 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыПредставьте, что перед вами огромная стопка писем, среди которых есть срочные сообщения, рекламные предложения и личные. Если разбирать их вручную, это займет очень много времени. А теперь вообразите умного помощника, который мгновенно распределяет каждое письмо по категориям в зависимости от его содержания.
В цифровом мире такую задачу решает классификация текстов. Это интеллектуальный способ упорядочить большие объемы текстовой информации.
В этой статье мы разберемся, что такое классификация текстов, почему она так важна в эпоху больших данных и как начать применять ее на практике.

Что такое классификация текстов?
Классификация текстов — одна из задач в обработке естественного языка (NLP), которая основана на методах машинного и глубокого обучения. Её цель — автоматически определить, к какой категории относится тот или иной текст. Например, это может быть определение тематики статьи, типа сообщения или его эмоциональной окраски.
В отличие от простого поиска ключевых слов классификация позволяет компьютеру понимать контекст, намерения и даже эмоции. Эта технология применяется в поисковых и банковских системах, службах поддержки, социальных сетях и других областях, где нужно быстро обрабатывать большое количество информации.
Типы классификации текстов
Бинарная классификация
Это самый простой тип классификации, при котором каждый текст относится к одной из двух категорий. Например, система фильтрации электронной почты может автоматически определять, является ли письмо спамом или нет.
Мультиклассовая классификация
Мультиклассовая классификация используется в тех случаях, когда текст необходимо отнести не к двум, а к одной из нескольких категорий. Например, система может автоматически распределять статьи по темам: политика, спорт, экономика и культура.
Анализ тональности текста
Позволяет определить эмоциональный настрой текста: позитивный, негативный или нейтральный. Компании используют его для анализа отзывов, комментариев в соцсетях и обращений клиентов, чтобы лучше понимать отношение аудитории к продуктам и услугам.

Обнаружение токсичности
Этот тип классификации близок к анализу тональности, но направлен на выявление агрессивного, оскорбительного или потенциально опасного контента. Особенно актуально такое решение для онлайн-платформ, где важно оперативно реагировать на нарушения со стороны пользователей.
Распознавание намерений
Технология, которая помогает понять, что именно хочет пользователь. Благодаря ей чат-боты и виртуальные помощники способны правильно реагировать на запросы, например, включать музыку или сообщать погоду.
Определение языка текста
Действует как встроенный помощник: позволяет приложению выбрать подходящий язык интерфейса, предложить перевод или направить сообщение нужному специалисту службы поддержки.
Классификация вопросов
Помогает поисковым системам и виртуальным ассистентам определить тип вопроса и формат ожидаемого ответа. Например:
- «Кто построил Эйфелеву башню?» → имя.
- «Сколько длятся сутки на Марсе?» → число.
Распознавание именованных сущностей (Named Entity Recognition, NER)
Автоматически находит в тексте важные объекты: имена, организации, города, даты и присваивает им соответствующие категории. Такой метод широко применяется в поисковых системах, финансовом анализе и обработке юридических документов.
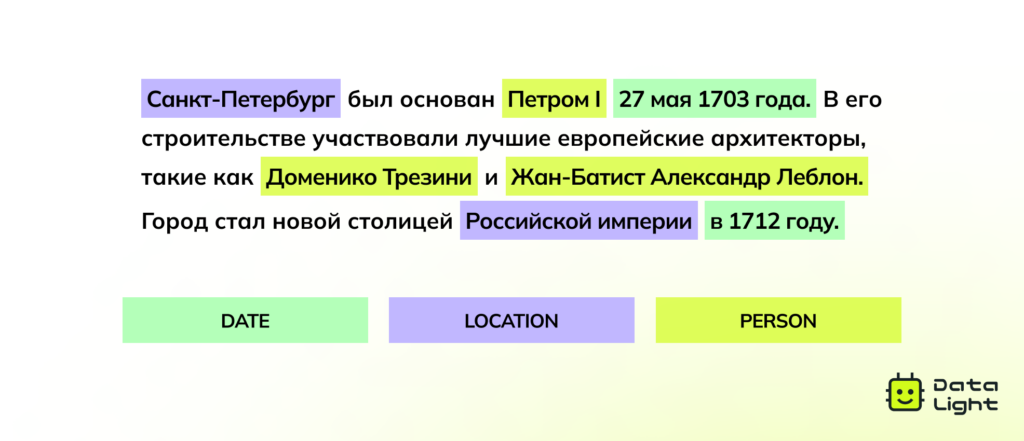
Зачем нужна классификация текстов: главные преимущества
Классификация текстов — это способ сделать работу с текстовой информацией быстрее, точнее и эффективнее.
Быстрый доступ к информации
Классификация работает как хорошо организованная библиотека: вместо беспорядка — четкая система. Документы, письма и сообщения автоматически сортируются, что облегчает рабочие процессы.
Принятие решений на основе данных
Как опытный следователь ищет улики, так и алгоритмы классификации помогают извлекать важную информацию. Например, компании используют анализ тональности, чтобы понимать, как клиенты воспринимают их продукт, а банки — для выявления мошенничества.
Повышение операционной эффективности
Автоматическая классификация упрощает рутинные задачи. Например, в службе поддержки вопросы клиентов могут автоматически перенаправляться в нужные отделы. Это экономит время и ресурсы.
Масштабируемый анализ текста
Системы на основе ИИ способны за секунды обрабатывать огромные объемы неструктурированного текста. Это позволяет находить закономерности, тренды и инсайты, которые сложно обнаружить вручную.
Где применяется классификация текстов?
Классификация текстов автоматизирует задачи, которые раньше требовали много времени и ручной работы. Рассмотрим, как ее применяют в разных сферах.
Бизнес и маркетинг
Компании ежедневно получают десятки, а то и сотни сообщений от клиентов: отзывы, комментарии, обращения в поддержку. Всё это — ценный, но неструктурированный поток информации. Классификация помогает быстро его обработать.
- Анализ тональности показывает, положительный, нейтральный или отрицательный отзыв оставил клиент.
Классификация отзывов по темам помогает понять, о чем именно пишет человек. Например, онлайн-магазин может автоматически разделять жалобы на качество товара и проблемы с доставкой, чтобы оперативно исправлять ошибки.

Кибербезопасность
Классификация текстов защищает пользователей от онлайн-угроз и мошенничества.
- Фильтрация спама — почтовые сервисы используют ИИ, чтобы блокировать миллионы вредоносных писем каждый день.
Определение мошенничества позволяет вовремя распознавать подозрительные сообщения и предотвращать финансовые потери.

Медицина
AI помогает врачам и исследователям разбираться в сложной медицинской информации.
- Классификация медицинских документов ускоряет доступ к нужной информации и помогает упростить работу больниц.
Диагностика по симптомам автоматически анализирует описания жалоб пациентов и предлагает возможные диагнозы.

Медиа и журналистика
Классификация текстов помогает медиа бороться с ложной информацией и упорядочивать материалы для читателей.
- Выявление фейковых новостей позволяет автоматически обнаруживать недостоверные материалы.
- Тематическая классификация новостей — статьи автоматически распределяются по рубрикам: политика, спорт, культура и т.д., облегчая читателям поиск нужного контента.

Право и юриспруденция
Юристы ежедневно работают с большим объемом документов: договорами, судебными решениями и нормативными актами. Классификация текстов помогает автоматизировать их обработку.
- Поиск важных условий в договорах: система автоматически выделяет ключевые пункты, обязательства сторон и юридические риски в соглашениях. AI-инструменты помогают замечать упущения и ошибки.
Проверка документов на соответствие законам: системы анализируют документы и помогают вовремя выявить возможные нарушения требований законодательства.

Подходы к классификации текстов
Существует несколько подходов к классификации текстов — от простых правил до передовых нейросетей. Каждый из них имеет свои сильные и слабые стороны и подходит для разных задач.
Правило-ориентированные методы
В таких системах тексты сортируются по заранее заданным правилам — например, по наличию определенных слов или выражений. Например, простой фильтр спама может помечать письма с фразами вроде «быстрая прибыль» или «срочно».
Главное преимущество метода — простота. Его легко настроить и быстро получить точные результаты в ограниченных задачах. Но такие системы требуют постоянных обновлений и плохо работают, если язык текста меняется — например, используются синонимы или другие формулировки.
Bag-of-Words, BoW
Модель Bag-of-Words (или «мешок слов») представляет текст в виде набора отдельных слов, не учитывая порядок и грамматику. Это один из базовых методов в классификации текстов, который часто применяют для задач вроде фильтрации спама или тематической сортировки сообщений.
Например, для BoW предложения «Кошка догнала собаку» и «Собака догнала кошку» будут одинаковыми, потому что содержат те же самые слова, несмотря на разный смысл.
Метод прост в реализации и хорошо подходит для базового анализа текстов. Однако у него есть недостатки: модель не понимает порядок слов и смысловую связь между ними.
TF-IDF: оценка важности слов
TF-IDF улучшает метод Bag-of-Words за счет того, что оценивает важность слов в тексте относительно всей коллекции документов. Эта модель широко используется в поисковых системах, при ранжировании документов и для выделения ключевых слов.
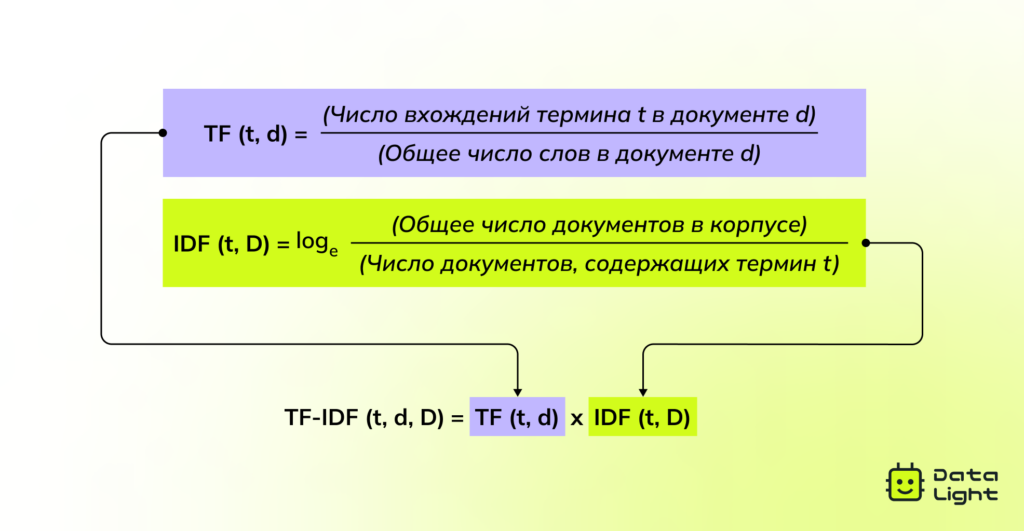
Суть TF-IDF в том, что оно снижает значение часто встречающихся слов (например, «и» или «это») и увеличивает вес слов, которые важны именно для конкретного текста. Например, в статье про изменение климата слово «углерод» будет иметь больший вес, чем распространенные слова вроде «есть» или «на».
TF-IDF помогает лучше находить важные термины и делает поиск информации более точным. Однако, как и Bag-of-Words, этот метод рассматривает слова отдельно и не учитывает контекст.
Машинное обучение
Методы машинного обучения используют статистические модели, которые учатся распознавать закономерности в текстах. Такие модели тренируются на размеченных данных и со временем могут улучшать свою точность.
Обучение с учителем
При обучении с учителем модель работает с заранее размеченными текстами, где для каждого примера известна правильная категория. Вот популярные алгоритмы:
- Naïve Bayes — вероятностная модель, основанная на частоте слов. Часто применяется для фильтрации спама.
- Random Forest — ансамбль деревьев решений. Используется для классификации тем текстов.
- Логистическая регрессия — статистическая модель для бинарной и многоклассовой классификации. Применяется, например, для сортировки отзывов клиентов.
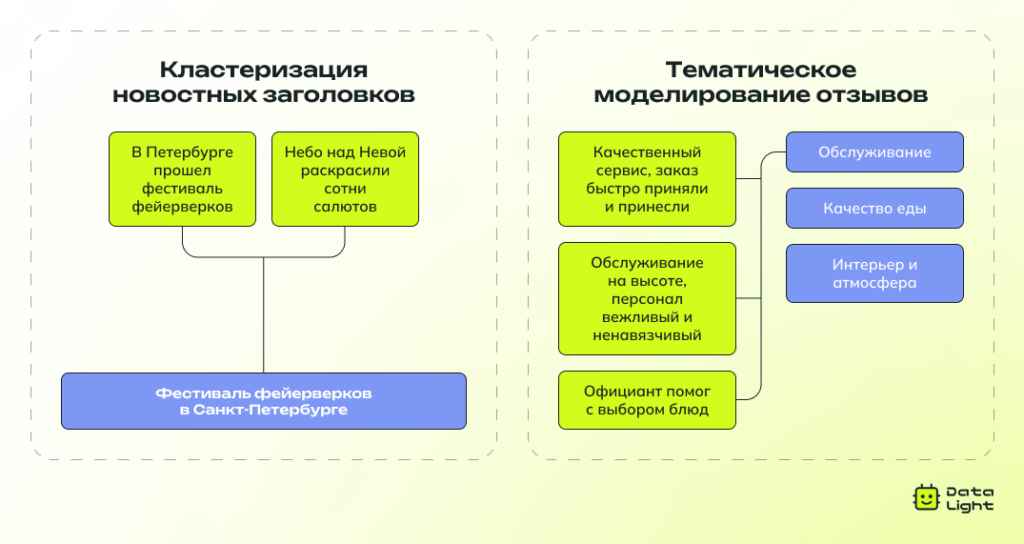
Обучение без учителя
Если размеченных данных нет или их мало, используют обучение без учителя. Здесь модели сами находят закономерности и группы в текстах, без заранее заданных категорий.
Самые популярные подходы:
- Кластеризация (например, K‑Means) — группировка похожих текстов на основе их содержания.
- Тематическое моделирование (например, LDA) — выявление скрытых тем в большом объеме текстов.
Обучение без учителя дает больше гибкости и подходит для работы с большими данными, но часто требует дополнительной настройки, чтобы результаты были действительно понятными и полезными.
Глубокое обучение
Глубокие нейросети умеют распознавать сложные закономерности в тексте и контекст слов. Они работают напрямую с «сырыми» данными, автоматически выделяя важные признаки.
- RNN и LSTM — умеют учитывать порядок слов, что особенно важно для задач вроде анализа тональности или диалогов в чат-ботах.
- CNN — хотя чаще применяются к изображениям, они хорошо справляются и с текстами, особенно короткими, выделяя важные словосочетания.
- Трансформеры (BERT, GPT, RoBERTa) — это самый современный и мощный подход. Такие модели анализируют весь текст целиком, понимают, как связаны слова, и учитывают контекст. Например, BERT помогает поисковикам лучше понимать запросы, а GPT — генерировать осмысленные и связные ответы.
Благодаря трансформерам точность классификации резко возросла. Например, обновление Google в 2019 году с использованием BERT значительно улучшило понимание естественного языка в поиске.
Сложности в классификации текстов
Несмотря на успехи в развитии алгоритмов, классификация текстов все еще сталкивается с рядом серьезных вызовов, которые могут повлиять на точность и надежность моделей.
Неструктурированные данные
В отличие от таблиц с четкими строками и столбцами, текст — это неструктурированная информация. Он может содержать орфографические ошибки, разную пунктуацию, нестандартные формулировки. Прежде чем такие данные можно будет анализировать, их нужно тщательно подготовить. В типичный набор этапов предобработки входят:
Токенизация — разбиение текста на слова или фразы.
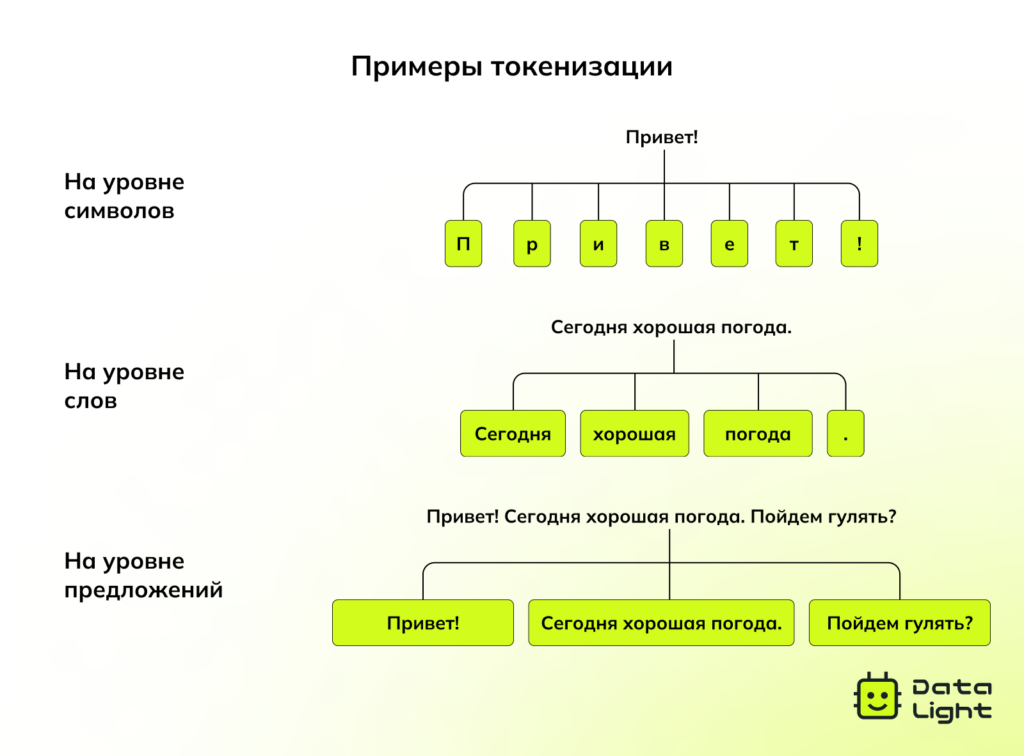
- Удаление стоп-слов — исключение часто встречающихся, но неинформативных слов вроде «и», «это», «на».
Стемминг и лемматизация — приведение слов к начальной форме: например, «бегущий» → «бежать».
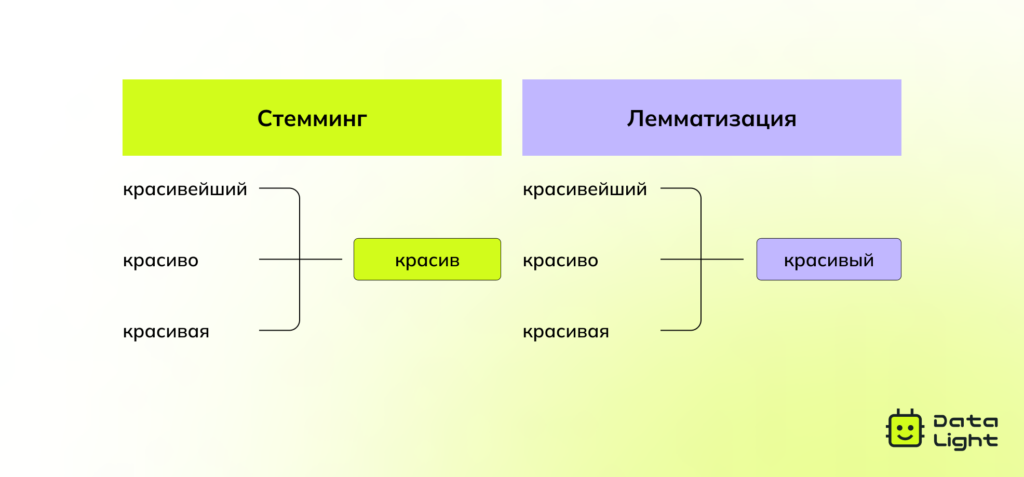
Без этих шагов модели могут запутаться в лишней информации и работать неточно.
Шум в данных
Тексты из реальной жизни — особенно в соцсетях и отзывах пользователей — полны опечаток, сокращений, сленга, эмодзи и нестандартных выражений. Такой «шум» затрудняет работу традиционных моделей. Чтобы справляться с этим, нужно настраивать мощный пайплайн предобработки, включая:
- Исправление ошибок — автоматическая коррекция опечаток.
- Нормализация текста — преобразование сленга и сокращений («u» → «you»).
- Распознавание сущностей — выделение имен, брендов и других важных терминов.
Дисбаланс классов
Иногда в обучающем наборе данных одни категории представлены гораздо больше, чем другие. В таких случаях модель начинает «предпочитать» большинство, игнорируя редкие, но важные случаи. Особенно критично это в задачах вроде выявления мошенничества, где подозрительные операции встречаются редко.
Многозначность языка
Многие слова имеют несколько значений. Например, «apple» может означать как фрукт, так и IT-компанию. Без контекста модель может неправильно интерпретировать такие слова. Современные модели, такие как BERT, лучше справляются с этим, но в сложных случаях все еще возможны ошибки.
Профессиональная терминология
Модель, обученная на обычных текстах, может плохо работать в узкоспециализированных областях — например, в медицине или юриспруденции. Там часто используются термины, аббревиатуры и специфический язык. Чтобы добиться высокой точности, такие модели нужно дообучать на специализированных данных.
Масштабируемость и производительность
Когда нужно обрабатывать огромные объемы текстов — как это делают, например, соцсети — важно обеспечить быструю работу модели. Иначе система может «тормозить» или требовать слишком много ресурсов. Для масштабирования используют:
- Эффективную индексацию — например, через Elasticsearch, чтобы быстро находить и классифицировать тексты.
- Параллельную обработку — с помощью Apache Spark и других систем распределенных вычислений.
- Оптимизацию моделей — методы вроде квантизации и дистилляции позволяют уменьшить размер моделей и ускорить работу без потери точности.
Без этих подходов текстовые классификаторы становятся узким местом — медленно работают и сильно нагружают систему.
Лучшие практики в классификации текстов
Сильная модель классификации — это не только «правильный алгоритм». Чтобы она действительно работала — и продолжала работать со временем — нужно уделить внимание трем важным вещам: качеству данных, регулярному обновлению модели и контролю за справедливостью ее решений.

Следите за чистотой и балансом данных
Модель учится на тех данных, которые ей даются. Если данные грязные, с дубликатами или перекосом в сторону одной категории, результат будет таким же неточным, как старый прогноз погоды.
Что нужно делать:
- Удаляйте дубликаты — нет смысла учиться на одном и том же.
- Фильтруйте шум — лишние, нерелевантные тексты только запутают модель.
- Балансируйте классы — если один тип данных сильно преобладает, модель начнет его «предугадывать» по умолчанию, игнорируя меньшинства.
Хорошие данные = хорошие результаты. Все просто.
Обновляйте модель — язык меняется
Язык постоянно развивается. Новые выражения, сленг, эмодзи, термины — все это может повлиять на то, как алгоритм понимает текст. Если не обновлять модель, она начнет ошибаться — например, воспринимать слово «огонь» только как пламя, а не как комплимент.
Что помогает:
- Переобучайте модель на новых данных, чтобы она оставалась актуальной.
- Используйте transfer learning — не начинайте обучение заново, а дообучайте уже готовую модель (например, BERT) под конкретную задачу. Это как дать модели «переключиться» на новые реалии, не стирая то, что она уже знает.
Убедитесь, что ваша модель не предвзята
Никто не хочет, чтобы ИИ принимал несправедливые решения — особенно если это влияет на людей: в анализе отзывов, приеме на работу или модерации контента. Но если в обучающих данных есть перекосы, модель может начать воспроизводить и усиливать их.
Что важно:
- Проверяйте данные на наличие предвзятости — может быть, какие-то слова или темы влияют на результат непропорционально.
- Делайте работу модели прозрачной — пользователи должны понимать, почему ИИ пришел к своему выводу.
Ключевые выводы
Классификация текстов — один из ключевых инструментов обработки естественного языка, который позволяет автоматически определять содержание, тему, тональность и другие характеристики текста. Она широко применяется в бизнесе, медицине, праве, кибербезопасности и других сферах, где важно быстро и точно анализировать большие объемы информации. Однако для её успешного применения важно учитывать качество и баланс данных и регулярно обновлять модели.