 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыКогда мы смотрим на фотографию, наш мозг легко выделяет на ней разные объекты: вот дорога, здесь дерево, а там — автомобиль. Для человека это естественно и не требует усилий, но для компьютера изображение — это просто набор пикселей, лишенный смысла. Чтобы научить машины «видеть», исследователи в области компьютерного зрения решают множество сложных задач.
В этой статье мы поговорим о сегментации изображений: выясним, что она собой представляет, какие существуют ее виды, чем она отличается от классификации и детекции, а также рассмотрим процесс создания размеченных данных, необходимых для обучения моделей.

Что такое сегментация изображений?
Сегментация изображений — это задача в области компьютерного зрения, заключающаяся в разделении изображения на несколько различных сегментов, каждый из которых соответствует определенному объекту — будь то человек, здание, дерево или любой другой объект. Цель этого процесса заключается в том, чтобы с точностью до пикселя выделить объекты на изображении и тем самым предоставить полную информацию о их форме и местоположении для дальнейшего анализа.
Чтобы лучше понять, что такое сегментация, сравним ее с другими задачами компьютерного зрения:
- Классификация определяет, что изображено на изображении в целом. Модель относит изображение к одному из классов, например, «кошка», «автомобиль» или «пейзаж».
- Детекция идет дальше классификации. Она не только определяет, какие объекты присутствуют на изображении, но и выделяет их границы с помощью прямоугольных рамок, указывая примерное местоположение.
- Сегментация в отличие от детекции анализирует изображение на более детальном уровне, выделяя контуры объектов с точностью до пикселя. Она позволяет получить полное представление о форме, размерах и точном расположении каждого объекта на изображении.

Виды сегментации изображений
Выделяют несколько видов сегментации, каждый из которых решает уникальные задачи и применяется в разных областях. Понимание различий между ними позволяет выбрать наиболее эффективный метод для работы с изображениями.
Семантическая сегментация (Semantic Segmentation)
Семантическая сегментация — это способ сегментации изображений, при котором каждый пиксель на изображении классифицируется как принадлежащий определенному классу. Основной особенностью семантической сегментации является то, что она не различает отдельные экземпляры объектов одного класса.

Инстанс-сегментация (Instance Segmentation)
Инстанс-сегментация — это более сложный тип сегментации по сравнению с семантической. Она не только классифицирует объекты, но и выделяет каждый из них как отдельный экземпляр. Это позволяет точно отделить объекты, даже если они находятся близко или перекрывают друг друга.

Паноптическая сегментация (Panoptic Segmentation)
Паноптическая сегментация объединяет подходы семантической и инстанс-сегментации. Ее задача — определить класс каждого пикселя на изображении, одновременно выделяя отдельные экземпляры объектов.
Обычно паноптическая сегментация работает следующим образом:
- Фоновые объекты (например, небо, земля, здания и т. д.) объединяются в единые области, как это делается в семантической сегментации.
- Объекты, представляющие интерес (такие как люди, автомобили, животные) выделяются как отдельные экземпляры, аналогично инстанс-сегментации. Каждый экземпляр объекта рассматривается индивидуально, даже если он принадлежит тому же классу, что и другие.
Таким образом, паноптическая сегментация дает полное представление о сцене, что делает ее особенно полезной для сложных задач компьютерного зрения.

Сравнение видов сегментации изображений
| Критерий | Семантическая сегментация | Инстанс-сегментация | Паноптическая сегментация |
|---|---|---|---|
| Цель | Классификация всех пикселей изображения | Выделение и классификация отдельных объектов | Классификация всех пикселей изображения и выделение отдельных объектов |
| Объекты одного класса | Рассматриваются как единое целое | Рассматриваются как отдельные экземпляры | Рассматриваются как отдельные экземпляры |
| Фон | Классифицируется | Чаще игнорируется | Классифицируется |
| Точность детализации | Средняя | Высокая | Очень высокая |
| Сложность реализации | Средняя | Средняя | Высокая |
Применение сегментации изображений
Уже сейчас сегментация изображений находит применение в самых разных сферах: от медицины и сельского хозяйства до ритейла и систем автономного транспорта. Вероятно, в будущем эта технология станет неотъемлемым инструментом и во многих других отраслях, открывая новые возможности для автоматизации и улучшения точности анализа изображений.
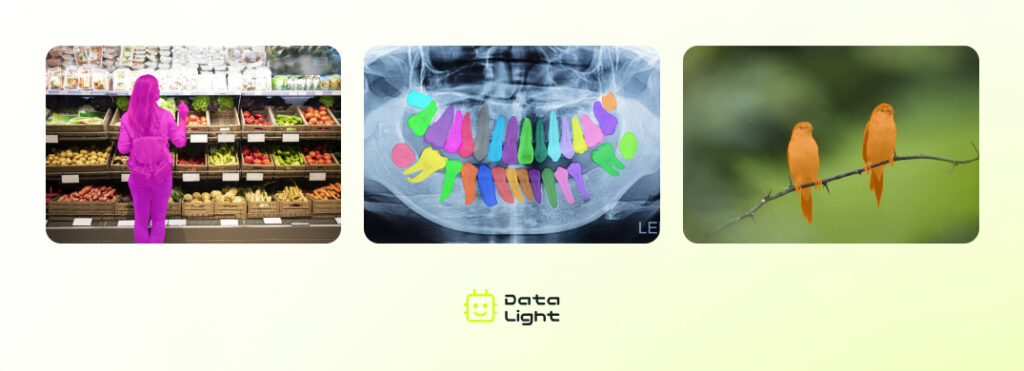
Медицина
В медицинской визуализации сегментация помогает врачам выделять и анализировать органы, ткани и патологические образования на снимках КТ, МРТ или рентгеновских изображениях. Например, с ее помощью можно точно определить размеры опухоли, измерить объемы повреждений или классифицировать тип аномалий в клеточных структурах.
Автономный транспорт
Сегментация изображений необходима для беспилотных автомобилей, чтобы анализировать дорожную обстановку. Она помогает выделять полосы движения, распознавать пешеходов, транспорт, дорожные знаки и элементы городской среды, такие как здания или деревья. Это обеспечивает точное и безопасное поведение автомобиля на дороге.
Сельское хозяйство
В сельском хозяйстве алгоритмы сегментации помогают оценивать состояние посевов и выявлять пораженные растения. Это упрощает мониторинг урожая и позволяет быстрее реагировать на угрозы, такие как болезни или вредители.
Экологический мониторинг
В проектах по сохранению природы сегментация используется для отслеживания животных в их естественной среде. Например, она позволяет определять размеры популяции, отслеживать перемещение видов и фиксировать изменения в экосистемах.
Ритейл и анализ покупательского поведения
В розничной торговле сегментация применяется для анализа видео с камер наблюдения. Она помогает отслеживать движение покупателей и их интерес к товарам. Кроме того, алгоритмы сегментации упрощают управление товарными запасами, позволяя автоматически распознавать заполненность полок и выявлять недостающие позиции.
Сегментация изображений с помощью ИИ
Сегментация изображений с использованием искусственного интеллекта — это сложный процесс, который позволяет компьютерам интерпретировать изображения с удивительной точностью. Но как это работает?
Ранее для сегментации изображений применялись простые методы обработки изображений, такие как пороговое преобразование и алгоритмы кластеризации (например, K‑means). Эти подходы показывали хорошие результаты на простых изображениях, но их эффективность резко снижалась при работе со сложными сценами.
С развитием искусственного интеллекта и в частности глубокого обучения сегментация сделала огромный шаг вперед. Современные методы основываются на применении мощных нейронных сетей, способных анализировать изображения на уровне, сопоставимом с человеческим восприятием. Среди них:
- U‑Net — модель, широко используемая в биомедицинской визуализации. U‑Net имеет симметричную структуру энкодер-декодер: энкодер сжимает изображение, выделяя ключевые признаки, а декодер восстанавливает его, создавая сегментированную карту.
- Mask R‑CNN — мощная модель для инстанс-сегментации, которая не только выделяет границы объектов, но и классифицирует отдельные экземпляры.
- DeepLab — модель, разработанная Google для задач семантической сегментации. Она использует расширенные свертки (Atrous Convolution), что позволяет анализировать изображения с высоким разрешением.
- SegNet — это еще одна модель энкодер-декодер, которая делает акцент на точности декодирования. Она сохраняет пространственную информацию, что особенно важно для задач, где необходимо четкое выделение границ объектов.
Однако для достижения высокой точности сегментации важнейшую роль играет не только выбор модели, но и качество данных, на которых она обучается. О подготовке таких данных мы поговорим в следующем разделе.
Подготовка данных для сегментации изображений
Для того чтобы модель сегментации могла эффективно выполнять свою задачу, ее необходимо обучить на размеченных данных. Эти данные представляют собой изображения, на которых указано, какие объекты на них находятся и где именно они расположены.
Для большинства проектов в области компьютерного зрения можно использовать открытые наборы данных, такие как COCO, Cityscapes, Open Images Dataset V7, которые содержат тысячи уже размеченных изображений.

Тем не менее, открытые датасеты не всегда могут полностью удовлетворить потребности специфических проектов. Если задача состоит в сегментации объектов, которые не встречаются в общедоступных датасетах, например, редких видов растений, возникает необходимость в создании собственного набора данных. Этот процесс состоит из двух основных этапов: сборе данных и их разметке.
Сбор изображений
Первым шагом в процессе подготовки данных для сегментации является сбор изображений. Эти изображения могут быть получены различными способами: с помощью камер, дронов, спутников или же из открытых баз данных. Важно, чтобы изображения были разнообразными. Это значит, что необходимо учесть различные условия освещенности, углы обзора и фоновое окружение, чтобы модель могла учиться распознавать объекты в самых разных ситуациях.
Ручная разметка с помощью полигонов
Следующим шагом в подготовке данных является разметка изображений. Для обучения модели сегментации необходима точная разметка изображений, которая выполняется с использованием полигонов.
Как это делается:
- Выбор объекта. На изображении идентифицируются элементы, которые необходимо сегментировать, например, автомобили, деревья или здания.
- Создание точек полигона. С помощью выбранного инструмента разметки пользователь последовательно кликает по границам объекта, создавая вершины полигона. Чем больше точек используется, тем точнее контур повторяет форму объекта.
- Замыкание полигона. После выделения всех точек необходимо завершить полигон, замкнув его, соединив последнюю точку с первой. При необходимости можно добавить дополнительные атрибуты, такие как класс объекта.
- Проверка и корректировка. Завершающим этапом является проверка точности полигона. Если в процессе добавления вершин были допущены ошибки, необходимо скорректировать расположение точек, чтобы форма полигона была максимально точной.
Ключевые выводы
Сегментация изображений — важнейший инструмент в области компьютерного зрения, позволяющий компьютерам «видеть» и интерпретировать объекты на изображении так, как это делает человек. Существуют разные виды сегментации: семантическая, инстанс- и паноптическая, каждая из которых решает свои задачи и применяется в конкретных сценариях.
Однако вне зависимости от целей проекта для обучения моделей необходимы качественные размеченные данные. Именно поэтому процесс подготовки данных, будь то использование открытых датасетов или создание собственных, играет центральную роль в развитии современных технологий.