 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыМашинное обучение (ML) сильно изменило то, как мы анализируем данные, строим прогнозы и автоматизируем рутинные задачи. Когда вы общаетесь с чат-ботом, получаете персональные рекомендации в интернете или видите, как мгновенно проверяются банковские транзакции, — все это результат работы машинного обучения.

Одна из самых интересных его сфер, которая часто остается в тени, — это обучение без учителя (Unsupervised Learning).
Представьте себе детектива, который расследует дело без четких улик. Он внимательно изучает картину произошедшего, ищет закономерности и связи. Так же работает обучение без учителя: алгоритмы самостоятельно находят скрытые структуры в данных, не зная заранее, что именно искать.
Что такое обучение без учителя?
Обучение без учителя — это подход в машинном обучении, при котором алгоритмы работают с неразмеченными данными. Если вы слышали об обучении с учителем, то знаете, что в таких задачах данные имеют четкие метки (например, «спам» и «не спам»). В противоположность этому при обучении без учителя система не получает прямых указаний.
Это как разница между «Вот пример с ответом — учись!» и «Вот данные — попробуй сам найти в них закономерности».
Самостоятельный поиск закономерностей
Предположим, вы оказались в незнакомом городе. У вас нет ни навигатора, ни путеводителя — вы просто гуляете по улицам, рассматриваете витрины, людей, архитектуру. Вы начинаете замечать: вот район с кафе и уличными музыкантами, а здесь — с офисами и деловыми людьми. Постепенно город делится на части на основе личных наблюдений, без подсказок и схем.
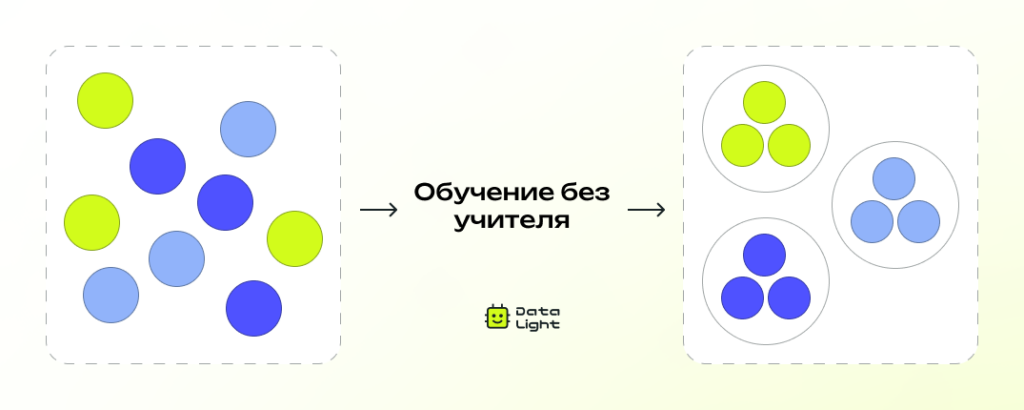
Примерно так же работает обучение без учителя: алгоритм сам изучает данные и находит в них скрытые закономерности — например, группы похожих объектов или необычные связи между ними.
Нет правильных и неправильных меток
В обучении без учителя нет готовых ответов — никто заранее не сказал, к какому классу относится каждый пример. Поэтому алгоритм сам решает, как лучше сгруппировать или организовать данные.
Оценить результат можно только по тому, насколько он полезен. Например, если модель разделила клиентов на группы, и каждая группа покупает разные товары — это уже важное открытие. Даже если таких групп никто раньше не выделял, теперь вы можете использовать их для анализа.
Разные методы — один принцип
Обучение без учителя включает такие методы, как кластеризация (k‑средних, DBSCAN, иерархическая кластеризация), снижение размерности (PCA, t‑SNE, автоэнкодеры), оценка плотности распределения и многое другое.
У каждого метода свои задачи, но их объединяет один принцип: «Нет меток? Не проблема!»
Пример: сортировка фото
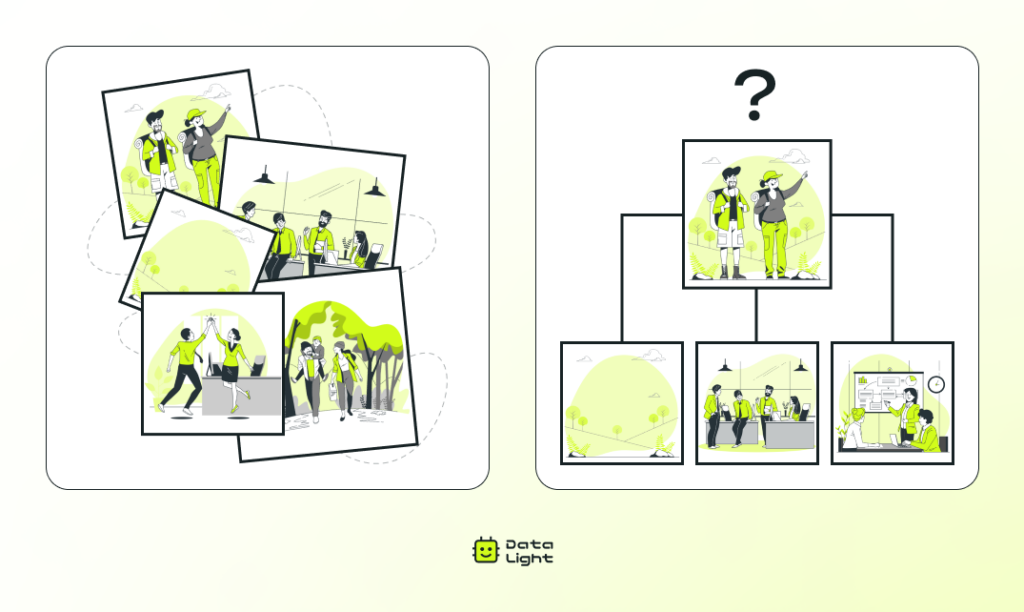
Допустим, у вас есть папка с сотнями фотографий: отпуск, семья, работа, встречи с друзьями, природа — все вперемешку, и ни одна не подписана.
Вы хотите отсортировать их. Вот снимки с пейзажами — отправляете их в папку «Природа». Вот фото с друзьями на вечеринках или в кафе — идут в «Друзья». А вот рабочие моменты: документы, презентации, офис — это «Работа».
Но встречаются и спорные кадры: например, фото с коллегами на природе. Куда их отнести? Четкой границы нет.
В итоге вы создаете свою собственную систему папок, не зная заранее, какие именно категории появятся.
Как работает обучение без учителя?
Чтобы разобраться, давайте разложим процесс по шагам:
Сбор и предварительная обработка данных
Обучение без учителя начинается с необработанных данных — например, с большого CSV-файла или базы данных.
Первый шаг — предобработка. Нужно удалить дубликаты, заполнить пропущенные значения и привести числовые признаки к одному масштабу, например, с помощью нормализации.
Поскольку в данных нет меток, которые подсказывали бы, что важно, особое внимание уделяется выбору и созданию признаков (feature engineering). Именно они помогают алгоритму «заметить» скрытые закономерности и выделить полезную информацию.
Выявление структуры
Алгоритмы обучения без учителя ищут скрытую структуру в данных. Например, метод k‑средних (K‑means) шаг за шагом группирует похожие объекты в группы — кластеры — ориентируясь на расстояние между ними (по схожести значений признаков).
Другой пример — PCA (анализ главных компонент). Он помогает сократить количество признаков, выделяя основные направления, по которым данные различаются.
Главная идея: данные сами подсказывают, какие в них есть закономерности. Алгоритм просто помогает их обнаружить.
Оценка результатов
В отличие от обучения с учителем здесь нельзя просто сравнить ответы модели с правильными метками — их ведь изначально нет. Поэтому классические метрики здесь не работают.
Вместо этого используют другие подходы. Например:
- Silhouette Score — показывает, насколько хорошо объекты внутри одного кластера похожи друг на друга и насколько они отличаются от объектов в других кластерах. Чем выше значение, тем лучше модель разделила данные на группы.
- Reconstruction Error — применяется для автоэнкодеров и показывает, насколько точно модель может восстановить входные данные из сжатого представления.
Но самая надежная оценка — это польза на практике. Иногда только эксперт в предметной области может сказать, действительно ли найденный алгоритмом паттерн важен для реального применения.
Итеративное улучшение
Так же как язык со временем меняется — появляются новые слова и выражения — так и данные со временем могут обновляться. Поэтому стоит периодически переобучать или перенастраивать модель, чтобы она оставалась актуальной.
Практические советы
Масштабирование признаков
Многие алгоритмы, основанные на расстояниях (например, K‑means), чувствительны к масштабу данных. Чтобы избежать искажений, стоит использовать масштабирование — например, StandardScaler или MinMaxScaler.
Выбор количества кластеров
- Elbow Method (метод локтя) — помогает определить оптимальное число кластеров, анализируя, как меняется внутренняя сумма квадратов отклонений (WCSS — Within-Cluster Sum of Squares) при разном количестве кластеров.
- Silhouette Score — оценивает, насколько хорошо каждый объект вписывается в свой кластер.
- Gap Statistic — сравнивает качество кластеризации на ваших данных с результатами на случайных (референсных) данных. Это более строгий способ оценки.
Работа с большими датасетами
Если данных очень много, используйте более легкие версии алгоритмов, например, MiniBatchKMeans. Он обрабатывает данные по частям и дает хорошие результаты при меньших затратах.
Снижение размерности перед кластеризацией
Для данных с большим числом признаков полезно сначала сократить размерность — например, с помощью PCA или автоэнкодеров. Это ускоряет расчеты и может улучшить качество кластеризации.
Подходы к обучению без учителя
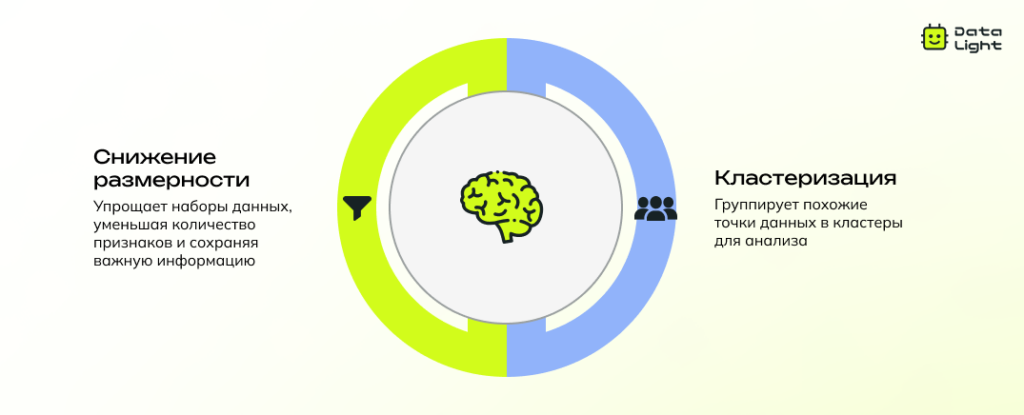
Снижение размерности
Метод главных компонент (PCA)
PCA — это способ упростить данные, оставив в них только самое важное. Он ищет направления, по которым значения в данных меняются сильнее всего, так называемые главные компоненты, и проецирует информацию на эти направления.
Это один из базовых методов визуализации. Он позволяет сократить сотни признаков до двух или трех, чтобы можно было построить график и наглядно увидеть структуру данных.
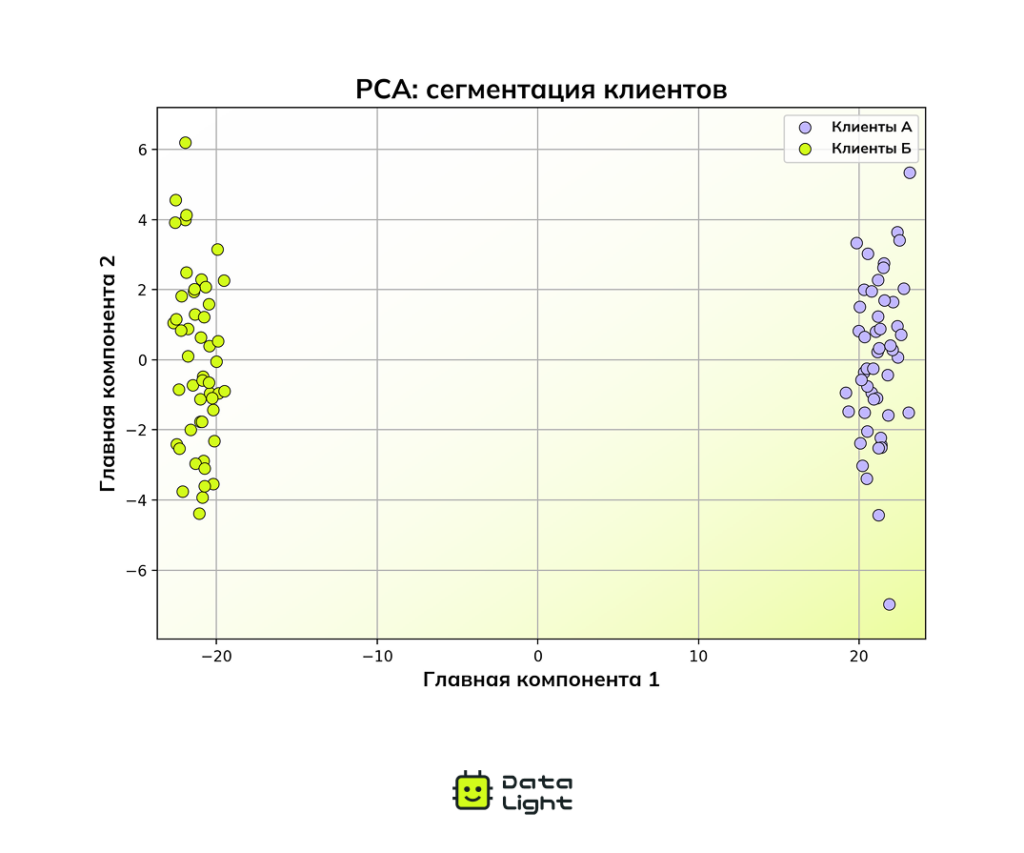
Например, вы собираете 200 разных показателей о поведении пользователей на сайте. С помощью PCA вы можете сжать эту информацию до 2 компонент и построить график, на котором четко видно, как пользователи делятся на разные группы.
t‑SNE и UMAP
Методы t‑SNE и UMAP помогают находить скрытые паттерны в данных с большим числом признаков. Они переводят такие данные в 2D- или 3D-пространство, чтобы можно было их визуализировать.
Особенность этих методов — они стараются сохранить «похожесть» объектов: если два объекта были похожи, они будут рядом и на графике.
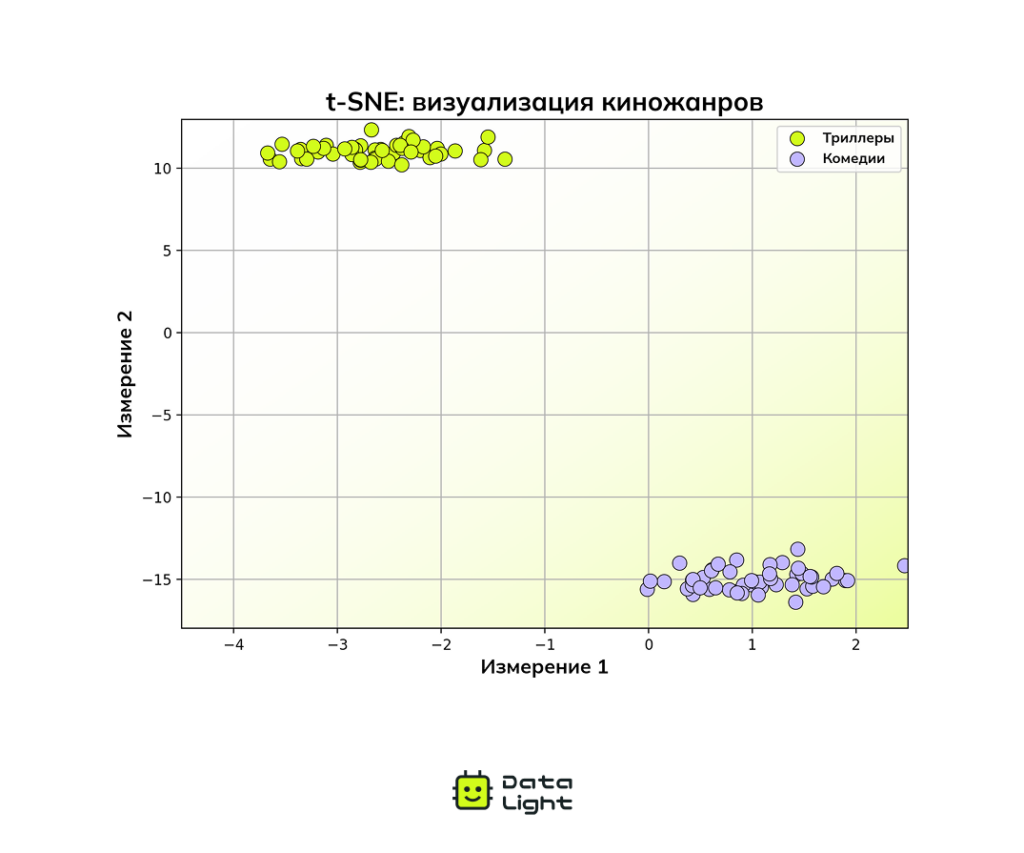
Представьте, что у вас есть 100 фильмов, каждый из которых описан с помощью 200 признаков. Среди них — комедии и триллеры.
С помощью метода t‑SNE вы можете уменьшить эти 200 признаков до 2 и построить график. Визуально становится понятно, что фильмы делятся на кластеры — каждый соответствует своему типу.
Автоэнкодеры (Autoencoders)
Автоэнкодер — это специальная нейросеть, которая учится сначала сжимать данные, а потом восстанавливать их обратно. При этом она сохраняет в сжатом виде самую важную информацию. Такой подход помогает находить скрытые закономерности и часто используется для поиска аномалий.
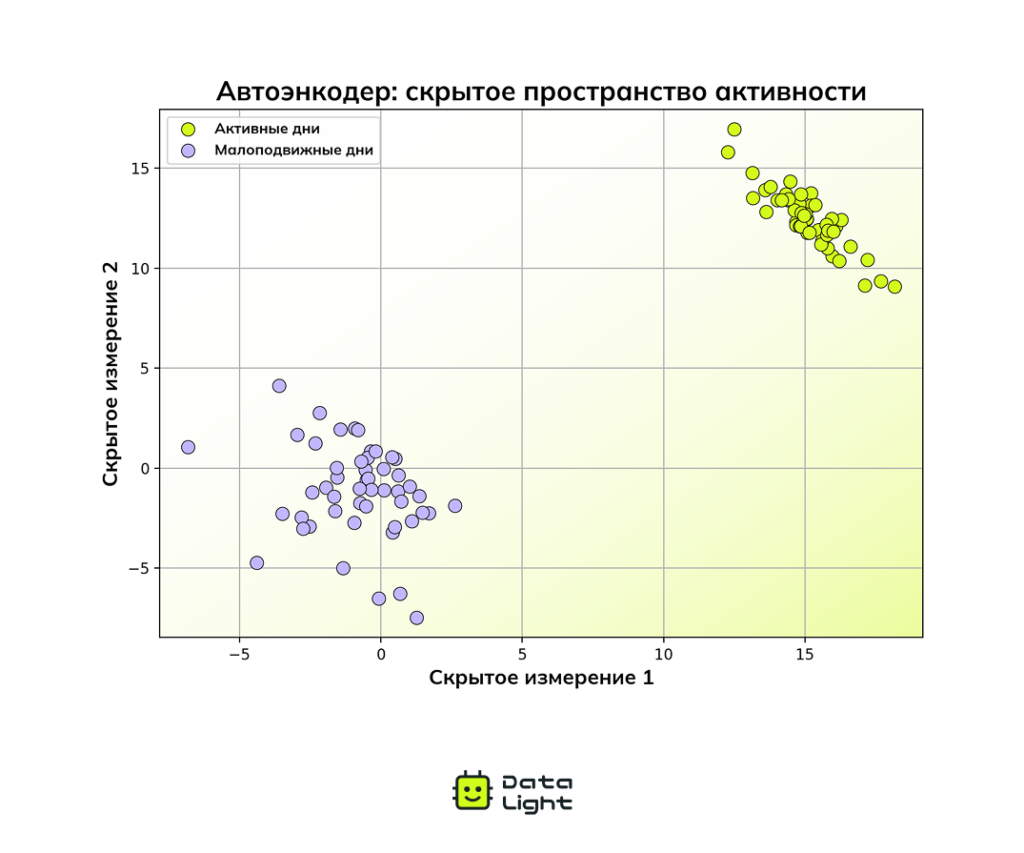
Представьте, что вы отслеживаете свое состояние с помощью фитнес-браслета, который фиксирует 200 показателей каждый день. В активные дни значения выше, а в спокойные — ближе к базовому уровню.
Автоэнкодер сжимает все эти измерения в двумерное латентное пространство, где два типа дней четко разделяются.
Примечание:
Подходы можно комбинировать. Например, сначала можно применить PCA для снижения размерности, а затем выполнить кластеризацию — это ускорит вычисления и поможет алгоритму точнее выделить группы.
Кластеризация
Метод k‑средних (K‑means)
Один из самых простых и популярных методов кластеризации. Делит данные на k групп так, чтобы каждая точка оказалась ближе всего к своему центру (среднему значению). Этот метод достаточно простой, быстрый и хорошо работает, если у вас есть представление о том, сколько кластеров нужно выделить.
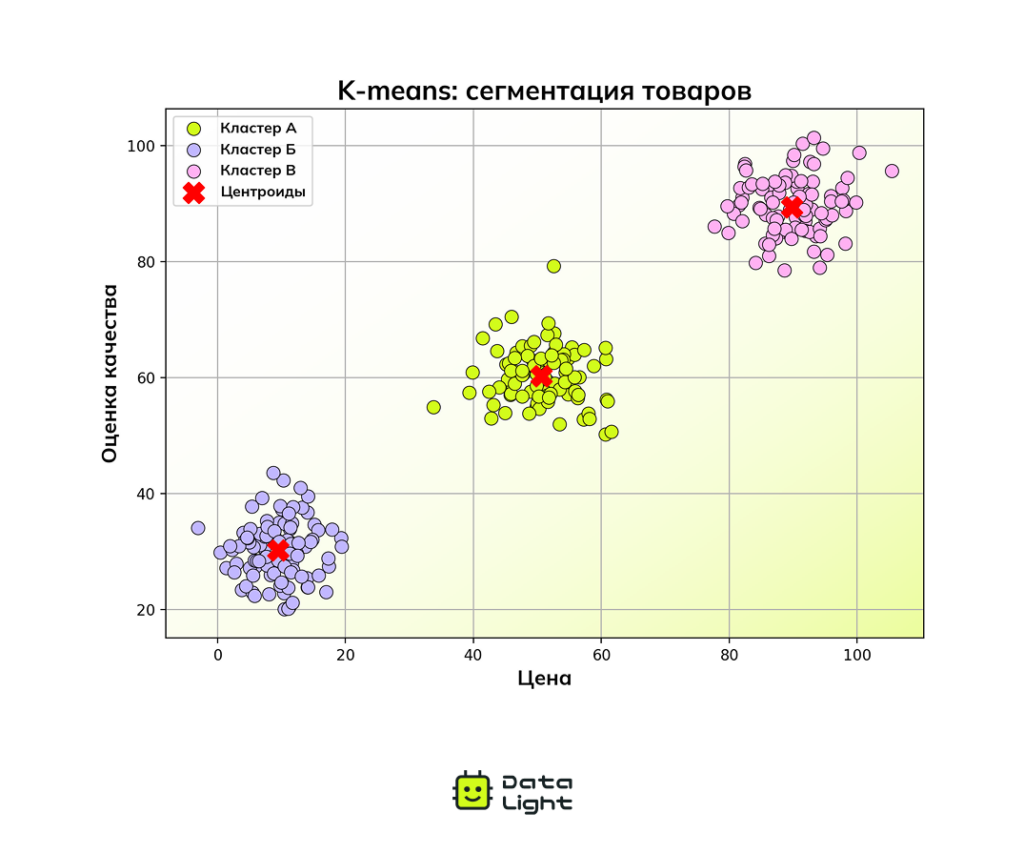
Представьте, что у вас есть список товаров, у каждого — своя цена и качество. Алгоритм K‑means автоматически разделит их на три группы: бюджетные, средние и премиум. Красные крестики показывают центроиды (средние значения) каждого кластера.
DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
Алгоритм DBSCAN объединяет близко расположенные точки в кластеры, а редкие точки считает шумом (выбросами). Этот метод удобен, когда кластеры нестандартны или нужно найти аномалии.
Представьте, что вы изучаете расположение магазинов в городе. DBSCAN сгруппирует те, что находятся в оживленных торговых районах, а отдельно стоящие отметит как выбросы.
Иерархическая кластеризация (Hierarchical Clustering)
Алгоритм Hierarchical Clustering строит дерево (дендрограмму), где объекты постепенно объединяются в группы. Вы сами решаете, на каком уровне «разрезать» дерево, чтобы получить нужное количество кластеров. Хорошо подходит для задач, где важна наглядность.
Представьте, что вы исследуете данные о генной экспрессии, чтобы определить, какие гены работают схожим образом. Иерархическая кластеризация группирует гены в дерево, показывая их взаимосвязь.
Математические основы
Для тех, кто хочет углубиться в технические детали:
Формула K‑means
Алгоритм K‑means минимизирует сумму квадратов расстояний точек до центроидов своих кластеров (WCSS):
$$ \text{WCSS} = \sum_{i=1}^{k} \sum_{\mathbf{x} \in C_i} \|\mathbf{x} — \boldsymbol{\mu}_i\|^2 $$где:
- 𝜿 — число кластеров,
- $\mathbf{C}_i$ — множество точек в кластере 𝒾,
- $\mathbf{\mu}_i$ — центр (среднее) кластера 𝒾,
- $||\mathbf{x} — {\mu}_i||^2$ — евклидово расстояние между точкой x и центроидом $\mathbf{\mu}_i$.
Формула PCA
PCA выполняет разложение ковариационной матрицы данных на собственные векторы и собственные значения:
$$ \Sigma \mathbf{v} = \lambda \mathbf{v} $$
где:
- $\mathbf\Sigma$ — ковариационная матрица данных,
- 𝐯 — собственный вектор (главная компонента),
- $\mathbf\lambda$ — собственное значение (доля объясненной дисперсии).
PCA выбирает главные компоненты с наибольшими собственными значениями, чтобы сохранить максимальное количество информации.
Продвинутые методы в обучении без учителя
Современные тенденции в обучении без учителя включают:
Самообучение (Self-Supervised Learning)
Этот метод создает «псевдометки» из самих данных, приближая обучение без учителя к обучению с учителем.
Представьте, что вы собираете пазл, но некоторых деталей не хватает. Вместо того чтобы сдаться, вы представляете, что должно быть на их месте, опираясь на форму и рисунок соседних фрагментов. Аналогично и в самообучении: модель учится восстанавливать скрытую часть данных, используя остальную информацию.
Генеративные модели (Generative Models)
Генеративные модели — это алгоритмы, которые создают новые данные, похожие на реальные. К таким моделям относятся вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN).
Они умеют:
- Генерировать изображения, тексты, аудио и другие типы данных.
- Находить аномалии — объекты, не соответствующие привычной структуре данных.

Как это работает:
Представьте художника, который может создавать картины в стиле великих мастеров. Он настолько хорошо уловил их приемы, что его работы неотличимы от оригиналов.
- VAE — художник, который придумал простой рецепт картины: он сжимает важные детали в короткий код, а потом может создавать на его основе новые, похожие изображения.
- GAN — творческий дуэт. Один «рисует» изображения (генератор), а другой — «оценивает» (дискриминатор). Первый пытается обмануть второго, создавая все более реалистичные изображения. Когда критик уже не отличает подделку от оригинала — задача выполнена.
Инструменты и библиотеки для обучения без учителя
- Scikit-Learn — популярная Python-библиотека с множеством встроенных алгоритмов для кластеризации (K‑means, DBSCAN) и снижения размерности (PCA, t‑SNE). Проста в использовании и хорошо документирована, подходит для большинства базовых задач.
- TensorFlow и PyTorch — современные фреймворки для построения нейросетей. В TensorFlow, например, есть подробное руководство по созданию автоэнкодеров — хороший способ освоить нейросетевые подходы к обучению без учителя на практике.
- Spark MLlib — библиотека для машинного обучения, позволяющая применять методы кластеризации и снижения размерности на больших объемах данных. Эффективна в распределенных вычислениях и работе с Big Data.
Сравнение подходов к обучению
Чтобы лучше разобраться в обучении без учителя, полезно сравнить его с другими типами машинного обучения:
| Критерий | Обучение без учителя | Обучение с учителем | Обучение с частичным привлечением учителя |
|---|---|---|---|
| Наличие разметки | Разметка отсутствует | Все данные размечены (есть входные признаки и целевая переменная) | Частично размеченные данные (небольшой размеченный набор + большой неразмеченный) |
| Цель обучения | Выявить скрытые структуры в данных (кластеры, паттерны, связи) | Построить модель, способную предсказывать целевые значения | Повысить точность моделей, комбинируя размеченные и неразмеченные данные |
| Основные сложности | Отсутствие объективных метрик качества, сложность интерпретации | Необходимость ручной разметки | Баланс между размеченными и неразмеченными данными, чувствительность к ошибкам в метках |
Сложности обучения без учителя
Поскольку обучение без учителя нацелено на поиск неизвестных структур, здесь возникают особые сложности:
Отсутствие эталона для проверки
Когда нет меток, трудно сказать: «Да, это правильно» или «Нет, это ошибка». Оценка качества выявленных закономерностей может быть субъективной. Приходится использовать косвенные метрики, например, Silhouette Score. Но в итоге часто все решает эксперт: только он может сказать, полезен ли найденный результат в реальности.
Выбор числа кластеров или компонент
Многие алгоритмы требуют заранее определить подход к работе. Например, в K‑means необходимо выбрать число k, а в PCA — количество главных компонент. Подходы вроде Elbow Method или Gap Statistic могут направить вас, но универсального правила для всех случаев нет.
Интерпретируемость результатов
Даже если алгоритм нашел математически корректные кластеры или признаки, не всегда очевидно, имеют ли они смысл с практической точки зрения. Особенно сложно интерпретировать результаты сложных нейросетевых моделей, таких как автоэнкодеры.
Вычислительная сложность
Некоторые методы (иерархическая кластеризация или t‑SNE) требуют значительных вычислительных ресурсов при работе с большими данными. В таких случаях может понадобиться специализированное оборудование.
Мифы об обучении без учителя
Неверные представления могут мешать объективно оценивать возможности и результаты работы моделей. Ниже — несколько распространенных заблуждений.

Миф №1: «Обучение без учителя — это только кластеризация»
Реальность: Кроме кластеризации, сюда также входят снижение размерности, поиск аномалий, а также генеративные модели и многое другое.
Миф №2: «Невозможно оценить результат модели без учителя»
Реальность: Хотя нет точных ответов и привычных метрик вроде Accuracy, все равно есть способы понять, насколько хорошо работает модель. Например, Silhouette Score показывает, насколько четко выделены кластеры.
Миф №3: «Обучение без учителя автоматически приносит пользу бизнесу»
Реальность: Сам по себе факт обнаружения кластеров или закономерностей не гарантирует практической ценности. Чтобы модель принесла пользу, результаты должны быть интерпретированы в контексте бизнес-задачи. Без этого даже корректные с математической точки зрения группы могут оказаться бесполезными для принятия решений.
Применение обучения без учителя в реальных задачах
От маркетинга до медицины и кибербезопасности — обучение без учителя применяется в самых разных сферах.
Сегментация клиентов
Компании используют алгоритмы кластеризации для группировки клиентов по поведенческим и демографическим признакам. Это позволяет создавать персонализированные предложения и повышать эффективность маркетинговых кампаний.
Обнаружение мошенничества
В банках и финтех-компаниях обучение без учителя применяется для обнаружения аномалий в транзакциях. Такие алгоритмы помогают выявлять подозрительную активность, включая новые схемы мошенничества.
Геномика и здравоохранение
Обучение без учителя помогает исследователям разбираться в сложных медицинских данных. Например, при анализе данных о генной экспрессии такие методы позволяют находить скрытые подтипы болезней.
Анализ изображений и медиа
Платформы для хранения и обработки медиафайлов используют обучение без учителя для группировки объектов по визуальному или тематическому сходству. Например, фотосервисы могут автоматически объединять снимки по лицам, сценам или событиям.
Рекомендательные системы
Многие рекомендательные системы используют обучение без учителя. Они объединяют товары и пользователей в группы по схожим признакам и находят, что может быть интересно конкретному человеку — даже если у него нет истории покупок.
Ключевые выводы
Обучение без учителя — важный подход в машинном обучении, который применяется, когда данные не размечены, а цель — понять, что в них происходит. Оно помогает обнаруживать скрытые взаимосвязи, группировать данные по сходству, выявлять аномалии и упрощать сложную информацию.
Несмотря на свою универсальность, обучение без учителя требует осторожного применения: интерпретация результатов может быть сложной, а оценка качества — зависеть от области применения. Чтобы получить практическую пользу, важно не просто правильно применять алгоритмы, но и учитывать контекст данных и цели анализа.