение в самых разных сферах. Она позволяет автомобилям видеть дорогу, камерам безопасности распознавать лица, а врачам — быстрее и точнее ставить диагнозы. Рассмотрим, где эта технология используется чаще всего.
Автономный транспорт
Беспилотные автомобили и системы помощи водителю (ADAS) используют детекцию объектов, чтобы распознавать пешеходов, велосипедистов, машины, светофоры, дорожные знаки, животных и другие объекты на дороге и рядом с ней. Благодаря этому автомобили могут автоматически тормозить, менять полосу и избегать столкновений, а также прогнозировать поведение других участников движения. Без этой технологии полноценное автономное вождение было бы невозможным.

Медицина
Детекция объектов в медицине помогает автоматически выявлять опухоли, переломы, кровоизлияния и другие патологии на рентгеновских снимках, КТ, МРТ и УЗИ. Это ускоряет диагностику и снижает вероятность ошибок, особенно в сложных случаях.
Промышленность
На производстве детекция объектов используется для выявления брака на всех этапах — от поступления сырья до упаковки изделия. Умные камеры автоматически распознают дефекты, отклонения в форме, размере или цвете, контролируют правильность сборки компонентов. Это снижает количество брака, повышает качество продукции и сокращает затраты на ручной контроль.
Сельское хозяйство
Используя снимки с дронов и видеокамер, детекция объектов помогает выявлять болезни растений, обнаруживать вредителей, сорняки, оценивать зрелость и количество плодов, определять участки, нуждающиеся в поливе или удобрениях, контролировать перемещение скота. Это позволяет оптимизировать использование ресурсов, снижать потери урожая и повышать эффективность сельского хозяйства.

Розничная торговля
Компьютерное зрение и детекция объектов помогают магазинам отслеживать наличие товаров на полках, своевременно пополнять стеллажи и анализировать движение покупателей по торговому залу. В онлайн-торговле эти технологии используются для автоматического поиска товаров по изображениям и создания персонализированных рекомендаций.
Безопасность и видеонаблюдение
Системы безопасности используют детекцию объектов для распознавания лиц, выявления подозрительного поведения и обнаружения оставленных предметов. Умные камеры в режиме реального времени анализируют обстановку, фиксируют потенциальные угрозы и мгновенно оповещают службы безопасности. Это помогает предотвращать преступления и обеспечивать порядок в общественных местах.

Как работает детекция объектов?
Традиционные методы детекции объектов
До появления глубоких нейросетей детекция объектов строилась на использовании математических алгоритмов, которые анализировали особенности изображения, такие как границы, текстуры и цветовые переходы.
Основные методы:
Каскады Хаара
Метод, предложенный Полом Виолой и Майклом Джонсом в 2001 году, стал одним из первых и крайне значимых прорывов в области автоматической детекции объектов. В настоящее время используется в библиотеке OpenCV.

Как работает:
- Метод ищет объекты по перепадам яркости. Для этого используются простые прямоугольные шаблоны — признаки Хаара. Например, шаблон из светлой и темной области может выделить границу между лбом и глазами на лице.
- Чтобы система лучше распознавала объекты, применяется алгоритм AdaBoost — он объединяет простые классификаторы в один сильный. При этом особое внимание уделяется примерам, где раньше были ошибки.
- Также используется каскадная структура — это последовательность фильтров. Каждый этап отбрасывает ненужные участки изображения. Если участок не прошел проверку на первом шаге, дальше он не анализируется. Это значительно ускоряет процесс детекции.
| Плюсы | Минусы |
|---|---|
| Быстро работает на изображениях с небольшим разрешением и относительно однородным фоном. | Плохо работает при изменении освещения. |
| Хорошо справляется с объектами, расположенными фронтально. | Высокий уровень ложных срабатываний, особенно при наличии шума. |
HOG + SVM (Гистограммы направленных градиентов + Метод опорных векторов)
Метод появился в 2005 году и долгое время использовался для распознавания пешеходов и машин.
Как работает:
- Изображение делится на небольшие участки (ячейки). В каждой ячейке определяется направление наибольшего изменения яркости пикселя — это и есть градиенты.
- Для каждой ячейки строится гистограмма, показывающая, сколько градиентов попадает в каждое из заранее заданных направлений (обычно 9 направлений).
- Несколько ячеек объединяются в группы, и все полученные данные собираются в один набор признаков — вектор HOG, который описывает форму объекта на изображении.
- После этого используется метод опорных векторов (SVM) — алгоритм машинного обучения, который находит границу между классами объектов. Он выбирает такую границу (гиперплоскость), которая максимально разделяет разные классы, например, «пешеход» и «не пешеход».
| Плюсы | Минусы |
|---|---|
| Хорошо работает с простыми объектами с четкими границами. | Не подходит для сложных сцен и перекрывающихся объектов. |
| Относительно простая реализация. | Является фиксированным алгоритмом вычисления признаков. Это ограничивает его адаптивность к различным условиям. |
Глубокое обучение и сверточные нейросети
Традиционные методы имели жесткие ограничения: они зависели от заранее заданных признаков и не могли адаптироваться к сложным сценариям. С появлением сверточных нейросетей (CNN) детекция объектов вышла на новый уровень.
Основная идея:
CNN автоматически извлекают признаки из изображений, используя иерархическую структуру слоев. Это позволило нейросетям научиться находить объекты даже в сложных условиях.
Как работает:
- Изображение проходит через последовательность сверточных слоев, каждый из которых применяет к изображению (или выходу предыдущего слоя) набор фильтров (ядер свертки). Каждый фильтр выделяет определенный признак, например, вертикальную линию, угол, дугу и т. д.
- После сверточного слоя обычно применяется функция активации (например, ReLU), которая вносит нелинейность в модель.
- Между сверточными слоями часто используются pooling-слои, которые уменьшают размерность данных, сохраняя при этом наиболее важную информацию. Это делает сеть более устойчивой к небольшим сдвигам и искажениям объекта, а также уменьшает вычислительную сложность.
- Глубокие слои сети комбинируют простые признаки в более сложные, формируя иерархическое представление изображения. Например, простые признаки (линии, углы) могут объединяться в более сложные (части объектов).
- Выходные слои сети (могут включать как сверточные, так и полносвязные слои) предсказывают классы объектов и параметры ограничивающих рамок (координаты, ширину, высоту).
| Плюсы | Минусы |
|---|---|
| Не требует ручного создания признаков. | Необходимо много данных для обучения. |
| Адаптируется к разным условиям съемки. | Нужны мощные вычислительные ресурсы. |
| Обеспечивает высокую точность детекции. | Обучение и настройка моделей занимает много времени. |
| Может работать в реальном времени. | Проблема «черного ящика» — сложно понять, как именно модель принимает решение. |
Модели детекции объектов
Современные модели детекции объектов используют методы глубокого обучения, построенные на основе сверточных нейросетей (CNN). Они различаются по архитектуре, скорости работы и точности. Ниже мы рассмотрим наиболее популярные модели и их особенности.
Двухстадийные модели (Two-Stage Detectors)
Двухстадийные модели сначала находят участки изображения, где могут быть объекты, а потом определяют, что это за объекты, и уточняют их границы. Такие модели работают точно, но требуют много времени и вычислений.
R‑CNN (2014)
Как работает:
- Изображение анализируется с помощью метода Selective Search. Он выделяет на изображении регионы, в которых могут быть объекты (обычно около 2000).
- Каждый регион приводится к одинаковому размеру и проходит через нейросеть, чтобы извлечь признаки.
- Полученные признаки подаются в классификатор (например, SVM), который определяет класс объекта.
- Применяется линейная регрессия для уточнения координат ограничивающей рамки. Корректируются координаты углов или центра рамки, а также ее ширина и высота.
| Плюсы | Минусы |
|---|---|
| Высокая точность (относительно периода появления). | Низкая скорость работы алгоритма, так как каждый регион обрабатывается отдельно. |
| Подходит для точной локализации объектов. | Сложное и длительное обучение. |
Fast R‑CNN (2015)
Как работает:
- В отличие от R‑CNN, Fast R‑CNN обрабатывает все изображение сразу с помощью сверточной нейросети. Это дает общую карту признаков — своего рода сжатое представление изображения.
- Затем, в каждом регионе (полученного с помощью Selective Search или другого метода) из этой карты признаков извлекается соответствующая область.
- Используется ROI Pooling — специальный слой, который превращает каждый участок карты признаков в вектор фиксированного размера. Для этого область делится на равные части (например, 7×7), и из каждой части выбирается максимальное значение. Это позволяет обрабатывать регионы разного размера одинаково.
- Полученный вектор признаков подается в полносвязные слои, которые определяют класс объекта и уточняют координаты рамки.
| Плюсы | Минусы |
|---|---|
| Быстрее, чем R‑CNN. | Не подходит для быстрой работы в реальном времени. |
| Использует всю информацию изображения для обучения. | Производительность сильно зависит от качества данных. |
Faster R‑CNN (2016)
Как работает:
- В отличие от предыдущих моделей, Faster R‑CNN сам находит, где искать объекты. Вместо медленного Selective Search здесь используется Region Proposal Network (RPN) — отдельная сверточная сеть, которая работает вместе с основной.
- RPN получает карту признаков (общее представление изображения) и предсказывает, в каких местах могут находиться объекты. Она использует набор заранее заданных рамок — anchor boxes — разных размеров и форм, которые размещаются по всему изображению.
- Выходы RPN (предложения регионов) затем подаются в ROI Pooling и далее в полносвязные слои для классификации и уточнения координат bounding box, как в Fast R‑CNN.
| Плюсы | Минусы |
|---|---|
| Высокая точность распознавания. | Требует мощного оборудования для работы. |
| Быстрее, чем Fast R‑CNN. | Сложнее реализовать, чем одностадийные модели. |
Mask R‑CNN (2017)
Как работает:
- Mask R‑CNN — это улучшенная версия Faster R‑CNN. К ней добавлена параллельная ветвь для предсказания сегментационной маски для каждого объекта.
- Для этого используется модифицированный слой ROI Pooling, называемый ROIAlign, который точнее совмещает признаки с изображением.
| Плюсы | Минусы |
|---|---|
| Высокая точность распознавания. | Более требовательна к ресурсам, чем Faster R‑CNN. |
| Объединяет детекцию объектов и сегментацию. | Сложнее в реализации и настройке. |
Одностадийные модели (Single-Stage Detectors)
В отличие от двухстадийных, одностадийные модели сразу определяют, где находится объект и его класс — без промежуточного поиска регионов. За счет этого они работают намного быстрее и подходят для задач в реальном времени.
YOLO (2016)
Как работает:
- YOLO делит изображение на сетку (например, 7×7 ячеек).
- В каждой ячейке модель предсказывает несколько ограничивающих рамок, вероятность того, что рамка содержит объект (objectness score), и вероятности принадлежности объекта к разным классам при условии, что центр объекта находится в этой ячейке.
- Для каждой рамки модель предсказывает координаты ее центра, ширину, высоту, а также оценку confidence score — произведение вероятности наличия объекта в рамке и IoU (Intersection over Union) между предсказанной рамкой и реальной.
| Плюсы | Минусы |
|---|---|
| Высокая скорость. | Чуть менее точная работа, чем у двухстадийных моделей. |
| Подходит для работы в реальном времени. | Хуже находит небольшие объекты. |
SSD (2016)
Как работает:
- Вместо сетки, как в YOLO, использует многоуровневую обработку изображения, чтобы лучше находить объекты разного размера.
- SSD использует несколько сверточных слоев с разным разрешением (feature maps) для предсказания bounding boxes и классов объектов. Каждый слой отвечает за обнаружение объектов определенного масштаба: более ранние слои (с большим разрешением) — за мелкие объекты, более поздние (с меньшим разрешением) — за крупные.
- На каждом уровне применяются anchor boxes — заранее заданные рамки разных форм и размеров.
- Для каждого anchor box сеть предсказывает: координаты объекта, его класс, вероятность наличия объекта.
| Плюсы | Минусы |
|---|---|
| Оптимальный баланс между скоростью и точностью. | Уступает Faster R‑CNN в сложных сценах. |
| Лучше справляется с небольшими объектами, чем YOLO. | Может ошибаться при сильном перекрытии объектов. |
RetinaNet (2017)
Как работает:
- RetinaNet использует архитектуру Feature Pyramid Network (FPN) для обнаружения объектов разных масштабов, подобно SSD.
- Вводит Focal Loss — функцию потерь. Это позволяет модели фокусироваться на сложных объектах и бороться с проблемой дисбаланса классов (когда объектов одного класса, например, фона, намного больше, чем других).
| Плюсы | Минусы |
| Высокая точность, сопоставимая с Faster R‑CNN. | Требует больше ресурсов, чем YOLO и SSD. |
| Лучше справляется с редкими и небольшими объектами. | Медленнее в сравнении с другими одностадийными моделями. |
В последние годы все большую популярность набирают модели, основанные на архитектуре Transformer, изначально разработанной для обработки естественного языка.
DEtection TRansformer (DETR) — одна из таких моделей, которая использует Transformer для предсказания bounding boxes и классов объектов без использования anchor boxes. DETR показывает конкурентоспособную точность и имеет потенциал для дальнейшего развития.
Выбор модели: какая лучше?
- Если нужна высокая точность — Faster R‑CNN.
- Если важна скорость — YOLO.
- Если важны небольшие объекты — RetinaNet.
- Если нужно совмещать сегментацию и детекцию — Mask R‑CNN.
Роль данных в обучении моделей детекции объектов
Качество работы алгоритмов детекции напрямую зависит от данных, на которых они обучаются. Недостаток или плохое качество данных приводит к снижению точности детекции, ошибкам в предсказаниях и ухудшению работы модели в реальных условиях.
Разметка данных
Для обучения моделей детекции используются большие наборы размеченных изображений.
Разметка — это процесс присвоения объектам определенных меток. В детекции чаще всего используются ограничивающие рамки (bounding boxes), но в зависимости от задачи также применяются маски сегментации, ключевые точки и скелетные аннотации.
Методы разметки
| Ручная разметка | Данные размечаются вручную с использованием специализированных инструментов. |
| Автоматическая разметка | Разметка выполняется с помощью автоматических алгоритмов без участия человека. |
| Полуавтоматическая разметка | Сочетает автоматическую разметку с последующей проверкой и корректировкой человеком. |
Инструменты для разметки
Для разметки применяются различные специализированные платформы:
- LabelImg — простое open-source решение для ручной разметки bounding boxes.
- CVAT (Computer Vision Annotation Tool) — мощный инструмент для разметки изображений и видео с возможностью командной работы.
- LabelMe — удобный инструмент для разметки и выгрузки данных в JSON-формате.
- Supervisely, V7, Scale AI — коммерческие платформы с автоматизацией процесса разметки и расширенным функционалом.
Открытые датасеты для детекции
Собирать и размечать изображения вручную — это долго и дорого, особенно для больших проектов. Чтобы сэкономить время и ресурсы, разработчики часто используют открытые датасеты — уже готовые наборы изображений с разметкой.
Несколько примеров:
- Open Images Dataset — один из крупнейших: более 9 миллионов изображений и аннотации для тысяч объектов.
- Pascal VOC — небольшой, но удобный датасет: около 11 тысяч изображений и 20 категорий объектов.
- ImageNet — содержит более 14 миллионов изображений и 20 тысяч категорий объектов. Чаще используется для классификации, но также применяется для предобучения моделей детекции.
Однако для специализированных задач (например, медицинских проектов) часто приходится собирать собственные датасеты, так как в открытом доступе нужных данных может не быть.
Качество данных
Даже самая мощная модель не сможет работать эффективно, если обучать ее на низкокачественных данных. В этом отношении критически важны:
- Точность разметки — ошибки в координатах bounding boxes или метках классов ухудшают обучение.
- Разнообразие данных — модель должна уметь работать в разных условиях: при изменении освещения, углов съемки, частичном перекрытии объектов, а также в присутствии шума, артефактов сжатия и других искажений.
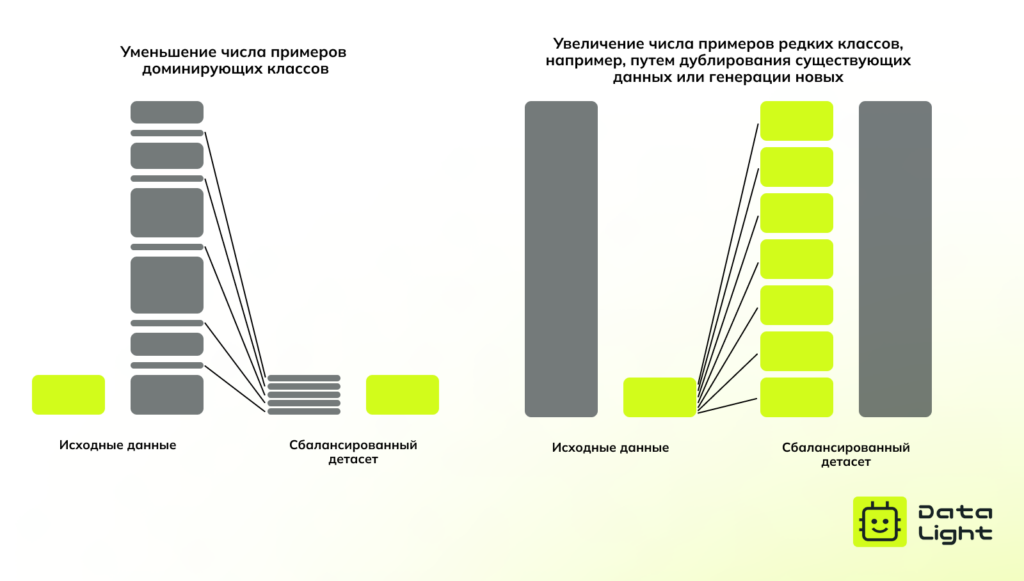
- Баланс классов — если в обучающем наборе одни классы объектов встречаются значительно чаще других, модель может переобучиться и ошибочно смещать предсказания в пользу доминирующих классов.
Методы улучшения данных
Чтобы повысить качество обучения и обобщающую способность модели, используются следующие методы: Oversampling и undersampling — методы балансировки классов в обучающем наборе.
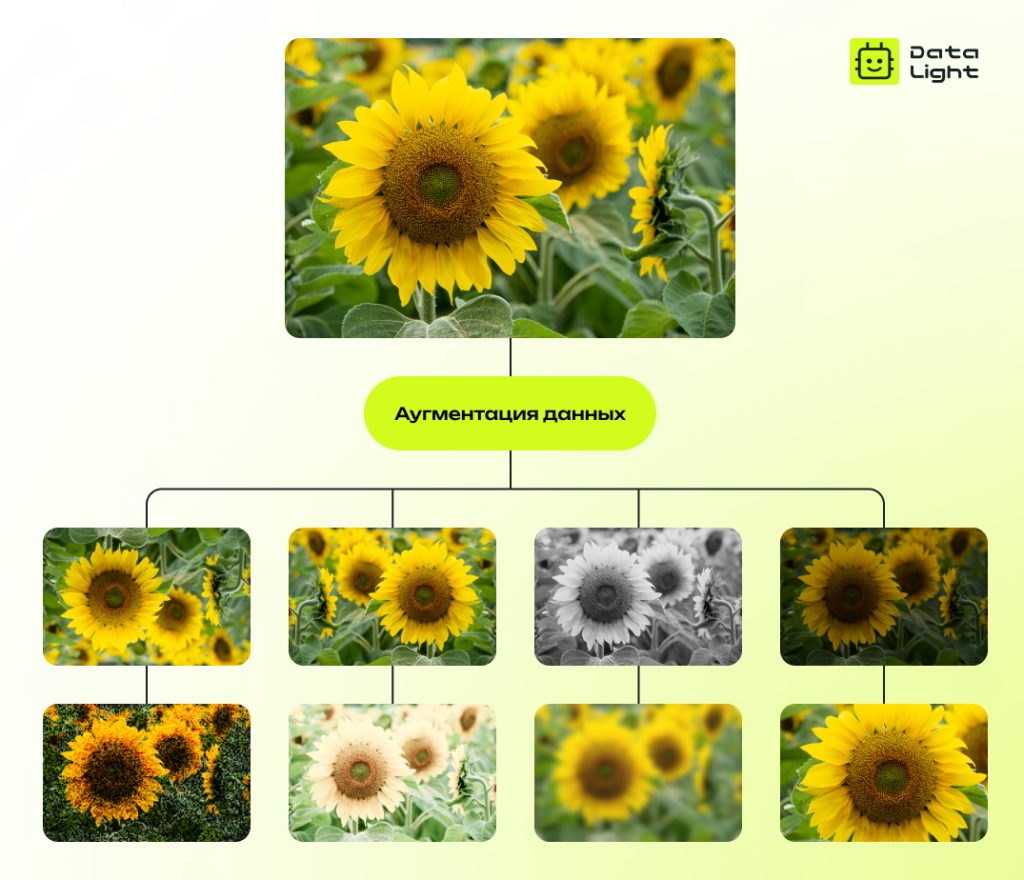
Аугментация данных — искусственное увеличение количества данных за счет различных трансформаций исходных изображений: поворотов, изменения яркости, наложения шума, масштабирования, кадрирования, изменения цветовой гаммы, отражений. Аугментация помогает модели стать более устойчивой к различным вариациям объектов и условий съемки.
Синтетические данные — создание искусственных изображений с помощью рендеринга или генеративных моделей, когда реальных данных недостаточно или их сбор затруднен. Важно, чтобы синтетические изображения были реалистичными и не вызывали смещения распределения данных (domain gap).
Ключевые выводы
Детекция объектов — это важнейшая технология в арсенале компьютерного зрения. Она помогает не просто распознавать, но и точно находить объекты на изображении. Такие системы используются в медицине, транспорте, безопасности и других сферах.
Современные модели основаны на нейросетях и хорошо справляются даже со сложными изображениями. Однако даже самые продвинутые алгоритмы не могут обойтись без качественных данных — именно данные (их разнообразие, точность и разметка) во многом определяют успех проекта.