 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыЧто такое синтетические данные?
Синтетические данные — это искусственно созданные данные, которые генерируются с помощью алгоритмов и моделей для имитации реальных данных. Эти данные сохраняют статистические и структурные свойства реальной информации, но при этом не содержат фактических сведений из окружающего мира. Например, это могут быть сгенерированные фотографии людей, которых в реальности никогда не существовало.

Зачем нужны синтетические данные?
Синтетические данные широко применяются в разработке моделей машинного обучения, особенно в тех случаях, когда реальных данных недостаточно, их трудно собрать или они конфиденциальны. Также синтетические данные помогают моделировать редкие или потенциально опасные ситуации, которые трудно воспроизвести в реальной среде, но они могут быть важны для обучения моделей.
Например, представьте, что вы создаете систему безопасности для банка, способную распознавать подозрительное поведение посетителей. Для этого необходимы записи множества ситуаций: обычные дни и взаимодействия с сотрудниками, внезапные перемещения, подозрительные действия. Однако реальных записей может быть недостаточно, и, к тому же, такие данные могут быть конфиденциальными и потому недоступными для распространения и использования. Синтетические данные предлагают решение: можно создать виртуальные видеозаписи с имитацией действий, необходимых для тренировки алгоритма.
В настоящее время синтетические данные являются перспективной альтернативой реальным данным и используются не только в банках и финансовых организациях, но и в других, самых разных сферах. Так, в медицине они помогают моделировать редкие заболевания, которые трудно изучить на реальных пациентах; в автомобильной промышленности — тестировать автономные автомобили в сложных дорожных условиях; в сфере обслуживания — обучать чат-ботов.
Преимущества синтетических данных
1. Решение проблемы недостатка данных
В проектах машинного обучения успех модели напрямую зависит от объема и разнообразия данных, на которых она обучается. Однако собрать нужное количество данных бывает сложно, особенно если речь идет о редких или необычных ситуациях. В таких случаях синтетические данные позволяют дополнить обучающий набор за счет сгенерированных изображений, видео и других форматов данных.
Пример: Для обучения модели распознавания аварий на дорогах требуется обширный набор изображений различных ДТП. Однако сбор такого рода данных ограничен редкостью событий и этическими соображениями. Синтетические данные помогают решить эту проблему, благодаря чему модель может обучаться на множестве сценариев.
2. Решение проблемы дисбаланса классов
В реальных наборах данных часто встречается дисбаланс классов — ситуация, когда один класс объектов или сценариев представлен гораздо реже других. Синтетические данные позволяют генерировать примеры для недостаточно представленных классов, что помогает сбалансировать обучающий набор и повысить точность модели.
Пример: В задачах по обнаружению мошенничества с кредитными картами реальные случаи мошенничества встречаются гораздо реже, чем легитимные транзакции. Синтетические данные позволяют создать дополнительные примеры мошеннических операций.
3. Снижение затрат и ускорение процесса сбора данных
Сбор реальных данных — трудоемкий и дорогостоящий процесс. Синтетические данные можно создать быстрее и с меньшими затратами, чем собирать и обрабатывать огромные массивы реальной информации.
4. Защита конфиденциальности и безопасности данных
Некоторые данные слишком чувствительны, чтобы использовать их в обучении моделей. Например, персональные медицинские или финансовые данные могут быть защищены законами о конфиденциальности. Синтетические данные могут имитировать такие данные без риска раскрытия личной информации.
Таким образом, синтетические данные — это эффективный и безопасный способ решить задачи, связанные с недостатком данных, дисбалансом классов, затратами и защитой конфиденциальности.
Классификация синтетических данных
Синтетические данные могут могут быть представлены в различных форматах, что делает их универсальным инструментом в проектах машинного обучения.
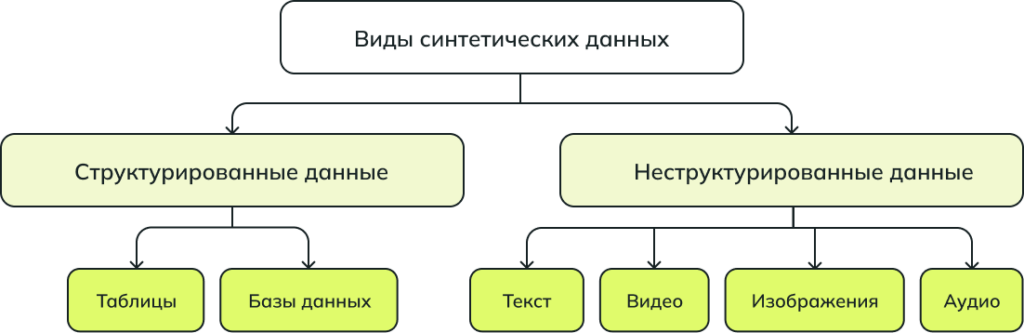
Кроме того, синтетические данные можно условно разделить на два основных типа в зависимости от их происхождения и степени сходства с реальными данными: полностью синтетические и частично синтетические данные.
Полностью синтетические данные — это данные, созданные с нуля с помощью алгоритмов и математических моделей. Они полностью независимы от реальных данных и не содержат никаких фактических значений. Вместо этого они моделируют закономерности, характерные для реальных данных, но сами по себе являются новыми и уникальными.
Для их генерации специалисты анализируют статистические свойства реальных данных, такие как распределение значений, средние и медианные значения, корреляции между признаками и другие характеристики. Например, если нужно синтезировать данные о продажах, создается математическая модель, учитывающая популярность товаров, сезонные колебания. Используя эту модель, можно генерировать данные, которые имитируют поведение клиентов и их покупательские привычки, без прямого использования реальных данных о покупках.
Частично синтетические данные представляют собой гибрид реальных и искусственно созданных данных. В данном случае часть набора данных остается реальной, а недостающие или конфиденциальные элементы заменяются синтетическими значениями. Это позволяет сохранить основные характеристики исходной информации, избегая раскрытия конфиденциальных данных.
Например, если у компании есть реальные данные о демографии своих клиентов, но отсутствуют сведения о покупательском поведении, специалисты могут заполнить эти пробелы за счет сгенерированных синтетических данных, основываясь на статистических моделях или других наблюдениях.
Выбор между полностью и частично синтетическими данными зависит от доступности реальных данных и целей проекта. Если реальные данные недоступны или содержат слишком много конфиденциальной информации, используются полностью синтетические данные. Если же есть необходимость сохранить часть реальной информации, используются частично синтетические данные, где конфиденциальная информация заменяется синтетическими аналогами.
Как создаются синтетические данные?
В зависимости от цели и требуемого типа, синтетические данные могут создаваться с помощью статистических методов, агентного моделирования и алгоритмов глубокого обучения.
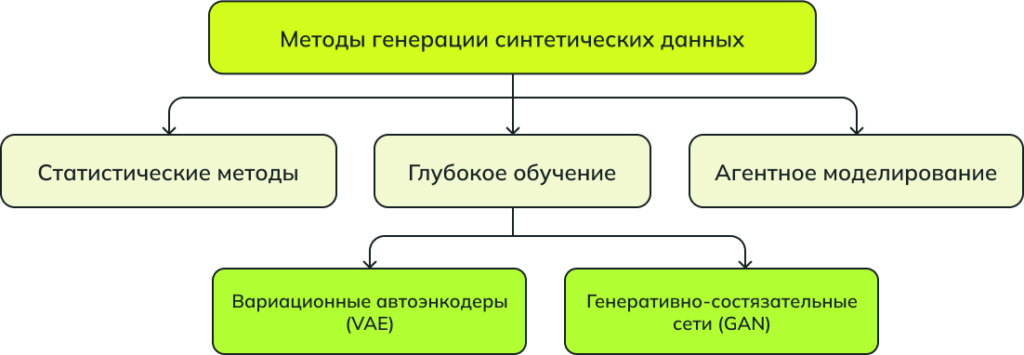
1. Статистические методы
Статистические методы генерации данных основываются на анализе распределений, зависимостей и других статистических характеристик реальных данных. Главная цель этих методов — изучить структуру реальных данных и на этой основе генерировать новые.
Одним из наиболее распространенных подходов является метод Монте-Карло, использующий случайные выборки из заданных распределений для имитации реальных данных. Например, если известны вероятности определенных событий, этот метод позволяет сгенерировать синтетический набор данных, где частота каждого события соответствует исходной статистике. Такой подход активно применяется в финансовом моделировании, управлении рисками и прогнозировании.
Если задача требует моделирования сложных взаимозависимостей между несколькими переменными, применяются более продвинутые методы, такие как копулы. Они позволяют смоделировать многомерные зависимости и создавать более реалистичные данные для сложных систем.
Применение
- Финансовое моделирование: генерация данных о ценах, доходах и транзакциях с использованием анализа исторических распределений.
- Медицина: создание синтетических наборов показателей здоровья пациентов.
- Метеорологические исследования: генерация данных о температуре, уровне осадков и скорости ветра для моделирования климатических изменений.
2. Агентное моделирование
Агентное моделирование — это метод создания синтетических данных путем симуляции поведения множества агентов, таких как люди, животные, автомобили и другие объекты, которые следуют заранее заданным правилам. Этот подход используется для воспроизведения сложных динамических процессов и получения данных, которые отражают реальные взаимодействия в различных средах.
Примером агентного моделирования может быть симуляция движения покупателей в супермаркете. В этом случае агенты — покупатели, чья цель — выбрать товары и пройти к кассе. Правило поведения агентов — избегать столкновений с другими людьми. Такой подход позволяет генерировать данные о перемещении покупателей, моделируя плотность потоков, время, проведенное в разных зонах магазина, а также их взаимодействия.
Применение
- Маркетинг: моделирование поведения потребителей для тестирования различных маркетинговых стратегий, прогнозирования спроса и оптимизации рекламных кампаний.
- Беспилотные автомобили: симуляция движения транспортных средств и их взаимодействий с учетом множества факторов (светофоры, дорожные знаки, погодные условия и т. д.).
- Производственные процессы: моделирование работы сотрудников и машин на производственных линиях для повышения эффективности, минимизации времени простоя и оптимизации логистики.
3. Глубокое обучение
Глубокое обучение позволяет создавать сложные синтетические данные с помощью таких моделей, как вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN). Эти методы особенно популярны в компьютерном зрении (CV) и задачах обработки естественного языка (NLP), где важна высокая степень схожести с реальными данными.
Вариационные автоэнкодеры (Variational Autoencoder): VAE — это модели, которые сжимают (кодируют) данные в компактное представление, а затем восстанавливают (декодируют) их обратно, создавая синтетические данные, похожие на исходные. Эта технология часто используется для создания изображений или текстов, которые сохраняют основные черты оригинала, но не копируют его.
Генеративно-состязательные сети (Generative Adversarial Network): GAN представляют собой пару сетей — генератор и дискриминатор. Генератор создает синтетические данные, а дискриминатор оценивает, насколько они похожи на реальные. Обе сети тренируются вместе: генератор стремится создавать более правдоподобные данные, а дискриминатор учится их различать. В результате GAN могут создавать очень реалистичные синтетические данные.
Применение
- Обнаружение объектов в компьютерном зрении: создание синтетических изображений для тренировки моделей, которые могут обнаруживать и классифицировать объекты на реальных снимках.
- Обучение чат-ботов и виртуальных помощников: генерация синтетических диалогов и текстов для тренировки моделей обработки естественного языка.
Распознавание речи: создание синтетических звуковых данных для тренировки моделей, которые могут распознавать и интерпретировать речь.
Синтетические данные и аугментация данных
Когда речь идет о необходимости расширения обучающих наборов данных, важно рассмотреть два ключевых подхода — аугментацию данных и создание синтетических данных. Оба метода нацелены на решение схожих задач, но принципы их работы существенно отличаются.
Аугментация данных — это метод расширения существующего набора данных путем внесения небольших изменений в уже имеющиеся данные. Например, для изображений это может быть поворот, изменение масштаба, добавление шума, зеркальное отображение. Для текстовых данных — синонимизация или перефразирование. Аугментация позволяет увеличить объем данных и, таким образом, улучшить устойчивость моделей без необходимости сбора или создания дополнительных данных.

Синтетические данные — это искусственно созданные данные, полностью сгенерированные с нуля. Эти данные не являются измененными версиями существующих реальных данных и создаются при помощи алгоритмов и моделей, которые имитируют свойства настоящей информации. Они предназначены для замены или дополнения реальных данных в тех случаях, когда доступ к ним ограничен или когда требуется создать редкие сценарии.
Основные параметры качества синтетических данных
Качество синтетических данных — это ключевой фактор, определяющий, насколько успешно они могут заменить или дополнить реальные данные в обучении моделей. Рассмотрим основные параметры, которые определяют их качество.
Сходство с реальными данными
Синтетические данные должны быть максимально близкими к настоящим по своим статистическим характеристикам. Это может включать такие параметры, как среднее значение, дисперсия, распределение и корреляции между переменными. Если синтетические данные значительно отклоняются по этим показателям от реальных, то модели, обученные на них, могут выдавать ошибочные результаты.
Разнообразие данных
Для успешного обучения модели данные должны содержать различные примеры, что помогает охватить большее число возможных сценариев и улучшить обобщающую способность модели. Слишком узкий или однородный набор данных может привести к переобучению и снижению точности модели при работе с новыми данными.
Отсутствие искажений и аномалий
Синтетические данные не должны содержать аномалий, нехарактерных для реальных данных, которые могут внести искажения в обучение модели. Если синтетические данные содержат такие аномалии, это может отрицательно сказаться на результатах обучения и работы модели.
Защита конфиденциальности
Если синтетические данные создаются на основе персональных данных, необходимо гарантировать, что они не позволяют идентифицировать реальные объекты. Важно, чтобы синтетические данные оставались анонимными, сохраняя при этом статистическую близость к реальным данным.
Ключевые выводы
Синтетические данные представляют собой мощный инструмент, который помогает решать множество задач в машинном обучении, от увеличения объема данных до моделирования сложных сценариев. Они искусственно создаются с помощью алгоритмов и сохраняют статистические и структурные свойства реальной информации, но при этом не содержат конфиденциальных или фактических данных.
Разнообразие методов их создания — от статистических подходов до глубокого обучения — позволяет адаптировать их под разные задачи и сферы. Таким образом, синтетические данные становятся неотъемлемой частью современного подхода к разработке и обучению моделей.