Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыPython — один из самых популярных языков для работы с данными, и он предлагает множество инструментов для загрузки и обработки датасетов. В этой статье мы разберем, как загружать данные из различных форматов: CSV, JSON, TXT, Excel и SQLite, используя стандартные средства Python и популярные библиотеки, такие как pandas, NumPy и другие.

Датасеты из наших примеров
Iris:
Red Wine Quality:
Загрузка данных из CSV
CSV (Comma-Separated Values) — это текстовый формат для хранения табличных данных. Каждая строка в таком файле — строка таблицы, где значения разделены запятыми. Этот формат популярен из-за своей простоты и универсальности.
Способ 1: С помощью стандартной библиотеки CSV
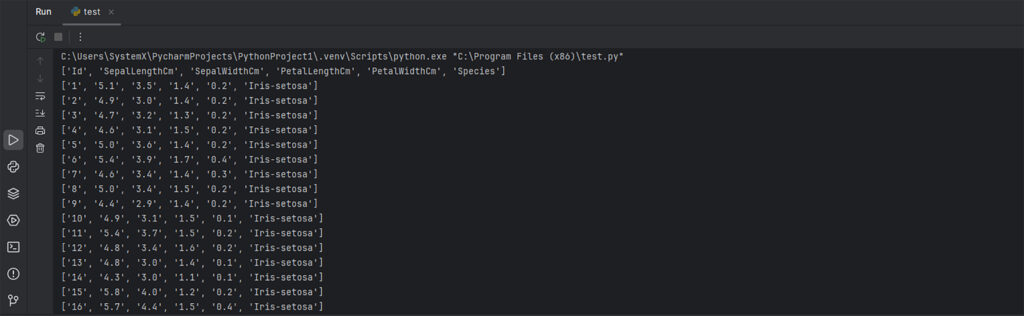
Python предоставляет встроенную библиотеку csv для чтения и записи CSV-файлов:
import csv # Импортируем стандартный модуль для работы с CSV
with open('iris.csv', 'r') as file: # Открываем файл
reader = csv.reader(file) # Создаем объект для чтения строк
for row in reader: # Перебираем строки
print(row) # Выводим каждую строку
Вывод:
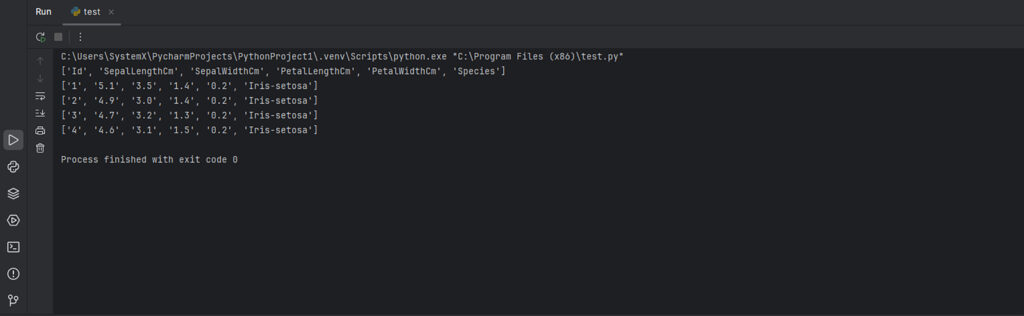
Если вам необходимо прочитать только первые несколько строк, измените код следующим образом:
import csv
with open('iris.csv', 'r') as file:
reader = csv.reader(file) # Создаем объект для построчного чтения
for i, row in enumerate(reader): # Перебираем строки с индексом
if i >= 5: # Останавливаем цикл после 5 строк
break
print(row) # Выводим первые пять строк
Вывод:
Способ 2: С помощью библиотеки pandas
Pandas — одна из самых мощных библиотек для анализа данных. Она позволяет удобно загружать, просматривать и обрабатывать таблицы.
Сначала импортируем библиотеку и загрузим весь датасет, а затем выведем его полностью:
import pandas as pd # Импортируем библиотеку pandas
df = pd.read_csv('iris.csv') # Загружаем CSV-файл в DataFrame
print(df) # Выводим DataFrame (по умолчанию вывод сокращен)
Вывод:
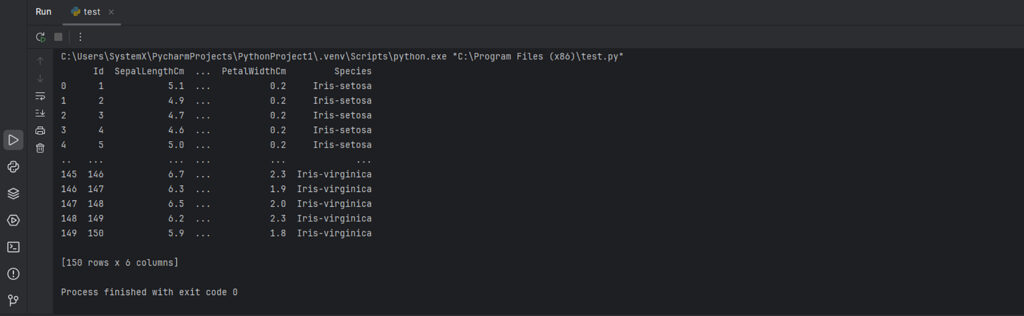
По умолчанию pandas сокращает вывод, если строк или столбцов слишком много. Чтобы отобразить все данные, замените последнюю строку на:
pd.set_option('display.max_rows', None) # Показывать все строки
pd.set_option('display.max_columns', None) # Показывать все столбцы
print(df) # Теперь весь DataFrame выведется полностью
Если датасет большой, выводить все строки бывает неудобно. В таких случаях лучше вывести только первые несколько строк, чтобы получить представление о данных, быстро оценить их структуру и проверить корректность загрузки.
import pandas as pd
df = pd.read_csv('iris.csv')
print(df.head(5)) # Выводим первые 5 строк
Способ 3: С помощью библиотеки NumPy
NumPy — это библиотека Python, предназначенная для эффективной работы с числовыми данными и многомерными массивами. Она подходит для выполнения математических операций, статистического анализа и машинного обучения.
Эта библиотека особенно удобна, когда ваш датасет состоит из числовых данных, а текстовая информация минимальна или отсутствует вовсе.
Пример 1: Загрузка датасета Red Wine Quality
Если ваш датасет состоит из чисел, загрузка с помощью NumPy выглядит так:
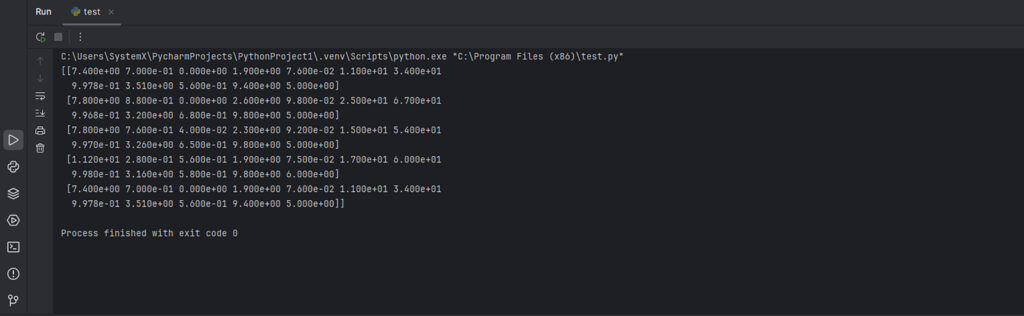
import numpy as np # Импортируем библиотеку NumPy
data = np.loadtxt('winequality-red.csv', delimiter=',', skiprows=1) # Загружаем датасет, пропуская первую строку (текстовые заголовки)
print(data[:5]) # Выводим первые 5 строк
Вывод:
Если вам необходимо вывести весь датасет (все строки) замените последнюю строчку на:
np.set_printoptions(threshold=np.inf) print(data)
Пример 2: Загрузка датасета Iris
Если же в датасете есть текстовые данные (например, названия классов в наборе данных Iris), стандартная загрузка приведет к ошибке. NumPy попытается превратить каждое значение в число. В этом случае используйте параметр dtype=‘str’:
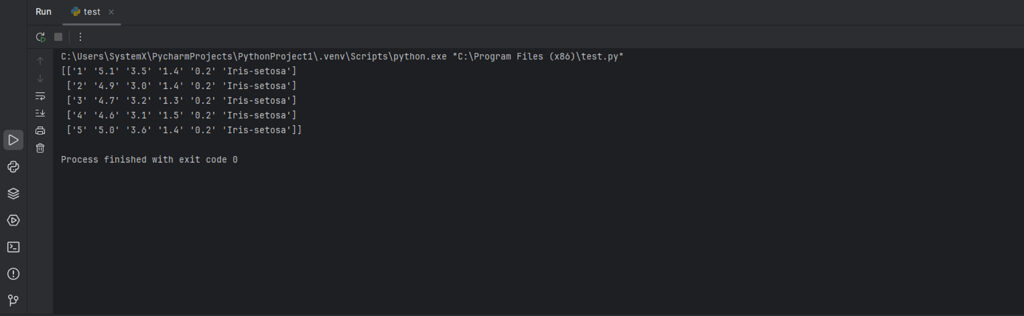
import numpy as np # Импортируем библиотеку NumPy
data = np.loadtxt('iris.csv', delimiter=',', skiprows=1, dtype='str') # Загружаем данные как строки
print(data[:5]) # Выводим первые 5 строк
Вывод:
В случае если вас интересуют только столбцы с числами, можно указать их номера через параметр usecols. Например, если текстовая информация содержится только в последнем столбце, а первые четыре содержат числа:
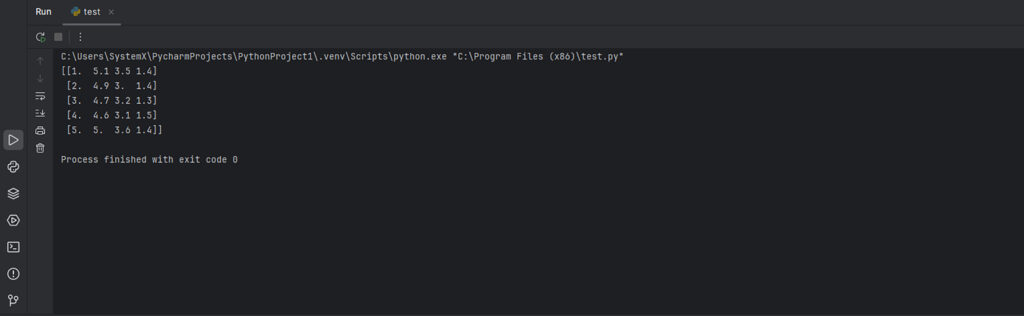
import numpy as np
data = np.loadtxt('iris.csv', delimiter=',', skiprows=1, usecols=(0, 1, 2, 3)) # Загружаем нужные столбцы (0-3)
print(data[:5]) # Выводим первые 5 строк
Вывод:
Загрузка данных из JSON
JSON — распространенный текстовый формат для обмена данными, особенно популярный в веб-разработке и работе с API. В отличие от CSV-файлов, которые имеют строгую табличную структуру и подходят для простых, однородных данных, JSON позволяет хранить более сложные, вложенные структуры данных (например, словари внутри списков).
Рассмотрим два способа загрузки JSON-файлов в Python: с помощью стандартной библиотеки Python и библиотеки pandas.
Способ 1: С помощью стандартной библиотеки Python
Встроенная библиотека json позволяет легко загружать и обрабатывать данные:
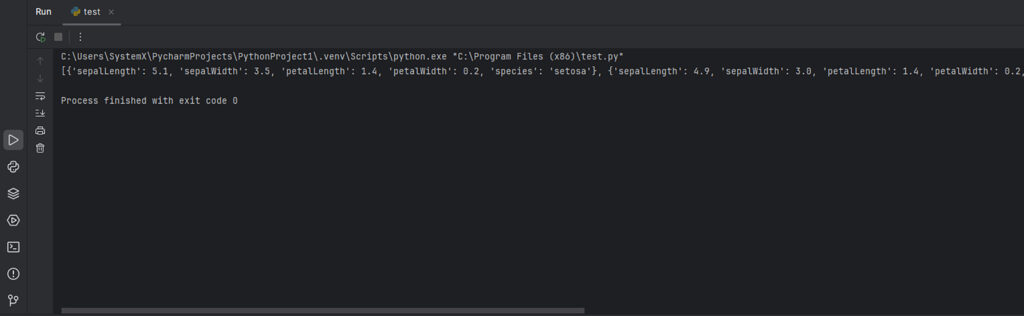
import json # Импортируем стандартный модуль для работы с JSON
with open('iris.json', 'r', encoding='utf-8') as file: # Открываем файл в режиме чтения
data = json.load(file) # Загружаем содержимое файла и превращаем его в Python-объект
print(data[:5]) # Выводим первые 5 строк
Вывод:
Способ 2: С помощью библиотеки pandas
Если вам удобнее работать с данными в табличной форме, используйте pandas. Библиотека автоматически превращает JSON в таблицу, что упрощает дальнейший анализ данных.
import pandas as pd # Импортируем библиотеку pandas
df = pd.read_json('iris.json') # Загружаем JSON-файл и преобразуем его в DataFrame
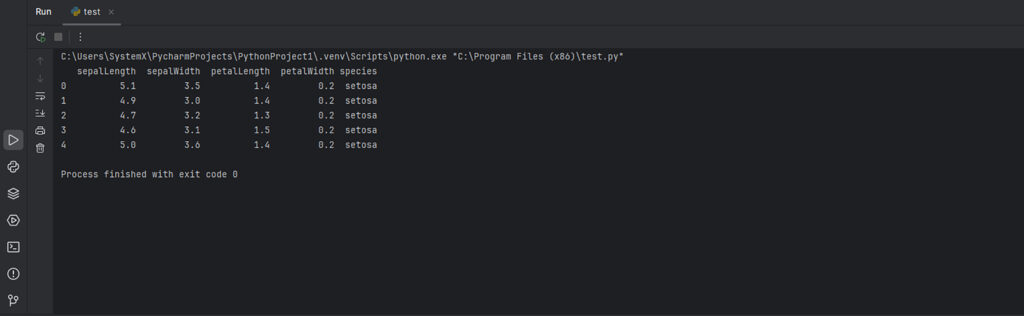
print(df.head(5)) # Выводим первые 5 строк
Вывод:
Загрузка данных из TXT
Другой распространенный тип файлов — это текстовые файлы. Как и CSV или JSON, они содержат информацию в виде текста, однако не всегда предполагают строгий табличный формат.
Продолжим работать c датасетом Iris в формате txt.
with open('iris.txt', 'r', encoding='utf-8') as file:
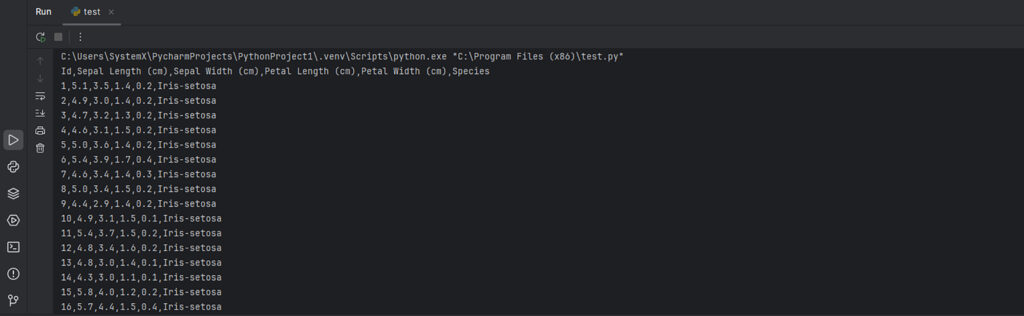
data = file.read() # Открываем файл iris.txt и считываем данные
print(data) # Выводим содержимое файла
Вывод:
Если вам нужно вывести текст построчно (например, первые 5 строк):
with open('iris.txt', 'r', encoding='utf-8') as file:
lines = file.readlines() # Открываем файл и считываем данные построчно
for line in lines[:5]:
print(line.strip()) # Выводим каждую строку, убирая лишние пробелы и переносы
Загрузка данных из Excel
Файлы Excel (.xls или .xlsx) также часто используются для хранения и анализа данных. Для работы с ними в Python обычно применяются библиотеки pandas или openpyxl.
Способ 1: С помощью библиотеки pandas
Pandas позволяет очень просто и удобно загрузить данные из Excel-файла и сразу приступить к их анализу.
import pandas as pd # Импортируем библиотеку pandas
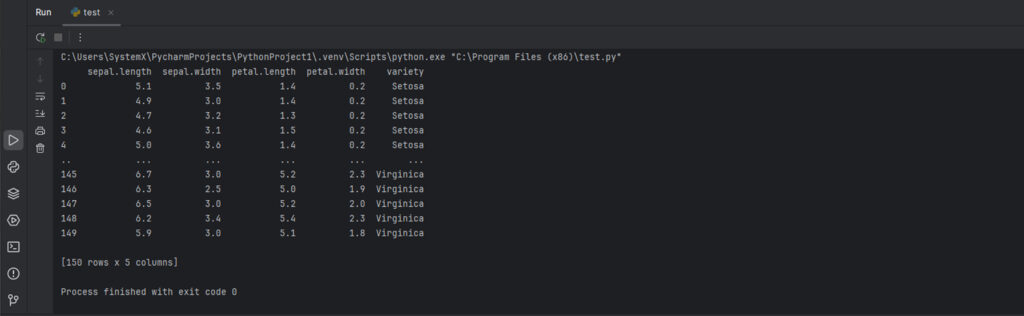
df = pd.read_excel('iris.xlsx', sheet_name='sheet') # Загружаем файл и преобразуем их в DataFrame (предположим, что данные на листе sheet)
print(df) # Выводим DataFrame (по умолчанию вывод сокращен)
Вывод:
Если нужно вывести все строки и столбцы, замените последнюю строку на:
pd.set_option('display.max_rows', None) # Показывать все строки
pd.set_option('display.max_columns', None) # Показывать все столбцы
print(df)
Способ 2: С помощью библиотеки openpyxl
openpyxl — это специализированная библиотека для работы с Excel-файлами.
import openpyxl # Импортируем библиотеку openpyxl
workbook = openpyxl.load_workbook('iris.xlsx') # Загружаем рабочую книгу Excel
sheet = workbook.active # Выбираем активный лист (можно указать конкретный)
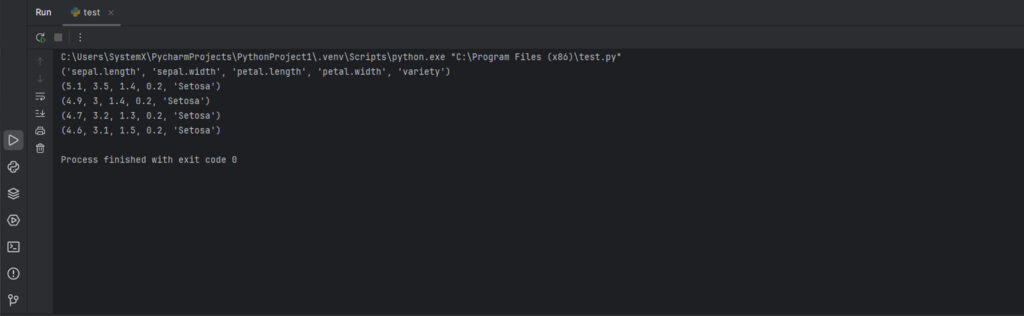
for row in sheet.iter_rows(max_row=5, values_only=True):
print(row) # Выводим первые 5 строк
Вывод:
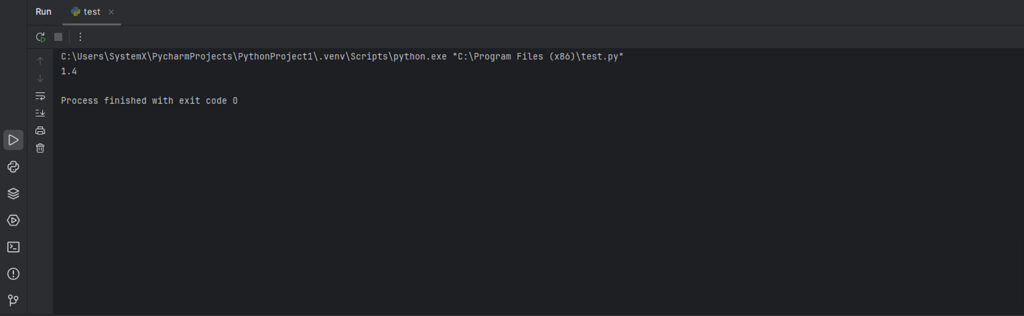
Если нужно получить значение конкретной ячейки замените последние 2 строки на:
cell_value = sheet.cell(row=2, column=3).value # Получаем значение из ячейки (2-я строка, 3-й столбец) print(cell_value) # Выводим значение ячейки
Вывод:
Загрузка данных из SQLite
SQLite — это популярная и простая в использовании база данных, часто используемая в проектах на Python. Чтобы загрузить SQLite, вы можете использовать встроенный модуль Python sqlite3 в комбинации с библиотекой pandas.
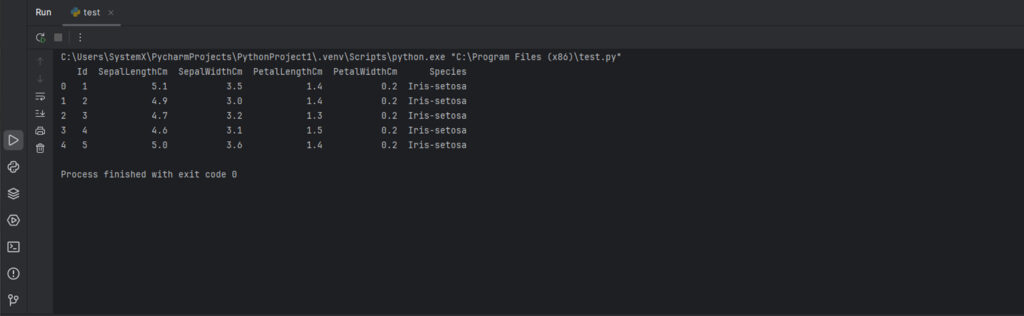
import sqlite3 # Импортируем модуль для работы с SQLite
import pandas as pd # Импортируем библиотеку pandas
connection = sqlite3.connect('database.sqlite') # Устанавливаем соединение с базой данныхimport sqlite3 # Импортируем модуль для работы с SQLite
import pandas as pd # Импортируем библиотеку pandas
connection = sqlite3.connect('database.sqlite') # Устанавливаем соединение с базой данных
query = "SELECT * FROM Iris" # SQL-запрос (замените 'Iris' на нужную таблицу)
df = pd.read_sql_query(query, connection) # Загружаем результат запроса в DataFrame
connection.close() # Закрываем соединение с базой данных
print(df.head(5)) # Выводим первые 5 строк
Вывод:
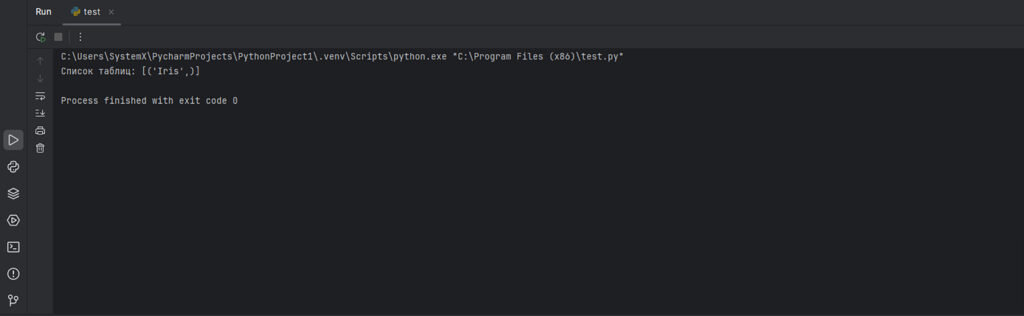
Как узнать название таблиц в файле SQLite?
Если вы не знаете, какие таблицы есть в базе данных:
import sqlite3
connection = sqlite3.connect('database.sqlite') # Устанавливаем соединение с базой данных
cursor = connection.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';") # Получаем список таблиц
tables = cursor.fetchall()
print("Список таблиц:", tables) # Выводим названия таблиц
connection.close() # Закрываем соединение с базой данных
Вывод: