 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыЕще совсем недавно мы считали компьютеры исключительно инструментами для выполнения рутинных задач. Однако с появлением искусственного интеллекта и нейросетей технологии сделали огромный шаг вперед. Сегодня они не только облегчают нашу жизнь, но и кардинально меняют ее: помогают врачам диагностировать болезни, позволяют автомобилям ездить без водителя, пишут тексты и даже создают произведения искусства.

Почему это стало возможно? Главная причина — способность нейросетей учиться. Именно благодаря обучению нейросети могут адаптироваться к новым задачам и находить решения, которые не были заранее запрограммированы. Понять, как работает эта технология, не только интересно, но и важно, ведь она уже формирует наше будущее.
Что такое нейросеть?
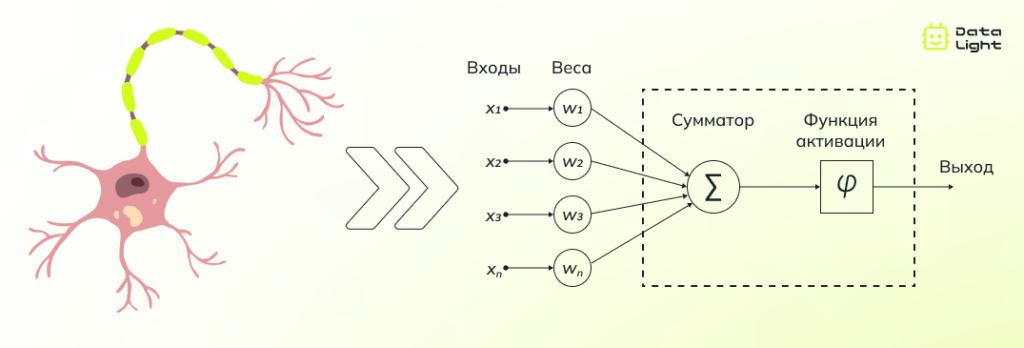
В общем смысле нейросеть — это продвинутая математическая модель, которая помогает решать сложные задачи. Принцип ее работы вдохновлен устройством человеческого мозга, а точнее нейронами — клетками, которые обрабатывают и передают информацию.
В нашем мозге нейроны соединены между собой и обмениваются сигналами, что позволяет нам воспринимать окружающий мир, принимать решения и обучаться. Нейросети работают по схожему принципу: они состоят из множества искусственных нейронов, объединенных в сложную сеть. Каждый такой нейрон принимает данные, преобразует их и передает результат следующим нейронам.
Эти нейроны организованы в слои. Первый слой, называемый входным, принимает исходные данные — например, изображение или текст. Затем информация передается через скрытые слои, где происходит ее обработка. Здесь каждый нейрон анализирует поступившие данные и передает результаты дальше, настраивая свои «решения» через так называемые веса — параметры, которые определяют силу связи между нейронами.
В финале информация попадает в выходной слой, где формируется результат: это может быть, например, распознавание объекта на изображении, перевод текста или прогноз погоды.
Именно взаимодействие между слоями и способность корректировать веса делают нейросеть способной «учиться» — улучшать свои результаты на основе опыта. Благодаря этому подходу нейросети способны решать задачи, с которыми даже человеку порой справиться непросто. Далее мы рассмотрим, как именно обучаются нейросети, но сначала скажем несколько слов о том, как люди пришли к созданию этой технологии.
История появления и развития нейросетей
Несмотря на то что популярность нейронных сетей глобально выросла только в последнее десятилетие, их история берет свое начало еще в середине XX века. Уже тогда ученые пытались создать математические модели, имитирующие работу мозга.
В 1943 году Уоррен МакКаллок и Уолтер Питтс предложили первую модель искусственного нейрона, которая стала основой для дальнейших исследований, а в 1958 году Франк Розенблатт разработал перцептрон — простейшую нейронную сеть, способную распознавать и классифицировать данные. Однако из-за ограниченных вычислительных ресурсов развитие нейронных сетей на тот момент замедлилось, хотя и не остановилось — исследования продолжались, а теоретическая база постепенно расширялась.
Настоящее возрождение нейросетевых технологий началось в 2000‑х годах с развитием глубокого обучения, которое стало возможным благодаря улучшениям в вычислительных системах и появлению больших объемов данных.
Сейчас нейросети стали основным инструментом в решении множества сложных задач, которые традиционные алгоритмы не могли бы эффективно решить. Они применяются в анализе изображений, распознавании речи, прогнозировании данных, а также для создания инновационных продуктов и сервисов в таких областях, как медицина, финансы, автомобильная промышленность и многих-многих других.
Виды нейросетей
Эволюция нейронных сетей привела к появлению множества их разновидностей. В зависимости от сложности архитектуры и способа применения нейросети делятся на две основные группы: те, что относятся к машинному обучению, и те, что входят в область глубокого обучения. Чтобы лучше понять, как они различаются, давайте разберемся, что представляют собой эти понятия.
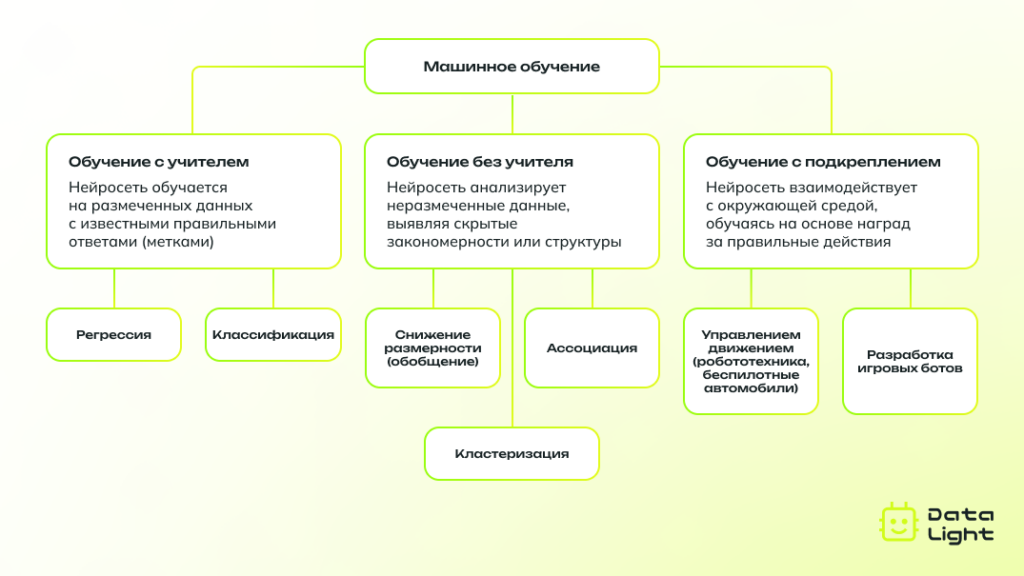
Машинное обучение (Machine Learning)
Машинное обучение — это раздел искусственного интеллекта, в котором создаются алгоритмы, позволяющие компьютеру обучаться на данных без явного программирования всех решений. Нейросети в рамках машинного обучения, как правило, имеют простую архитектуру (ограниченное количество слоев) и предназначены для решения относительно узкого круга задач.
Типы нейросетей в машинном обучении:
- Перцептрон — базовая нейросеть, состоящая из одного слоя нейронов. Она может решать только простые задачи классификации.
- Многослойный перцептрон (MLP) — улучшенная версия перцептрона с несколькими скрытыми слоями. Используется для задач классификации и регрессии, где требуется обработка нелинейных данных.
Глубокое обучение (Deep Learning)
Глубокое обучение — это подмножество машинного обучения, где используются многослойные нейросети для работы с большими объемами данных и решения сложных задач. Глубокие нейросети обладают более сложной архитектурой, включающей десятки или сотни слоев, что позволяет им выявлять сложные закономерности в данных.
Типы нейросетей, относящихся к глубокому обучению:
- Сверточные нейронные сети (Convolutional Neural Networks, CNN) — специально разработаны для обработки изображений, видео и других визуальных данных. Включают слои свертки, которые выделяют особенности изображений (например, края, текстуры). Применяются для распознавания лиц, диагностики медицинских изображений, анализа видео.
- Рекуррентные нейронные сети (Recurrent Neural Networks, RNN) — используются для работы с последовательными данными, такими как текст, аудио, временные ряды. Эти сети имеют циклические связи, что позволяет учитывать информацию из предыдущих шагов.
- LSTM (Long Short-Term Memory) — является усовершенствованной версией RNN. LSTM справляется с долгосрочными зависимостями в данных, которые традиционные RNN не могут эффективно обрабатывать из-за проблемы затухания или взрывного градиента.
- Генеративные модели (Generative Adversarial Networks, GAN) — модели, которые могут генерировать новые данные, похожие на те, что были использованы для их обучения. Состоят из двух компонентов: генератора, создающего новые данные, и дискриминатора, оценивающего их правдоподобие. GANs используются для генерации изображений, создания видео, а также в творческих приложениях, таких как синтез музыки или улучшение фотографий.
- Трансформеры (Transformers) — архитектура, которая революционизировала обработку текста. Трансформеры позволяют работать с текстами и последовательностями в параллельном режиме, что ускоряет обучение. Примеры таких моделей — BERT и GPT, применяемые в чат-ботах, переводчиках и поисковых системах.
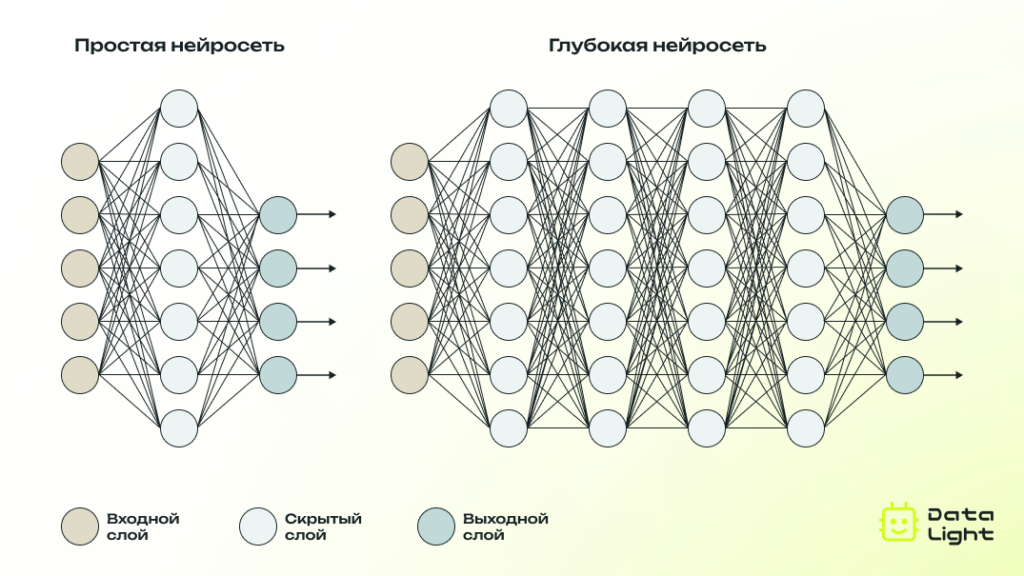
Таким образом, глубокое обучение фокусируется на обучении моделей с большим количеством слоев, способных извлекать сложные признаки из данных, в то время как машинное обучение использует более простые алгоритмы, которые могут быть менее требовательными к данным и вычислительным ресурсам.
Как обучаются нейросети?
Чтобы нейросеть могла решать задачи, она должна пройти процесс обучения. Обучение — это ключевая стадия, которая превращает нейросеть из абстрактной математической модели в мощный инструмент, способный анализировать данные и находить закономерности. В основе этого процесса лежит постепенная настройка параметров сети (весов) на основе данных.
Существует несколько подходов к обучению нейросетей, и каждый из них имеет свои особенности.
Обучение с учителем
Обучение с учителем — это наиболее распространенный способ обучения нейросетей. В этом случае нейросеть обучается на заранее подготовленных данных, которые содержат как входные данные, так и правильные ответы (метки). Задача нейросети — научиться распознавать закономерности между входными данными и их метками, чтобы на основе новых, ранее не встречавшихся данных, она могла сделать правильные предсказания.
Чтобы лучше понять, почему этот метод так называется, процесс обучения можно представить как диалог между учителем и учеником, где учитель — это заранее известные ответы, а ученик — нейросеть, которая учится предсказывать эти ответы.
Пример: для задачи классификации изображений нейросеть может быть обучена на наборе изображений с метками, например, «человек» или «животное». На основе этих примеров нейросеть учится различать объекты, чтобы потом точно классифицировать новые изображения.
Особенности метода:
- Требуются большие объемы размеченных данных.
- Применяется в задачах классификации, регрессии, распознавания речи и текста.
Обучение без учителя
Обучение без учителя — это метод, при котором нейросеть обучается на данных, не имеющих меток. В этом случае задача нейросети — самостоятельно выделить скрытые закономерности и структуру в данных. Обычно этот метод используется для кластеризации, снижения размерности или поиска скрытых шаблонов в данных.
Пример: в задаче кластеризации нейросеть может группировать данные по схожести, без явных меток. Это позволяет выявить различные категории, например, группы животных или объектов на изображениях.
Особенности метода:
- Не требует размеченных данных, что делает его полезным в ситуациях, когда разметка невозможна или слишком трудозатратна.
- Применяется в задачах кластеризации.
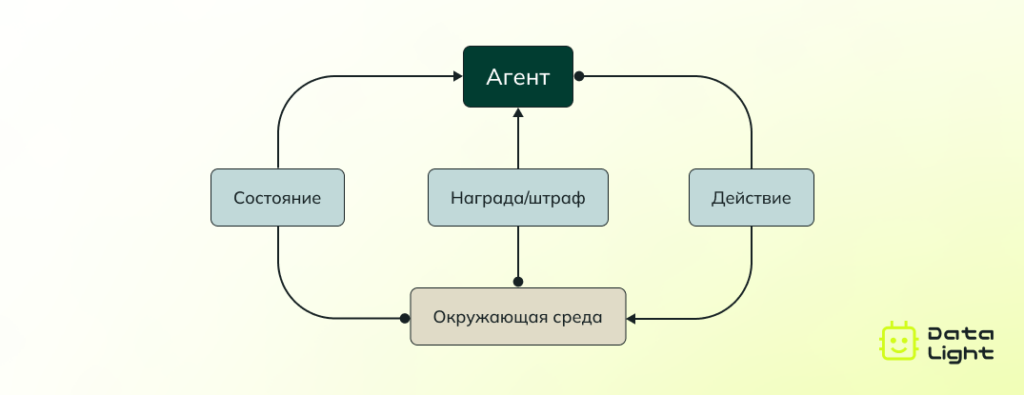
Обучение с подкреплением
Обучение с подкреплением — это метод, при котором нейросеть учится на основе взаимодействия с окружающей средой. В отличие от обучения с учителем и без учителя, где данные фиксированы, в обучении с подкреплением нейросеть принимает решения и получает «награды» или «штрафы» за свои действия.
Пример: в задаче управления роботом нейросеть может принимать решения о движении робота в определенном направлении и получать награду за правильное движение или штраф за ошибку. С течением времени она учится выбирать наилучшие действия, чтобы максимизировать награду.
Особенности метода:
- Подходит для задач, где необходима последовательность действий: управление роботами, игры.
- Может использоваться даже в отсутствии точного представления о том, как должна выглядеть правильная стратегия.
Каждый из этих методов имеет свои сильные и слабые стороны и используется в зависимости от типа задачи и доступных данных. Нейросеть, обучающаяся с учителем, будет эффективной в задачах, где имеются четкие метки, в то время как обучение без учителя идеально подходит для работы с неструктурированными данными, а обучение с подкреплением — для задач, связанных с оптимизацией действий в изменяющихся условиях.
Основные алгоритмы обучения
Если метод обучения определяет, как нейросеть взаимодействует с данными и чему она учится, то выбор алгоритма определяет, каким образом корректируются внутренние параметры сети — веса.
Вес — это числовой коэффициент, который регулирует, насколько значим тот или иной входной сигнал для нейрона. Простыми словами, вес определяет вклад каждого входного значения в общий результат нейросети. Во время обучения веса изменяются, чтобы сеть лучше справлялась с поставленной задачей. Например, если нейросеть распознает изображения, вес может «подсказывать», что определенные линии или формы важнее для определения объекта.
Для настройки весов используются алгоритмы, такие как обратное распространение ошибки, упругое распространение, а также генетический алгоритм обучения. Рассмотрим их подробнее.
Алгоритм обратного распространения ошибки (Backpropagation)
Обратное распространение ошибки — это основной алгоритм обучения нейросети, который позволяет корректировать ее внутренние параметры (веса) на основе допущенных ошибок. Благодаря этому алгоритму нейросеть может постепенно учиться выполнять задачи все лучше и точнее.
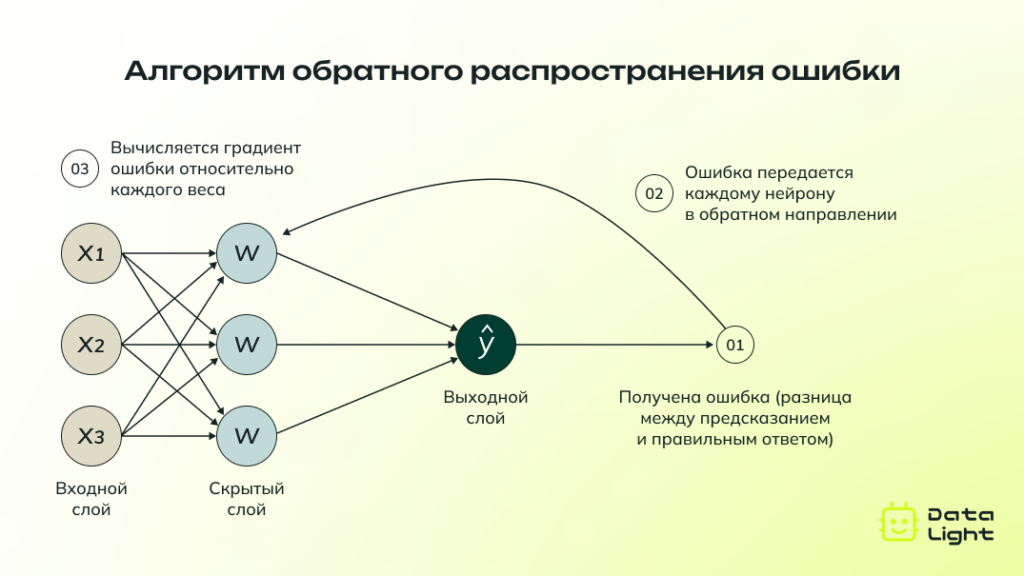
Как это работает?
Когда нейросеть выполняет задачу, она делает предсказание на основе имеющихся данных. Однако это предсказание обычно не совпадает с правильным ответом, и эта разница между результатом и правильным ответом называется ошибкой. Чтобы улучшить свои предсказания, нейросеть должна понять, где именно она ошиблась и как это исправить.
Алгоритм обратного распространения ошибки начинается с того, что нейросеть вычисляет величину ошибки на выходе, то есть в результате предсказания. Затем эта ошибка передается обратно через все слои нейросети, начиная с последнего слоя и заканчивая первым. Каждому нейрону сообщается, насколько сильно его действия повлияли на итоговую ошибку.
На основе этой информации вычисляется градиент ошибки — величина, которая показывает, в каком направлении и насколько сильно нужно изменить вес, чтобы уменьшить ошибку. Он необходим для применения метода градиентного спуска. Этот метод шаг за шагом изменяет веса в направлении, приближая их к значениям, при которых ошибка минимальна.
Алгоритм повторяется многократно: каждый раз, когда нейросеть делает ошибку, она находит ее причины и настраивает свои параметры, становясь все более точной. В итоге нейросеть обучается на собственных ошибках, постепенно улучшая свою способность решать задачи.
Алгоритм упругого распространения
Алгоритм упругого распространения (Resilient Propagation, RPROP) — это усовершенствованный метод обучения нейросетей, разработанный для устранения недостатков традиционного метода обратного распространения ошибки.
Ключевая идея RPROP заключается в том, чтобы учитывать только направление изменения (знак градиента ошибки), игнорируя его величину. Это позволяет избежать проблем, связанных с очень большими или слишком малыми значениями градиента, которые могут замедлять или дестабилизировать обучение.
Как это работает?
В начале обучения для каждого веса задается стартовый шаг изменения. Если изменение веса в определенном направлении приводит к уменьшению ошибки, шаг увеличивается, что ускоряет процесс обучения. Если же ошибка растет, направление изменения веса меняется на противоположное, а шаг уменьшается, чтобы избежать ухудшения результата.
Особенность RPROP в том, что шаг изменения веса регулируется адаптивно для каждого отдельного веса. Это позволяет более точно и эффективно корректировать веса, что особенно важно для больших нейросетей или сложных задач.
Генетический алгоритм
Генетический алгоритм — это метод, который помогает нейросети находить лучшие решения, используя принципы, похожие на те, что действуют в природе. Он работает по аналогии с процессами естественного отбора: лучшие решения «выживают», а остальные отбрасываются или изменяются, чтобы постепенно улучшить результаты работы нейросети.
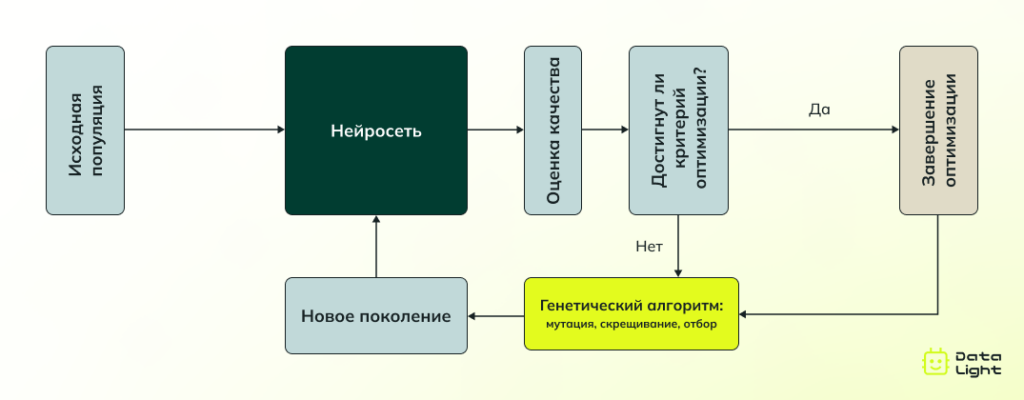
Как это работает?
Генетический алгоритм работает с набором возможных решений, которые называются популяцией. Каждый элемент этой популяции — это как индивидуум в природе, который имеет определенные характеристики. В контексте нейросетей это будут возможные комбинации весов нейронов.
- Первоначально популяция решений создается случайным образом. Затем нейросеть оценивает, насколько каждое решение эффективно, как хорошо оно решает поставленную задачу. Те решения, которые показывают лучшие результаты, отбираются для следующего этапа, как в природе отбираются самые сильные особи для размножения.
- Далее происходит процесс «скрещивания»: лучшие решения комбинируются друг с другом, создавая новые, потенциально более эффективные варианты. Кроме того, в процесс может быть добавлена небольшая «мутация», когда случайные изменения вносятся в решение, чтобы добавить разнообразие.
Таким образом, с каждым новым поколением решения становятся все лучше, потому что каждый раз используется только лучший опыт из предыдущего поколения. Этот процесс продолжается до тех пор, пока не будет найдено оптимальное решение для задачи.
Генетический алгоритм полезен, когда задача очень сложная и традиционные методы поиска оптимального решения могут быть слишком медленными или неэффективными.
Проблемы и вызовы в обучении нейросетей
Несмотря на стремительное развитие технологий и разнообразие методов и алгоритмов, обучение нейросетей сталкивается с рядом проблем и вызовов. Вот некоторые из них:
Высокие вычислительные затраты
Обучение сложных нейросетей, особенно глубоких, требует значительных вычислительных мощностей. Например, сверточные сети или трансформеры, содержат миллионы или даже миллиарды параметров, которые необходимо оптимизировать. Это создает проблемы для организаций с ограниченными вычислительными ресурсами, увеличивая затраты на обучение и использование таких моделей. В то же время, существуют попытки уменьшить вычислительные требования с помощью более эффективных алгоритмов и специализированных аппаратных решений, однако эти подходы не всегда позволяют полностью решить проблему.
Интерпретируемость решений
Нейросети часто называют «черным ящиком», поскольку их решения сложно интерпретировать. Это означает, что:
- Трудно понять, почему модель приняла определенное решение.
- Отсутствие прозрачности может снижать доверие к модели и затруднять ее использование, например, в медицинских проектах.
Решение этой проблемы включает использование методов интерпретируемого машинного обучения (XML) и объяснимого ИИ (XAI), но они не всегда могут обеспечить полное объяснение того, как моделью была принята определенная рекомендация. Баланс между точностью и интерпретируемостью остается актуальной задачей.
Переобучение (Overfitting)
Переобучение происходит, когда модель чрезмерно адаптируется к обучающим данным. В результате она «запоминает» детали, которые не являются важными для общего паттерна, и теряет способность обобщать информацию.
Методы регуляризации, такие как Dropout и L2-регуляризация, помогают снизить вероятность переобучения, однако подходы могут давать разные результаты в зависимости от задачи и структуры данных, и порой требуется множество экспериментов для нахождения оптимального решения.
Зависимость от данных
Для эффективного обучения нейросетей требуется огромное количество данных. При этом:
- Данные должны быть разнообразными и качественными, чтобы модель могла успешно обобщать.
- Подготовка и разметка таких данных требует значительных ресурсов.
- В некоторых случаях, например в медицинских исследованиях или промышленности, доступ к данным может быть ограничен из-за конфиденциальности или высокой стоимости их сбора.
Решением может быть использование синтетических данных или предварительно обученных моделей, а также методов переноса обучения, однако эти подходы не всегда обеспечивают столь же высокое качество, как использование реальных данных. Проблема сбора и качества данных остается одной из самых сложных, и ее решение зависит от множества факторов, включая область применения.
Ключевые выводы
Нейросети — это мощный инструмент, который значительно расширяет возможности обработки и анализа данных. Обучение нейросетей позволяет им адаптироваться к новым задачам, извлекать скрытые закономерности из данных и принимать решения, которые не были заранее запрограммированы.
Сейчас нейросети обучаются с использованием разных методов: с учителем, без учителя и с подкреплением, в зависимости от типа задачи. Но несмотря на успехи, обучение нейросетей сталкивается с рядом проблем. В будущем ожидается, что с развитием технологий и улучшением алгоритмов обучение нейросетей станет более эффективным и доступным, что позволит решать эти проблемы.