 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыПредставьте, что вы читаете новостную ленту или статью, насыщенную именами людей, названиями компаний, датами и событиями. Как легко для человека понять, кто есть кто и о чем идет речь, не так ли? Но как сделать то же самое компьютеру? Для него это задача не из легких, и именно для этого и существует NER — технология, которая позволяет машинам распознавать и выделять ключевые сущности в тексте. В этой статье мы разберемся, что такое NER, как это работает и почему без этой технологии сложно представить современные системы обработки текстовых данных.
Что такое NER?
NER (Named Entity Recognition, распознавание именованных сущностей) — это одна из ключевых задач в области обработки естественного языка (NLP), направленная на то, чтобы идентифицировать и классифицировать определенные категории слов в тексте. Эти категории называются именованными сущностями.
В отличие от других слов, именованные сущности имеют особое значение в тексте, так как они обозначают конкретные понятия, а не просто служат для создания связного предложения. Классическими примерами именованных сущностей являются:
- Имена людей;
- Названия организаций;
- Географические объекты;
- Даты и время;
- Числовые и денежные выражения.
Однако в зависимости от задачи именованные сущности могут включать и другие категории слов — это могут быть научные термины, медицинские диагнозы, названия мероприятий или произведений искусства, а также многие другие специфические понятия.
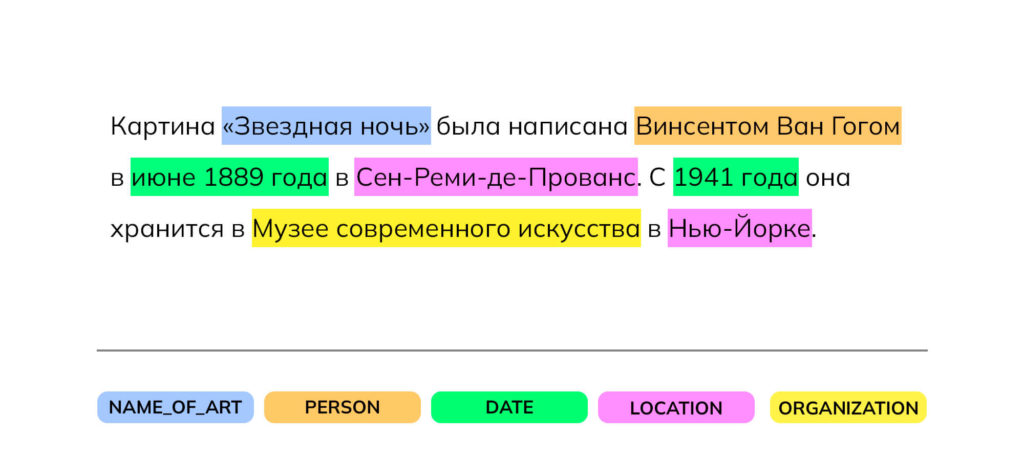
Для чего распознавать именованные сущности?
Ежедневно интернет, новостные сайты и социальные сети пополняются тысячами текстов, полных важных упоминаний. Когда возникает необходимость проанализировать такие массивы данных, ручная обработка оказывается не просто трудоемкой, а практически невыполнимой. Здесь на помощь приходит NER — технология, которая позволяет автоматически извлекать структурированные данные из неструктурированных текстов, значительно упрощая их анализ и обработку.
Сферы применения NER
В реальном мире NER имеет множество применений. Эта технология помогает автоматизировать обработку текстов, извлекать и организовывать информацию, что делает ее незаменимой в разных отраслях. Рассмотрим несколько примеров, чтобы понять, насколько широко используется NER.
Медицина
В медицинской области NER применяется для анализа медицинских данных, научных публикаций и отчетов о клинических исследованиях. Модели NER выделяют и классифицируют названия заболеваний, лекарств, симптомов и методов лечения, облегчая доступ к важной информации и повышая эффективность работы медицинских специалистов.

Журналистика
В сфере журналистики и медиа NER помогает эффективно обрабатывать огромные объемы информации, с которыми ежедневно сталкиваются новостные агентства. Это позволяет создавать структурированные новостные сводки, отслеживать тренды и быстро анализировать актуальные темы.
Бизнес и финансы
Финансовые аналитики используют NER, чтобы автоматически отслеживать упоминания определенных компаний и событий. Это позволяет быстрее находить нужную информацию в отчетах и новостях, анализировать рыночные тренды и отслеживать изменения на финансовых рынках. NER также помогает выявлять риски и возможности для бизнеса, превращая поток данных в структурированную информацию для принятия стратегических решений.
Юриспруденция
В юридической сфере NER используется для автоматизации анализа документов, судебных дел и законодательных актов. NER позволяет выделять имена участников процессов, термины, даты и типы документов, облегчая поиск релевантной информации.

E‑commerce и маркетинг
В маркетинговых исследованиях NER помогает анализировать большие объемы пользовательских данных: отзывы, посты в социальных сетях, сообщения на форумах, а также идентифицировать упоминания брендов, продуктов, мест и других категорий, что позволяет глубже понимать потребительские настроения и адаптировать маркетинговую стратегию.
Как работает распознавание именованных сущностей?
На первый взгляд, процесс распознавания именованных сущностей может казаться магией: компьютер читает текст и мгновенно понимает, что «Москва» — это город, а «Юрий Долгорукий» — имя человека. Но на самом деле, за этим стоят сложные алгоритмы обработки естественного языка, а весь процесс распознавания именованных сущностей делится на два фундаментальных этапа:
- Идентификация сущностей
На этом этапе модель анализирует текст, выделяя все потенциальные сущности. Этот процесс начинается с разбиения текста на токены — отдельные слова или фразы. Затем модель выявляет границы сущностей, определяя, какие слова относятся к именам, датам, организациям и другим категориям.
- Классификация сущностей
После того как сущности идентифицированы, модель переходит к их классификации. Это означает, что каждой выделенной сущности присваивается определенный тип: «человек», «организация», «место» и т. д. В традиционных статистических моделях для этого часто применяются наборы правил или словари, тогда как в современных моделях тип сущности определяется на основе их обучения с помощью размеченных данных. Более подробно о методах, используемых в NER-моделях, мы поговорим дальше.

Методы NER
Различные методы NER имеют свои преимущества и ограничения, что позволяет выбирать подходящий способ реализации в зависимости от поставленной задачи. Здесь мы рассмотрим основные методы NER: на основе словарей, правил, машинного и глубокого обучения.
NER на основе словарей
Метод NER на основе словарей полагается на заранее составленные списки или словари сущностей, в которые включены имена, организации, места и другие категории. Этот метод применяется, когда есть строгий набор терминов, и он часто используется в узкоспециализированных областях.
Как это работает?
- Сначала собирается большой набор словарей, содержащих сущности из разных категорий. Например, для сущности «место» в словарь добавляются названия стран, городов и географических объектов.
- Во время анализа NER-система сканирует текст и ищет совпадения со словами, включенными в словарь. Если найдено соответствие, она классифицирует эти слова как именованные сущности.
| Преимущества | Недостатки |
|---|---|
| Простота реализации. | Ограниченность и слабая адаптация к новым данным: словари необходимо постоянно обновлять, чтобы учитывать новые сущности, например новые названия компаний. |
| Высокая точность при работе с заранее известными сущностями. | Проблемы с идентификацией неоднозначных сущностей |
NER на основе правил
Подход на основе правил использует набор заранее заданных шаблонов и правил для определения сущностей. Эти правила могут включать грамматические особенности, регулярные выражения и синтаксические конструкции, которые помогают находить нужные элементы в тексте. Например, если система знает, что имена людей обычно следуют после слов «господин» или «госпожа», она сможет точнее определять сущности в тексте. Этот метод эффективен для задач, где сущности подчиняются определенным языковым закономерностям.
Как это работает?
- Сначала составляется набор правил и шаблонов для анализа текста (например, для даты — формат «дд/мм/гггг»).
- Затем система анализирует текст, применяя заданные правила, чтобы идентифицировать соответствующие сущности.
| Преимущества | Недостатки |
|---|---|
| Высокая точность при работе с предсказуемыми, структурированными данными, такими как даты или валюты. | Сложность масштабирования: для обработки больших и разнообразных текстов нужно много правил, что требует времени на разработку и поддержку. |
| Контролируемость: правила можно адаптировать и изменять под специфические требования задачи. | Слабая гибкость: правила не всегда хорошо обрабатывают неструктурированные или неожиданные форматы данных. |
NER на основе машинного обучения
С развитием технологий традиционные методы NER, основанные на словарях и наборе правил, постепенно уступают место моделям, использующим машинное и глубокое обучение.
Метод NER на основе машинного обучения использует размеченные данные для обучения модели, которая сможет самостоятельно выявлять закономерности между словами и определять сущности на основе примеров. Наиболее популярные алгоритмы для таких задач — скрытые марковские модели (HMM) и условные случайные поля (CRF).
Как это работает?
- Сначала создается обучающий набор размеченных данных. Например, в тексте «Илон Маск основал SpaceX» сущности «Илон Маск» и «SpaceX» будут отмечены и классифицированы как «персона» и «организация».
- Модель обучается на этом наборе, выявляя связи между словами и их метками.
- После обучения модель может применять свои знания для распознавания сущностей в новых текстах.
| Преимущества | Недостатки |
|---|---|
| Высокая точность и адаптивность в распознавании разнообразных сущностей | Необходимость в большом количестве размеченных данных для обучения. |
| Способность обрабатывать более сложные контексты. | Высокие вычислительные затраты. |
| Интерпретируемость результатов. | Сложность в разработке и настройке моделей. |
NER на основе глубокого обучения
Современные модели NER все чаще используют нейронные сети и глубокое обучение для повышения точности распознавания сущностей, особенно в сложных и неоднозначных контекстах. Самыми популярными подходами являются LSTM-модели, а также трансформеры (например, BERT и GPT).
Как это работает?
- Так же как и в машинном обучении, для модели NER на основе глубокого обучения, создается набор обучающих данных.
- Модель обучается на этом наборе, используя сложные нейронные архитектуры, такие как LSTM или трансформерные сети.
- После обучения модель может учитывать контекст и сложные взаимосвязи между словами, что позволяет ей распознавать сущности даже в сложных предложениях.
| Преимущества | Недостатки |
|---|---|
| Высокая точность и способность учитывать контекст, что улучшает распознавание многозначных слов. | Высокие вычислительные затраты. |
| Отличная производительность в сложных задачах. | Зависимость от большого объема размеченных данных. |
Проблема неоднозначности сущностей
Несмотря на все преимущества различных методов NER, включая самые современные, есть одна проблема, которая остается актуальной для всех подходов, — это неоднозначность сущностей. Иными словами, это ситуация, когда одно и то же слово может иметь несколько значений в зависимости от контекста.
Например, слово «Волга» в одном тексте может относиться к названию марки советского автомобиля, а в другом — к реке, и такие различия, которые людям кажутся очевидными, требуют от моделей гораздо более глубокого анализа.
ML-инженеры стремятся уменьшить влияние неоднозначности сущностей на результаты работы NER-моделей, используя такие методы как углубленный семантический анализ, контекстное моделирование и связывание сущностей с внешними базами данных. Эти подходы помогают моделям точнее интерпретировать многозначные слова, минимизировать ошибки и лучше учитывать контекст.
Подготовка данных для обучения — ключевой аспект разработки современной NER-модели
Для того, чтобы современные NER-модели на основе машинного или глубокого обучения могли справляться не только с неоднозначностью, но и со множеством других сложных задач, им необходимы большие массивы обучающих данных.
Весь процесс подготовки данных для обучения NER-модели делится на три основных этапа: сбор, разметка и разделение данных. Рассмотрим каждый из них подробнее.
Сбор данных
Первый этап в подготовке данных для обучения — это сбор данных. Этот процесс в свою очередь состоит из следующих шагов:
- Определение источников. В первую очередь необходимо определить, какие источники будут использоваться для сбора текстов. Это могут быть статьи, блоги, новости, научные публикации, социальные сети и другие текстовые ресурсы.
- Создание корпуса данных. Далее необходимо сформировать корпус данных — набор текстов, который будет достаточно широким, чтобы охватить все нужные типы сущностей и контексты, в которых они могут встречаться. Чем больше и разнообразнее будет корпус, тем лучше модель сможет обучиться обрабатывать текст.
Разметка данных
Следующий этап — разметка собранных данных. Разметка данных — это процесс выделения и классификации слов или выражений (сущностей) в тексте в соответствии с их типами, такими как имена людей, названия организаций, географические объекты и даты. Цель этого процесса заключается в том, чтобы превратить сырые тексты в структурированные обучающие примеры.
Разметка данных может выполняться вручную, полуавтоматически или автоматически. Выбор подхода зависит от совокупности параметров: необходимой точности и скорости разметки, объема данных и доступных ресурсов проекта.
| Ручная разметка | Полуавтоматическая разметка | Автоматическая разметка |
|---|---|---|
| Специалисты вручную присваивают метки каждому элементу данных, что обеспечивает высокое качество разметки. Однако этот процесс длителен и трудоемок, а также требует дополнительных затрат на привлечение специалистов. | Разметка выполняется с помощью автоматических алгоритмов, а затем полученные результаты корректируются вручную специалистами. Этот подход позволяет ускорить процесс и снизить нагрузку на людей, хотя готовые данные все равно требуют проверки перед использованием. | В этом случае разметка выполняется полностью автоматизировано, без участия человека. Автоматическая разметка позволяет быстро обрабатывать большие объемы данных, но качество разметки может быть низким. |
Разделение данных
Завершающим шагом подготовки данных является их разделение на три выборки:
- Тренировочные данные. Используются для непосредственного обучения модели. Эта выборка должна содержать достаточный объем размеченных данных, чтобы модель могла эффективно учиться находить закономерности и распознавать сущности в будущих задачах.
- Валидационные данные. Необходимы для настройки гиперпараметров модели и оценки ее производительности в процессе обучения. Валидационная выборка помогает избежать проблемы переобучения (overfitting) — ситуации, когда модель становится слишком зависимой от конкретных тренировочных примеров и плохо справляется с новыми данными.
- Тестовые данные. Служат для окончательной оценки производительности модели после ее обучения. Тестовые данные не пересекаются с тренировочной и валидационной выборкой и нужны для того, чтобы объективно оценить, насколько хорошо модель будет справляться с новыми задачами.
Обзор инструментов и библиотек для создания NER-модели
Теперь, когда мы обсудили важные аспекты подготовки данных для NER-модели, пришло время рассмотреть инструменты и библиотеки, которые помогут реализовать эту модель на практике.
- SpaCy — это мощная и быстроразвивающаяся библиотека для обработки естественного языка, которая включает в себя предобученные модели для распознавания именованных сущностей. Она предлагает удобный интерфейс и высокую производительность, что делает ее идеальным выбором для коммерческих приложений. SpaCy позволяет легко интегрировать пользовательские модели и обучать свои собственные на основе размеченных данных. Также стоит отметить, что SpaCy активно поддерживает различные языки, включая английский, испанский, немецкий и другие.
- NLTK (Natural Language Toolkit) — это одна из самых известных библиотек для обработки текста в Python. Хотя она не так производительна, как SpaCy, NLTK предоставляет богатый набор инструментов для обработки текста. Однако для NER в NLTK часто требуется больше ручной настройки и предварительной обработки, что может быть менее удобно для начинающих специалистов.
- Hugging Face Transformers — предоставляет доступ к широкому спектру предобученных трансформеров, таких как BERT, RoBERTa и GPT и позволяет легко обучать и настраивать модели NER, используя готовые архитектуры и мощные методы обработки текста. Благодаря активному сообществу разработчиков, библиотека предлагает множество ресурсов и документации для облегчения процесса разработки моделей.
- AllenNLP — это библиотека для обработки естественного языка, основанная на PyTorch, которая позволяет создавать модели глубокого обучения. Она предлагает высокоуровневый интерфейс и уже реализованные компоненты, такие как механизмы внимания и предобученные эмбеддинги. AllenNLP отлично подходит для разработчиков, работающих с глубокими нейронными сетями и желающих экспериментировать с новыми архитектурами и подходами к решению задач NER.
- Stanford NLP — библиотека от Стэнфордского университета, которая предлагает мощные инструменты для обработки естественного языка, включая модели NER. Она предоставляет широкий спектр языковых инструментов, но может потребовать больше усилий для интеграции в проекты на Python.
Будущее NER
Современные модели NER становятся все более точными, но их потенциал далеко не исчерпан.
Одним из главных направлений развития NER является улучшение способности моделей распознавать сущности в сложных и неоднозначных контекстах. Более продвинутые модели будут обучены на еще больших объемах данных и смогут учитывать множество факторов, таких как культурные различия и контекст употребления. Это позволит решать проблему неоднозначности более эффективно и точно.
Еще одно важное направление — мультиязычное и кросс-язычное распознавание сущностей. В будущем NER-системы смогут работать не только с одним языком, но и легко адаптироваться к текстам на разных языках. Это важно для глобальных компаний и организаций, работающих в многоязычной среде, где анализ данных и коммуникации ведутся на разных языках одновременно. В настоящее время уже существуют примеры мультиязычных моделей, такие как mBERT и XLM‑R, которые демонстрируют многообещающие результаты в этой области.
Также стоит ожидать, что NER будет тесно интегрирован с другими технологиями обработки естественного языка (NLP), что приведет к созданию более мощных и универсальных систем анализа текстов. Например, NER в связке с системами анализа тональности или генерации текста поможет не только распознавать сущности, но и предлагать более сложные выводы и рекомендации на основе текста.
Ключевые выводы
Распознавание именованных сущностей (NER) — это мощный инструмент в области обработки естественного языка, который помогает автоматизировать извлечение важной информации из текстов. NER позволяет идентифицировать и классифицировать такие сущности, как имена людей, организации и даты, значительно облегчая анализ больших объемов данных.
Таким образом, эта технология открывает новые горизонты для автоматизации анализа данных, что особенно актуально в нашем стремительно меняющемся мире.