 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыВ современном мире, где машинное обучение активно используется для решения задач компьютерного зрения, качество подготовки данных играет решающую роль. При этом одной из наиболее сложных и востребованных задач является семантическая разметка (Semantic Segmentation), на основе которой модели учатся глубже понимать содержимое изображений.
В этой статье мы рассмотрим, что представляет собой разметка Semantic Segmentation, в чём её особенности и в каких проектах она применяется.
Что такое Semantic Segmentation?
Semantic Segmentation — это вид разметки данных, позволяющий моделям машинного обучения анализировать, какие объекты находятся на изображении, определять их точные границы и местоположение.
Для этого изображение разделяется на сегменты с помощью масок — графических областей, которые соответствуют различным объектам и точно повторяют их форму. Каждому такому сегменту, состоящему из множества пикселей, присваивается определённая метка, указывающая на то, к какому классу эти пиксели и объекты принадлежат.
Особенности Semantic Segmentation
Особенностью семантической разметки является то, что объекты одного класса не разделяются на отдельные экземпляры (в отличие от Instance Segmentation), поэтому все пиксели, принадлежащие к одному классу, получают одинаковые метки и маски.
Например, если на изображении присутствуют две собаки, то они обе будут отнесены к классу «собака» и им будут присвоены одинаковые метки и маски.

Таким образом, Semantic Segmentation идеально подходит для задач, где требуется определение и классификация объектов на уровне пикселей, но она ограничена в задачах, требующих их разделения и индивидуального анализа.
Ещё одна не менее важная особенность этого вида разметки состоит в том, что она нацелена на классификацию пикселей только тех объектов, которые важны для конкретной задачи. Например, если в условии задачи заданы классы «дорога», «машина», «здание», то только пиксели, относящиеся к этим классам, будут размечены. Остальные пиксели, принадлежащие к другим классам, могут быть размечены как «фон» или не размечаться вообще.
Чем отличается Semantic Segmentation от других видов разметки данных?
Чтобы лучше понять, как работает Semantic Segmentation, сравним наглядно этот вид разметки с Object Detection, Instance Segmentation и Panoptic Segmentation на примере задачи, где нужно выделить людей на фоне пейзажа.
- Object Detection и Semantic Segmentation
Самый простой способ выделить людей на изображении — это использовать Object Detection.
С помощью этого вида разметки мы заключаем интересующие нас объекты в рамки (bounding boxes) и присваиваем им соответствующую метку «человек». Но, как мы видим, эти рамки захватывают дополнительные детали окружения и дают лишь приблизительную информацию о местоположении объектов без учёта их границ.
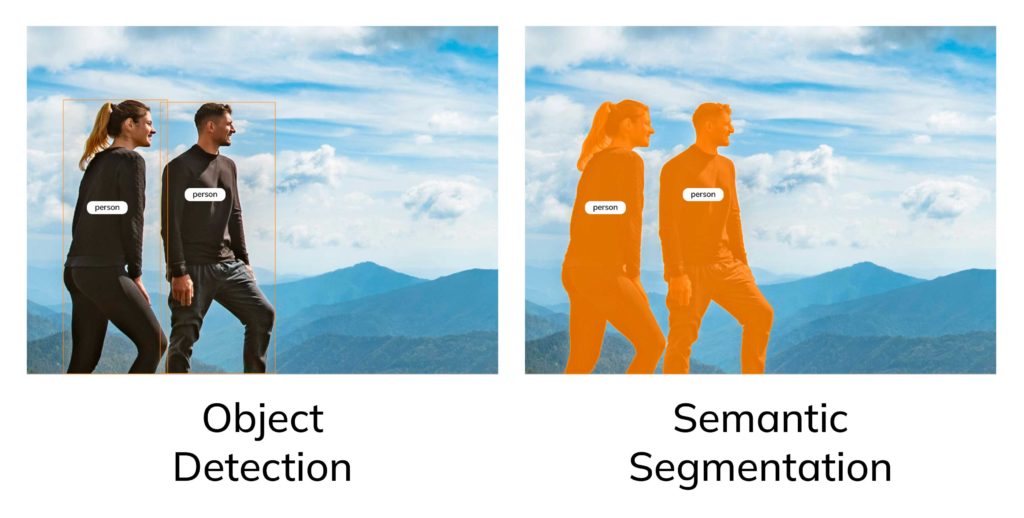
Semantic Segmentation, в отличие от Object Detection, решает эту проблему тем, что позволяет выделить нужные объекты с помощью масок, точно повторяющих их контуры. На нашем примере, где мы выделяем только объекты класса «человек», эта маска будет единственной и общей (одного цвета).
- Instance Segmentation и Semantic Segmentation
Если же сравнить Semantic Segmentation с Instance Segmentation, то эти виды разметки покажутся очень похожими, поскольку с их помощью мы можем одинаково точно выделить границы объектов.

Единственное ключевое отличие между ними состоит в том, что Instance Segmentation позволяет дополнительно разделять объекты, принадлежащие к одному классу. Для этого вместо общей маски и метки им присваиваются уникальные, например, человек 1 и человек 2.
- Panoptic Segmentation и Semantic Segmentation
В свою очередь Panoptic Segmentation объединяет принципы работы Semantic Segmentation и Instance Segmentation и обеспечивает наиболее полное понимание всей визуальной сцены.
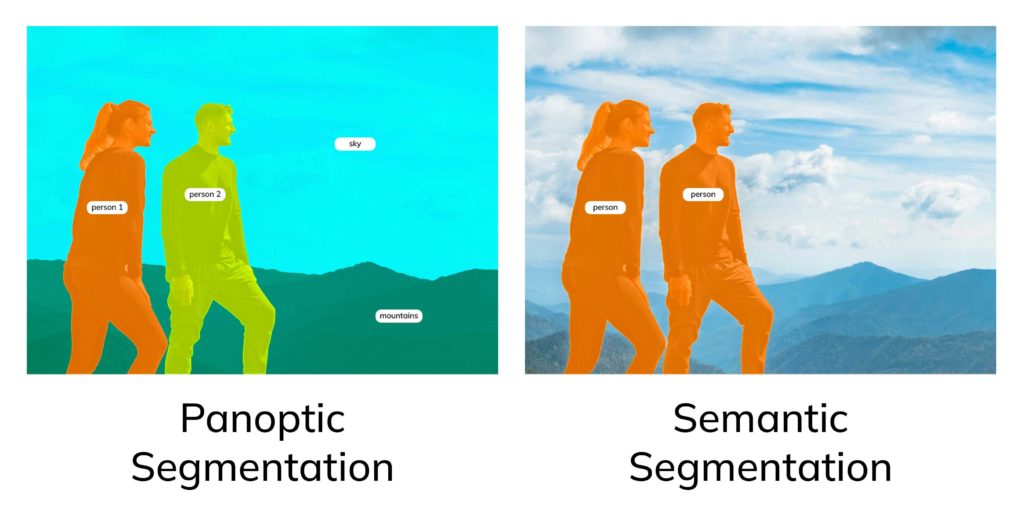
С помощью этого вида разметки мы выделяем фигуры людей как отдельные объекты, используя разные маски и метки (как в случае с Instance Segmentation), а также выделяем фоновые объекты, не разделяя их на отдельные экземпляры (как в случае с Semantic Segmentation).
Ручная и автоматическая разметка Semantic Segmentation
Разметка Semantic Segmentation может выполняться как вручную, так и автоматически. Этот выбор во многом зависит от требований проекта, сроков его реализации, доступных ресурсов и объёма данных. Рассмотрим ключевые аспекты этих процессов, а также поговорим о популярных инструментах и моделях для разметки.
Ручная разметка
Ручная семантическая разметка представляет собой процесс, во время которого разметчики вручную выделяют границы объектов на изображении, присваивая каждому пикселю метки и маски, соответствующие классу объекта.
Хотя этот метод является трудоёмким и требует значительных временных затрат, он обеспечивает высокую точность разметки в сложных сценах, где объекты могут перекрывать друг друга или иметь нестандартные формы.
Инструменты для ручной разметки Semantic Segmentation:
- Computer Vision Annotation Tool (CVAT) — популярный опенсорс-инструмент с удобным интерфейсом, поддерживающий различные виды разметки, включая Semantic Segmentation. Предлагает возможность групповой работы и гибкие настройки проектов.
- VGG Image Annotator (VIA) — бесплатный и лёгкий инструмент для разметки изображений и видео, разработанный Оксфордским университетом. Поддерживает различные типы аннотаций, включая Semantic Segmentation, и не требует установки.
- RectLabel — инструмент для разметки изображений на macOS. Предлагает интуитивно понятный интерфейс, который позволяет пользователям быстро создавать аннотации для изображений и видео, и поддерживает различные форматы экспорта, что облегчает интеграцию с другими инструментами и фреймворками для машинного обучения.
Автоматическая разметка
Автоматическая разметка предполагает использование предобученных моделей, которые могут автоматически сегментировать изображения. Это существенно ускоряет процесс разметки, но в то же время делает её результаты менее точными и требующими дополнительной проверки для достижения лучших результатов.
Популярные модели для автоматической разметки Semantic Segmentation:
- DeepLab — одна из самых популярных архитектур для сегментации, основанная на сверточных нейронных сетях (CNN).
- U‑Net — модель для сегментации, используемая преимущественно для работы с медицинскими изображениями.
- FCN (Fully Convolutional Networks) — модель, основанная на полносверточных нейронных сетях, специально разработанная для сегментации изображений.
Гайд по разметке Semantic Segmentation в CVAT
Шаг 1: Создание проекта
Пройдите авторизацию в CVAT и откройте вкладку Projects на главной странице. Нажмите на кнопку + и выберите Create a new project, чтобы создать новый проект.
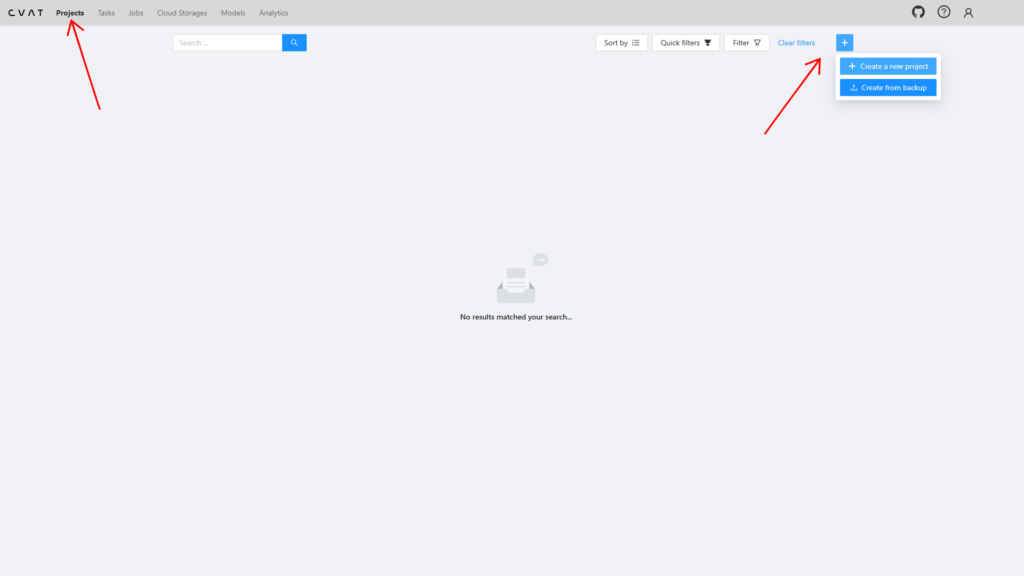
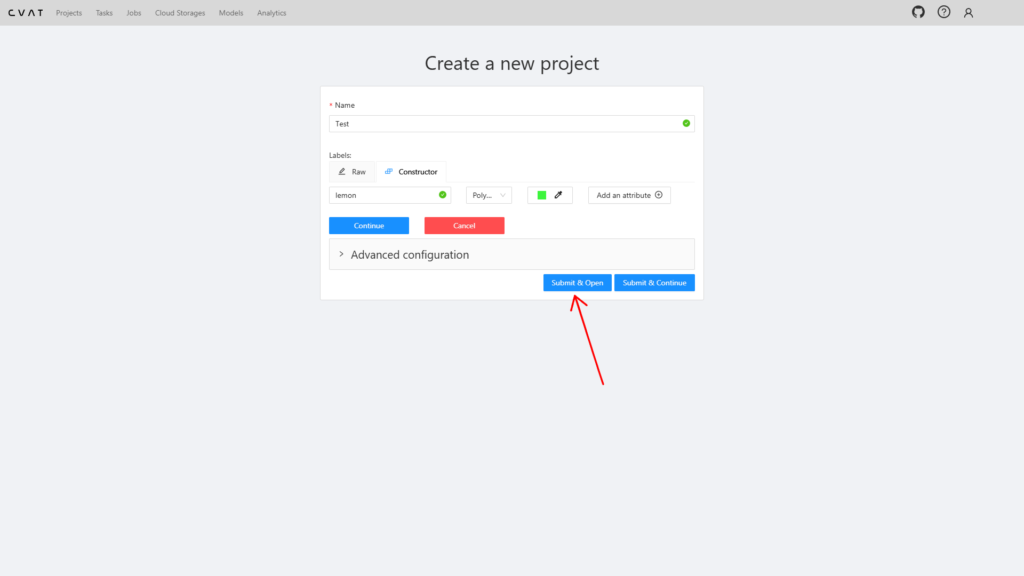
Перед вами откроется окно проекта. Присвойте ему название, которое будет его описывать.
Затем нажмите на кнопку Add label. В открывшемся разделе вы сможете выбрать инструмент для разметки (для Semantic Segmentation это Polygon) и задать параметры лейбла, которые включают в себя название метки и цвет маски, присваиваемые объекту.
Обратите внимание, что в случае разметки Semantic Segmentation вам нужно создать лейблы для каждого класса объектов без учёта отдельных экземпляров.
Например, в этом гайде мы покажем, как разметить изображение, на котором есть 2 лимона и 2 апельсина. Для этой задачи мы создали 2 лейбла:
- Лимон — Polygon — Зеленый.
- Апельсин — Polygon — Голубой.
После того, как вы настроили лейблы для разметки своего изображения, нажмите Submit & Open.
Шаг 2: Создание задачи
Теперь необходимо перейти к созданию задачи, для этого нажмите на + и выберите Create a new task.
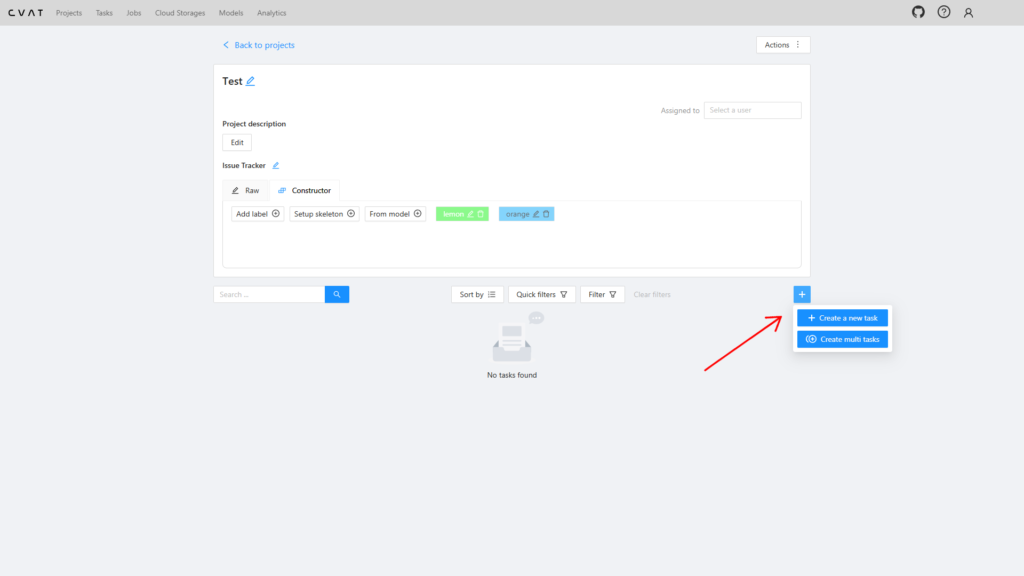
Присвойте задаче название, а затем загрузите изображения, которые нужно разметить. Вы можете загрузить их в формате ZIP или добавить по отдельности.
После загрузки снова нажмите Submit & Open.
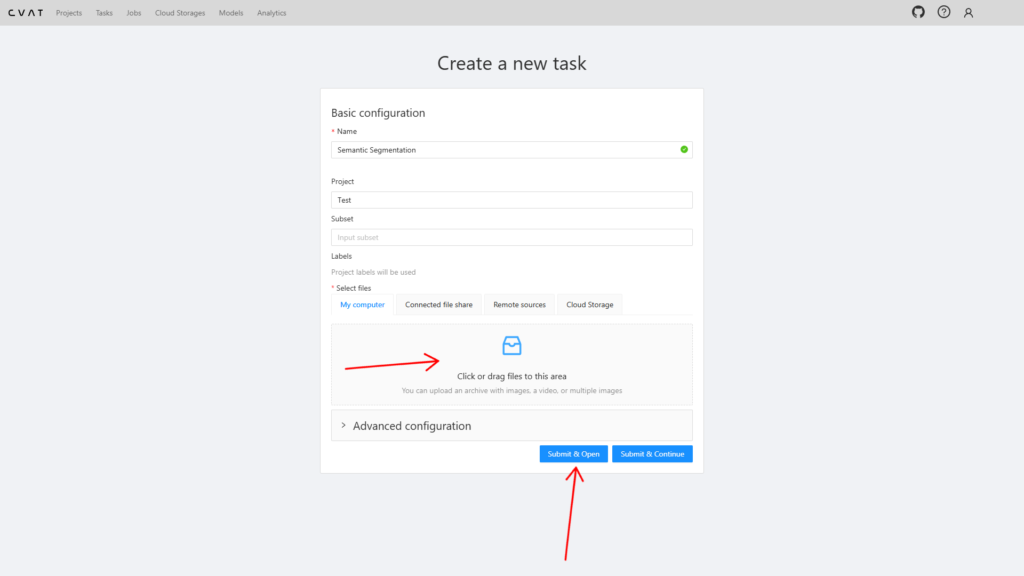
Шаг 3: Разметка изображения
Перед вами откроется основной интерфейс разметки в CVAT. Чтобы начать разметку, выберите инструмент Polygon в боковой панели и укажите лейбл, который будет соответствовать выбранному вами классу объектов.
С помощью инструмента Polygon начните обводить контур объекта на изображении. Вы можете делать это с помощью кликов, нажимая ЛКМ, или плавно обводить объект с помощью курсора, зажав Shift. Для того, чтобы удалить неверно созданную точку, нажмите ПКМ.
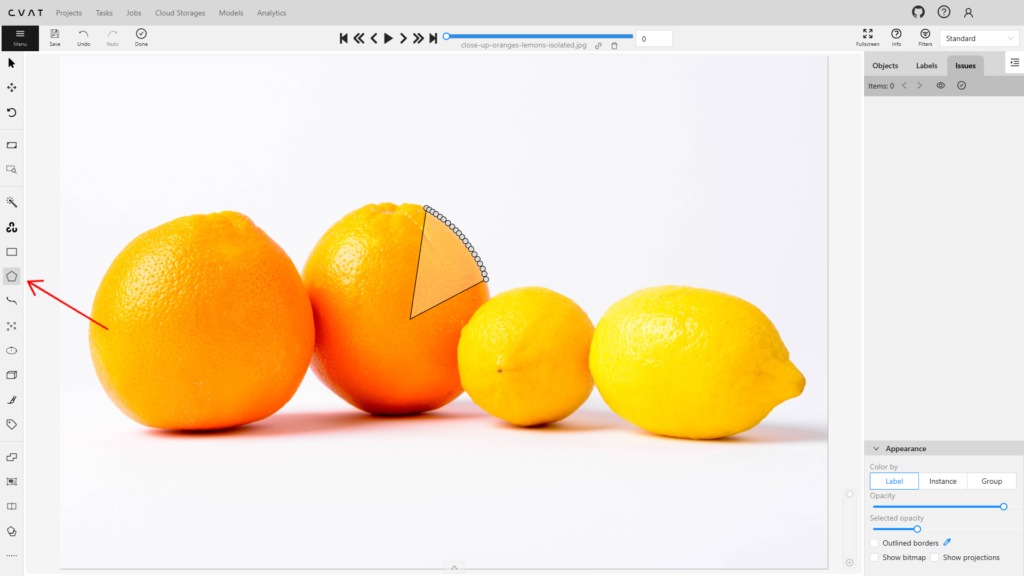
Когда вы закончили разметку объекта, нажмите в верхней панели Done или горячую клавишу N, чтобы замкнуть контур и создать маску.
Повторите этот процесс со всеми объектами на изображении, используя соответствующие лейблы («лимон» для всех лимонов, «апельсин» для всех апельсинов).
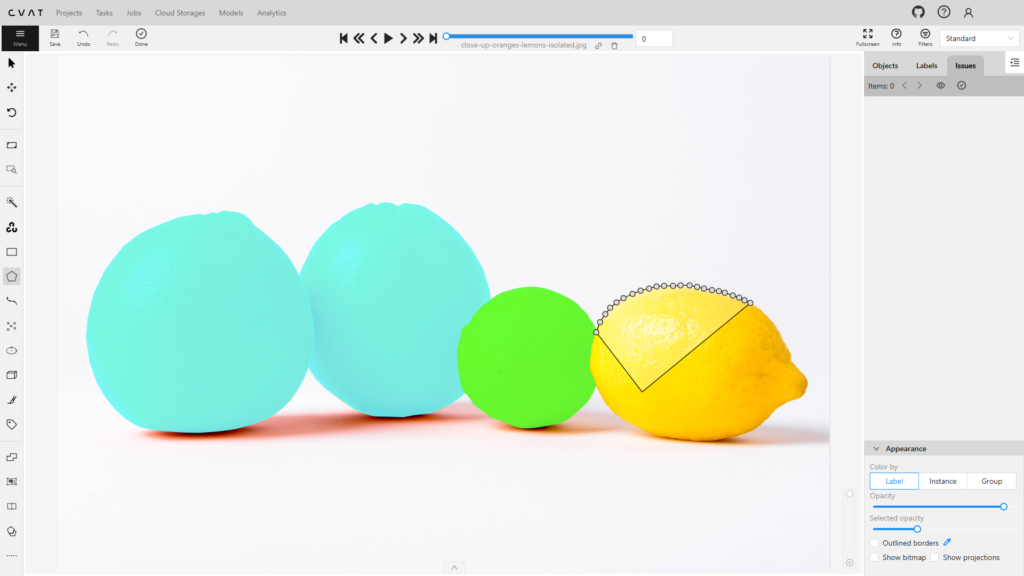
Шаг 4: Сохранение
После завершения разметки изображения сохраните изменения с помощью кнопки Save.
Шаг 5: Экспорт
Чтобы экспортировать результаты, нажмите Menu → Eхport job dataset и выберите нужный формат для сохранения.
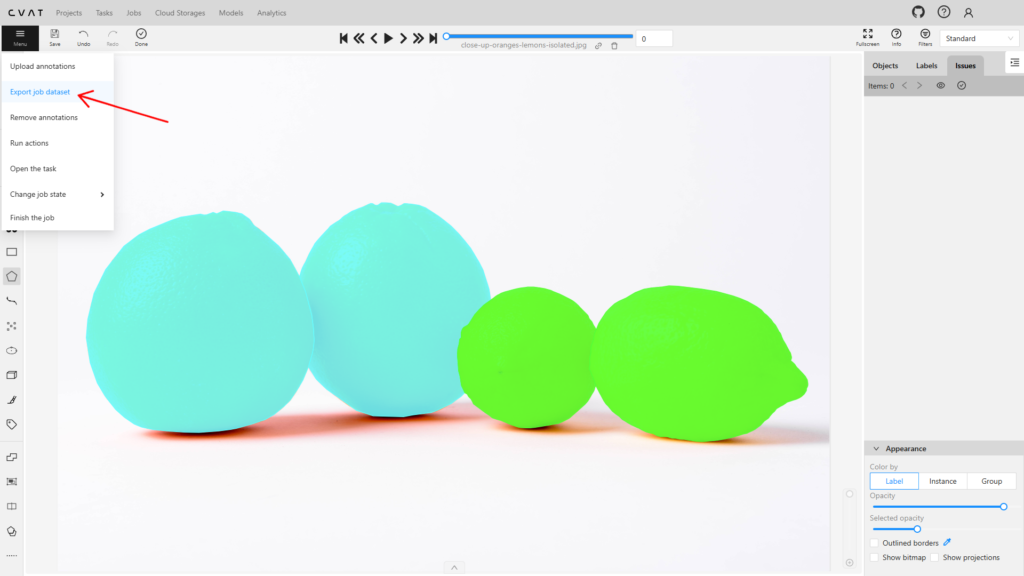
Готово!
Теперь вы можете использовать полученные аннотации для обучения ML-моделей.
Где используется Semantic Segmentation?
Semantic Segmentation широко используется во многих отраслях благодаря своей способности детально анализировать и классифицировать объекты на изображениях. Рассмотрим основные сферы её применения.
Транспорт
Технологии автопилота используют Semantic Segmentation для распознавания дорог, пешеходов, транспортных средств и других объектов на дороге. Это позволяет беспилотным автомобилям «видеть» и понимать окружающую обстановку, принимать решения в реальном времени и минимизировать риски аварий.
Медицина
В медицине Semantic Segmentation играет важную роль в анализе медицинских изображений, таких как МРТ и КТ. Она помогает точно выделять и сегментировать различные органы и ткани, что значительно облегчает диагностику опухолей и других патологий.
Сельское хозяйство
Semantic Segmentation также применяется в сельском хозяйстве. Например, она помогает анализировать снимки полей с дронов для точного определения состояния растений, выделения здоровых и больных участков, прогнозирования урожайности.
Анализ спутниковых изображений
Анализ спутниковых снимков с использованием Semantic Segmentation позволяет выделять участки земли, водоёмы, леса и другие типы территорий для создания карт, а также для мониторинга изменений окружающей среды.
Системы поиска изображений
Эта технология также находит применение в системах поиска изображений по содержимому. Она позволяет автоматически выделять ключевые элементы, идентифицировать объекты и находить схожие изображения на основе их визуальных характеристик, что делает поиск более точным и релевантным.
Виртуальные примерочные
Наконец, Semantic Segmentation активно применяется в технологиях дополненной реальности (AR). Ярким примером этого является создание виртуальных примерочных, которые дают возможность пользователям «примерять» одежду онлайн перед покупкой, используя свои фотографии или видеозаписи. Это не только улучшает пользовательский опыт, но и снижает количество возвратов купленных товаров и повышает удовлетворённость клиентов.
Ключевые выводы
Semantic Segmentation — это вид разметки данных, который позволяет моделям машинного обучения анализировать изображения на уровне пикселей. Она классифицирует объекты, не разделяя их на экземпляры, и используется в самых разных сферах: от автономного вождения до медицины.
Разметка данных для этой задачи может выполняться как вручную, так и автоматически, и выбор метода зависит от целей и ресурсов проекта. Ручная разметка обеспечивает высокую точность, но требует значительных временных затрат, в то время как автоматические модели предоставляют возможность быстро обрабатывать большие объёмы данных, но могут уступать в точности. Оптимальный подход часто заключается в комбинировании методов для достижения наилучших результатов.