 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
Контакты
Что такое обучение с учителем?
Обучение с учителем (Supervised Learning) — это один из методов машинного обучения, при котором модель учится решать задачу, опираясь на примеры с уже известными ответами.
Представьте, что вы учите ребенка узнавать животных. Вы показываете ему картинки и называете: «Это кошка, это собака, это слон». Ребенок постепенно замечает различия и вскоре начинает самостоятельно узнавать животных.
В машинном обучении модель проходит довольно похожий путь. Для ее обучения используется заранее подготовленный набор данных, где каждому примеру соответствует правильный ответ — метка. Это может быть класс объекта, числовое значение или другая характеристика.
Такие данные называют размеченными. Именно они играют роль «учителя» — подсказывают алгоритму, какие закономерности стоит искать. Со временем модель учится делать предсказания и справляться с новыми, еще не встречавшимися данными. Например, распознавать объекты на фото в режиме реального времени.
Почему обучение с учителем так широко используется?
Обучение с учителем — один из самых популярных методов машинного обучения. Его широкое применение объясняется несколькими ключевыми преимуществами:
Прогностическая способность
Многие реальные задачи основаны на данных, где уже известны правильные ответы. Модели обучения с учителем используют эти данные, чтобы строить точные прогнозы и выявлять закономерности. Например:
- Предсказание цен на жилье на основе информации о площади, районе и других характеристиках.
- Фильтрация спама в электронной почте на основе предыдущих писем.
Понятность и интерпретируемость результатов
Некоторые алгоритмы (например, линейная регрессия) позволяют довольно просто понять, почему модель делает то или иное предсказание. Это особенно важно в таких сферах, как медицина и финансы, где решения должны быть прозрачными и объяснимыми.
- В банках модель показывает, почему клиент получил отказ по кредиту.
- В медицине алгоритм может указать, какие симптомы стали основанием для диагноза.
Универсальность применения
Алгоритмы с учителем применяются в огромном числе областей — от медицины и финансов до развлечений и маркетинга. Практически везде, где есть данные и необходимость прогнозировать, классифицировать или выявлять закономерности, обучение с учителем успешно решает задачи.
Как работает обучение с учителем?
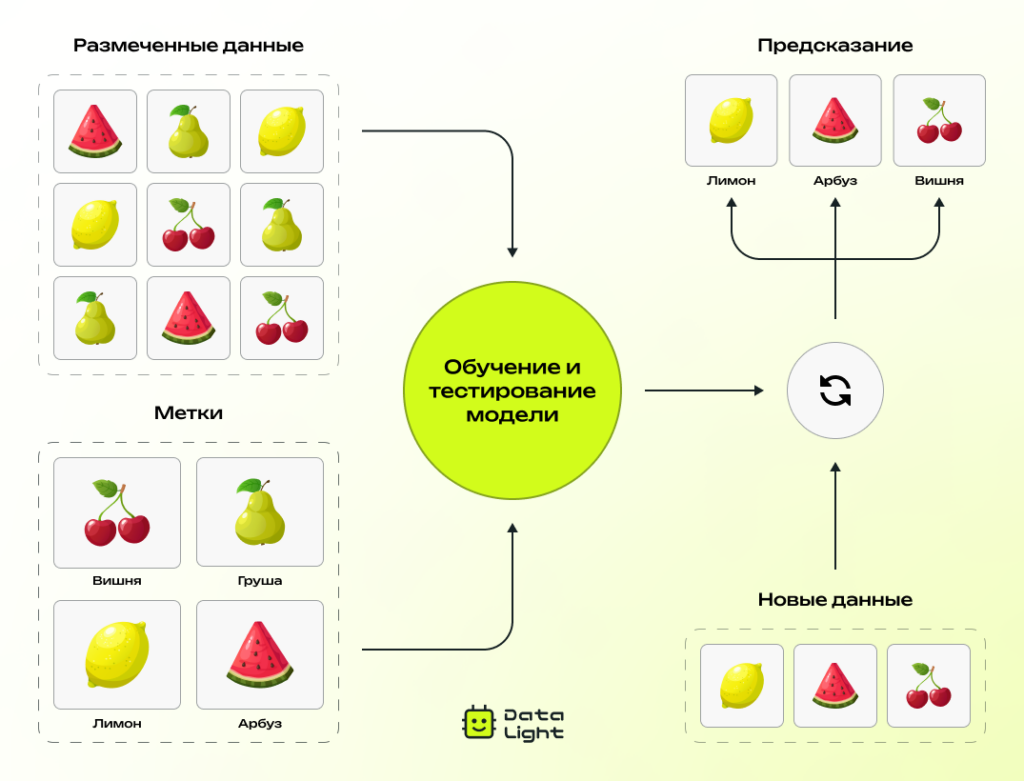
1. Подготовка данных
Прежде чем обучать модель, необходимо собрать и подготовить размеченные данные — примеры, в которых каждому входному объекту уже сопоставлен правильный ответ. На этом этапе данные очищают от выбросов и пропусков, нормализуют признаки при необходимости и устраняют несбалансированность классов.
2. Разделение данных на выборки
Данные делятся на три части:
- Обучающая выборка (~70–80%) — используется для тренировки модели.
- Валидационная выборка (~10–15%) — нужна для настройки гиперпараметров и предотвращения переобучения.
- Тестовая выборка (~10–20%) — предназначена для итоговой оценки качества уже обученной модели.
3. Выбор модели и обучение
В зависимости от задачи выбирается алгоритм:
- Регрессия — если нужно предсказывать числовое значение, например, цену квартиры.
- Классификация — если нужно определить категорию объекта, например, «кот» или «собака».
Во время обучения модель анализирует обучающую выборку, выявляет закономерности и находит зависимости между входными признаками и целевой переменной.
4. Оценка качества модели
После обучения модель тестируют на новой выборке, которую она раньше не видела. Это позволяет проверить, насколько хорошо она усвоила закономерности и умеет ли делать предсказания на новых данных.
Качество оценивают с помощью метрик:
- Accuracy — доля верно предсказанных ответов.
- Precision (точность) и Recall (полнота) — используются для оценки качества классификации.
- MSE (среднеквадратичная ошибка) — оценивает, насколько предсказания в задачах регрессии отклоняются от реальных значений.
5. Использование модели в реальных задачах
Когда модель показывает хорошие результаты, ее применяют для автоматического предсказания новых данных. Например:
- Почтовые сервисы фильтруют спам, распознавая подозрительные сообщения.
- Банки оценивают риск невозврата кредита на основе клиентской истории и других факторов.
- Онлайн-магазины формируют персонализированные рекомендации, анализируя поведение пользователя.
Основные задачи обучения с учителем
Задачи обучения с учителем делится на два основных типа: регрессию и классификацию.
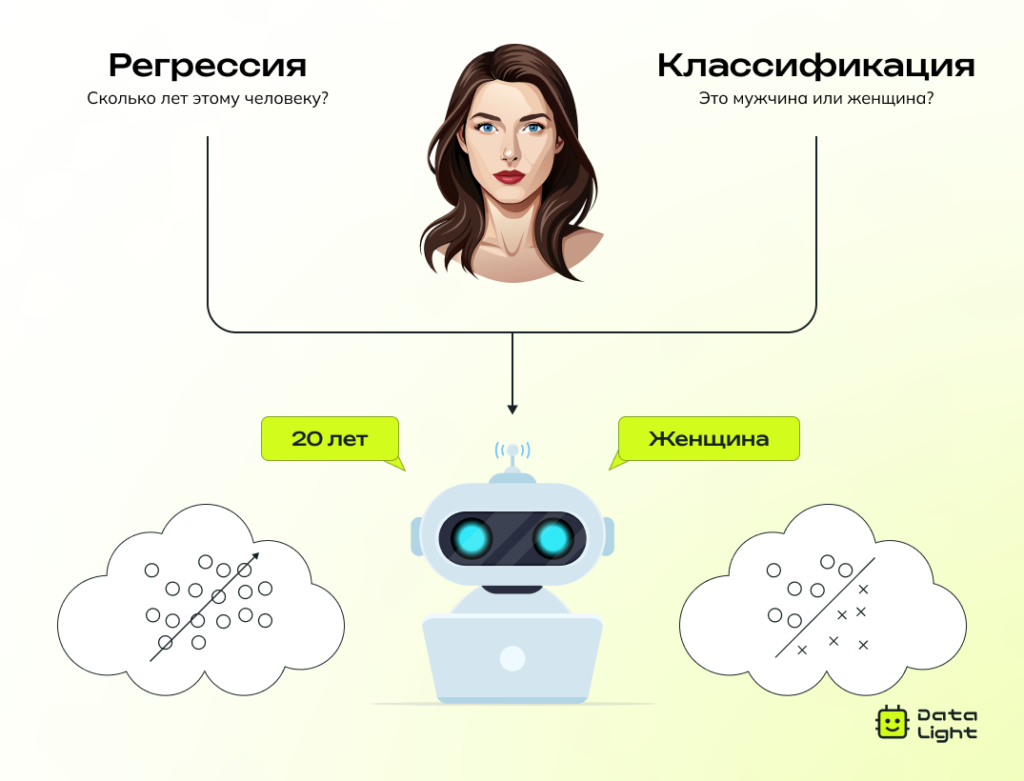
Регрессия
Регрессия применяется, когда модель должна предсказать числовое значение. Целевая переменная в таких задачах является непрерывной, то есть может принимать любые значения в заданном диапазоне.
Примеры задач регрессии:
- Определение уровня дохода человека на основе возраста, образования и опыта работы.
- Прогнозирование температуры воздуха.
- Оценка спроса на товар с учетом сезонных колебаний.
Классификация
Классификация используется, когда нужно отнести объект к одной из нескольких заранее определенных категорий. В таких задачах целевая переменная дискретна (принимает ограниченный набор значений).
Примеры задач классификации:
- Распознавание рукописных цифр или объектов на изображениях.
- Определение болезни на основе медицинских анализов.
- Классификация отзывов (положительные/отрицательные).
Алгоритмы обучения с учителем
Разные задачи требуют разных алгоритмов, каждый из которых имеет свои сильные и слабые стороны, а также наиболее подходящие сценарии использования.
Метод k ближайших соседей
Метод k ближайших соседей (k‑Nearest Neighbors, k‑NN) — один из самых простых алгоритмов машинного обучения. Он не требует сложных вычислений, а его идея интуитивно понятна. Когда модель должна классифицировать новый объект или спрогнозировать его значение, она обращается к k ближайшим примерам из обучающей выборки и принимает решение на основе их большинства или среднего значения.
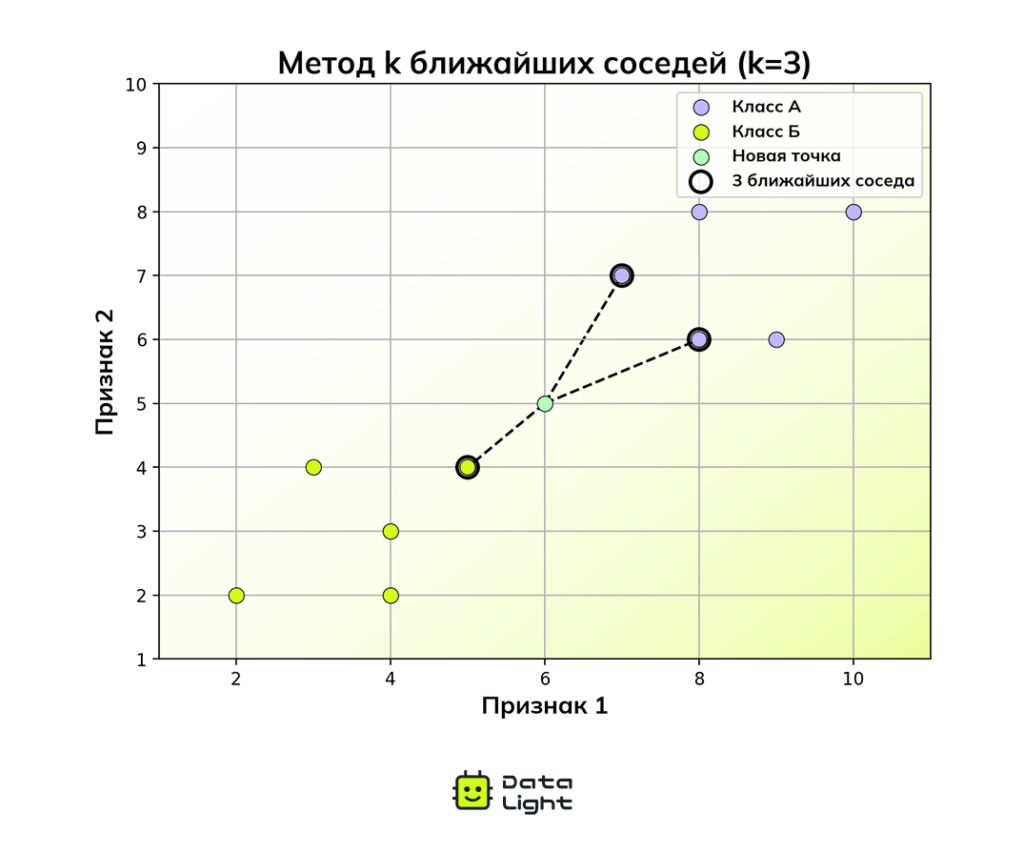
Представьте, что вы переехали в незнакомый город и хотите сходить поужинать. Вы спрашиваете совет у трех ближайших соседей: двое рекомендуют итальянскую кухню, один — бургерную. Скорее всего, вы выберете итальянский ресторан, так как его посоветовало большинство. Точно так же действует алгоритм k‑NN: если перед ним стоит задача классификации, он смотрит на k ближайших примеров и выбирает тот класс, который встречается чаще всего.
Главное преимущество метода k ближайших соседей — его наглядность и простота. Алгоритм легко реализовать, и он отлично подходит для небольших и средних наборов данных. Однако для больших датасетов его использование может быть ресурсоемким, так как для каждой новой точки алгоритм перебирает всю обучающую выборку, чтобы найти ближайших соседей.
Линейная регрессия
Линейная регрессия — еще один базовый алгоритм обучения с учителем, своего рода «Hello, World!». Его суть состоит в том, что модель пытается найти прямую (или гиперплоскость, если признаков много), максимально точно описывающую зависимость между входными признаками и целевой переменной.

Например, вы решили выяснить, как влияет количество часов, потраченных на учебу, на оценки за экзамен. Вы собираете данные, наносите их на график и проводите через них прямую линию. Эта линия отражает общую тенденцию: чем больше вы учитесь, тем выше оценки. Именно такую линию строит линейная регрессия.
Главное преимущество алгоритма — простота и интерпретируемость. Его легко реализовать, а полученные результаты просто объяснить. Однако такой подход эффективен лишь в тех случаях, когда зависимость между признаками и целевой переменной действительно близка к линейной.
Логистическая регрессия
Хотя в названии метода есть слово «регрессия», на самом деле это алгоритм классификации. Логистическая регрессия предсказывает вероятность того, что объект принадлежит определенному классу.
Как это работает? Алгоритм берет числовое значение, которое может варьироваться от −∞ до +∞, и с помощью логистической (сигмоидной) функции «сжимает» его до диапазона от 0 до 1. Полученное число интерпретируется как вероятность.
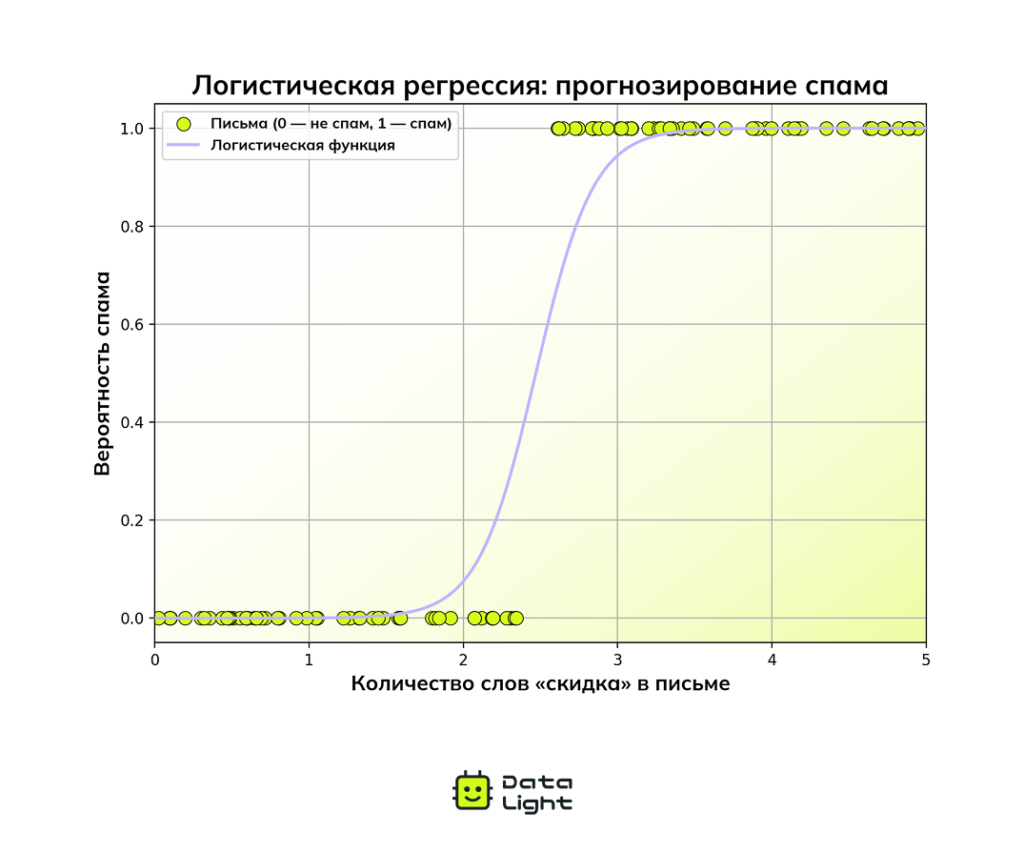
Этот график показывает, как растет вероятность, что письмо окажется спамом, если в нем часто встречается слово «скидка». Если эта вероятность превышает заданный порог, письмо классифицируется как спам.
Логистическая регрессия отличается простотой и удобной интерпретацией результатов. Именно поэтому ее часто используют в медицине для диагностики заболеваний и в банковском секторе для оценки кредитоспособности клиентов. Однако при слишком сложных нелинейных зависимостях она может уступать более гибким моделям.
Метод опорных векторов (SVM)
Метод опорных векторов (SVM) — это алгоритм, который находит оптимальную границу (гиперплоскость) для разделения данных на классы. Основная идея — провести эту границу так, чтобы расстояние между объектами разных классов было максимально большим.
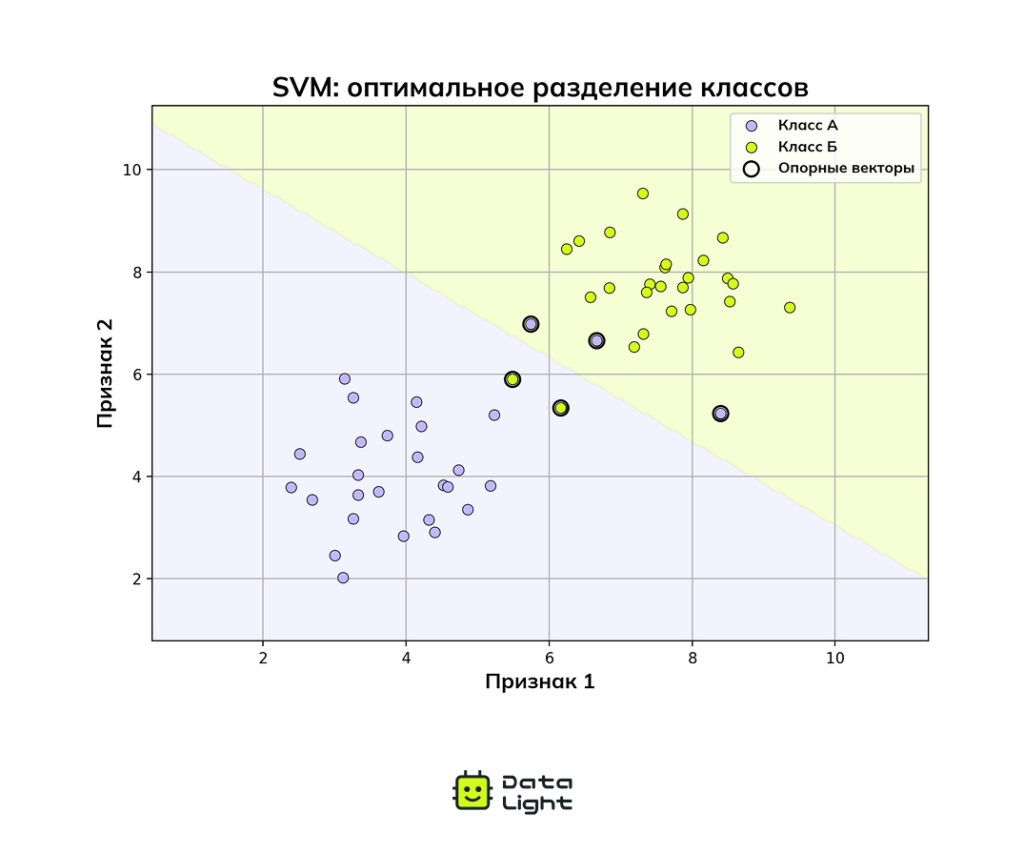
Представьте, что вы хотите разделить две компании друзей в парке, проведя между ними линию. Метод опорных векторов найдет такую линию, чтобы дистанция до ближайших представителей каждой из групп была наибольшей. В более сложных задачах с большим количеством признаков вместо линии используется гиперплоскость, а сами «друзья» становятся точками в многомерном пространстве.
Главный плюс SVM — умение работать с данными высокой размерности и способность улавливать сложные зависимости. За счет этого метод опорных векторов успешно применяется в распознавании изображений, текстов и биоинформатике.
Несмотря на относительную сложность интерпретации, SVM остается одним из самых мощных инструментов машинного обучения, который часто дает отличные результаты.
Дерево решений и случайный лес
Деревья решений — наглядный и понятный метод обучения с учителем, напоминающий привычные блок-схемы. Данные разделяются на ветви в зависимости от значений признаков, а в конечных узлах (листьях) оказывается итоговое решение или прогноз.
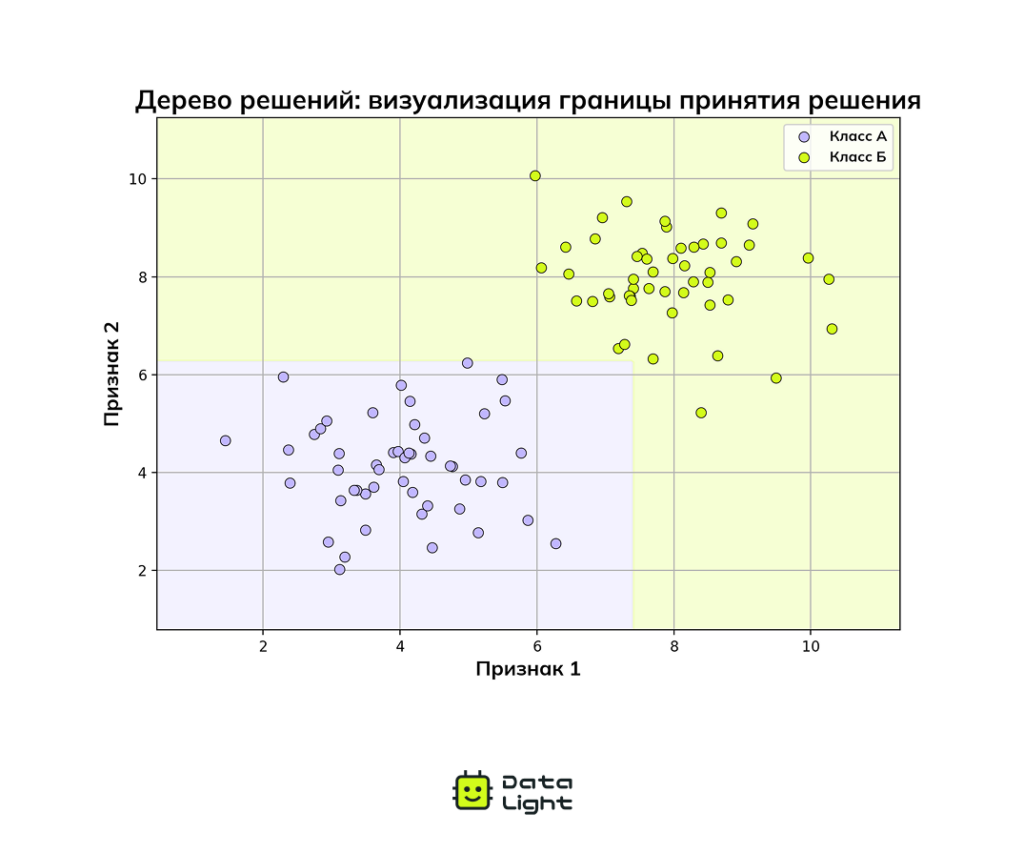
На изображении выше показан пример дерева, которое помогает решить, стоит ли идти на пикник. Сначала смотрим на температуру: если слишком холодно, пикник отменяется, а если тепло, проверяем, не идет ли дождь. Если идет дождь, лучше остаться дома, а если нет — можно отправляться на природу. Такой пошаговый подход разделяет все возможные погодные сценарии и дает конкретный ответ в каждом конечном узле.
Случайный лес (Random Forest) развивает идею деревьев решений. Вместо одного дерева он строит множество деревьев, каждое из которых обучается на случайно выбранной части данных и случайном наборе признаков. Затем их результаты усредняются, что повышает точность и устойчивость к ошибкам.
На практике случайный лес часто показывает высокую эффективность в самых разных задачах — от кредитного скоринга и медицинской диагностики до прогнозирования пользовательского поведения. Возможность работать с большим объемом данных и признаков сделала его одним из самых популярных алгоритмов машинного обучения.
Ансамблевые методы: бустинг и бэггинг
Ансамблевые методы объединяют несколько простых моделей, чтобы получить более точный и стабильный результат. Один из таких подходов — бэггинг (bagging), к которому относится случайный лес, с которым мы уже познакомились. В нем несколько моделей (например, деревьев решений) обучаются независимо друг от друга на разных подвыборках данных, а потом их ответы усредняются.
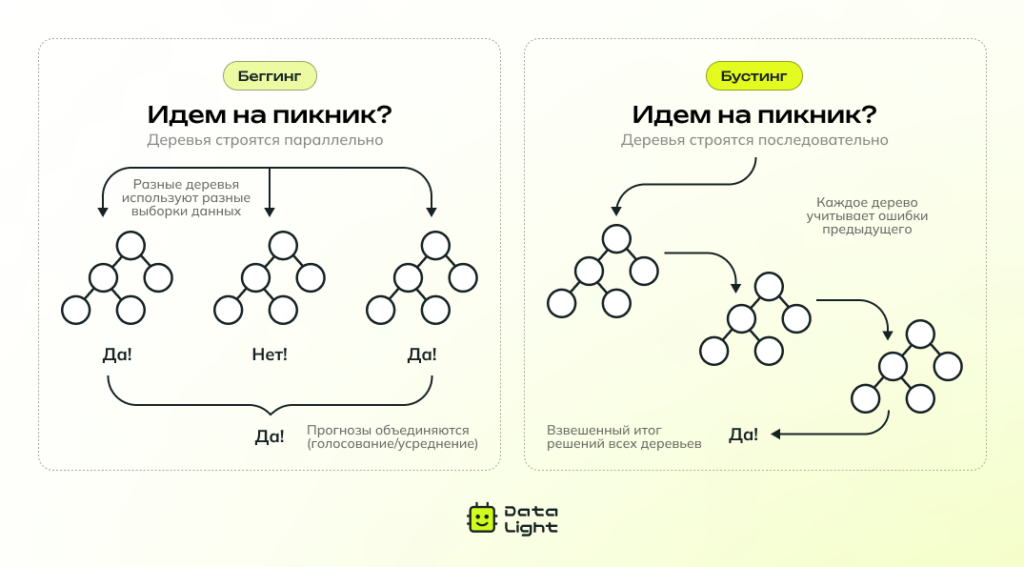
Другой популярный ансамблевый метод — бустинг (boosting), где модели обучаются последовательно: каждая новая пытается исправить ошибки предыдущей. Самые известные реализации бустинга — XGBoost, LightGBM и CatBoost.
Нейронные сети
Нейронные сети — это модели машинного обучения, вдохновленные устройством человеческого мозга. От простых многослойных персептронов (MLP) до глубоких нейросетей (Deep Neural Networks) — все они состоят из множества взаимосвязанных нейронов, объединенных в слои.
Каждый слой такой сети отвечает за распознавание все более сложных и абстрактных признаков. Например, в задаче распознавания лиц первый слой может выявлять простейшие элементы — линии и края, следующий — фрагменты лица (глаза, нос), а глубокие слои — уже целостные образы.
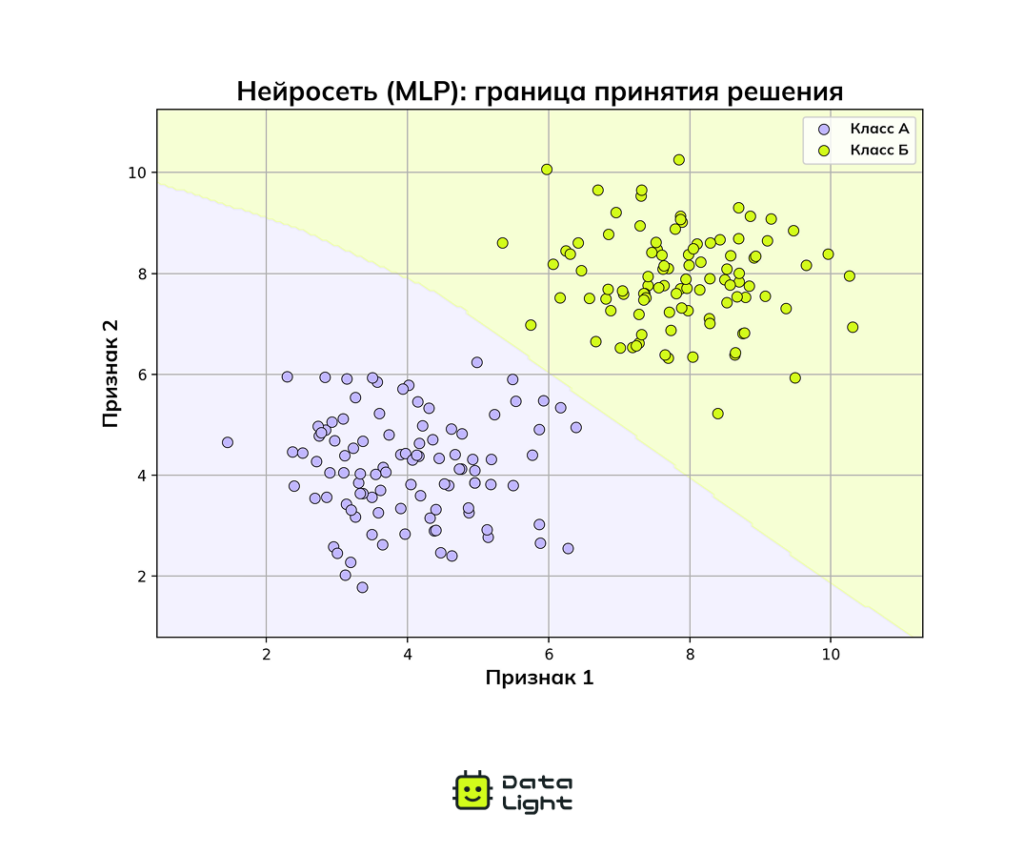
Благодаря способности находить сложные закономерности в больших массивах данных, нейросети совершили прорыв в компьютерном зрении, обработке языка и распознавании речи. Однако для их обучения нужны обширные наборы данных и мощные вычислительные ресурсы, что остается их главным ограничением.
Другие методы обучения
Хотя обучение с учителем — наиболее распространенный подход, существуют и другие методы, которые могут быть более подходящими, в зависимости от вашей задачи, целей и доступности данных.
Обучение без учителя (Unsupervised Learning)
При обучении без учителя данные не имеют «правильных ответов». Модель сама ищет в них закономерности и скрытые структуры. Представьте, что вам нужно разделить покупателей интернет-магазина на группы по покупательским привычкам, но вы не знаете, на какие именно. Здесь хорошо работают методы кластеризации (например, K‑means) и снижения размерности (например, PCA — метод главных компонент).
Обучение с частичным привлечением учителя (Semi-Supervised Learning)
Этот метод сочетает небольшое количество размеченных данных с большим объемом неразмеченных. Он особенно полезен, когда размечать данные дорого или сложно (например, в медицине). Модель с его помощью может осваивать общие закономерности за счет неразмеченной части, а точную настройку проходить на размеченных примерах.
Обучение с подкреплением (Reinforcement Learning)
Этот подход вдохновлен принципами вознаграждения в психологии. Модель («агент») учится взаимодействовать со средой, получая награды или наказания за свои действия. Задача агента — максимально увеличить итоговую награду. Пример — робот, ищущий выход из лабиринта, или компьютер, играющий в шахматы.
Самообучение (Self-Supervised Learning)
В этом подходе модель обучается, решая вспомогательные задачи (например, восстанавливая пропущенные слова в тексте). Именно так учатся популярные языковые модели вроде GPT: они находят тонкие закономерности в больших неразмеченных наборах данных.
Подводные камни
Даже самые продуманные модели иногда «спотыкаются». Рассмотрим частые проблемы, с которыми сталкиваются специалисты при разработке и внедрении моделей:
Переобучение (Overfitting)
Это ситуация, когда модель слишком буквально запоминает обучающие данные, вместо того, чтобы изучать обобщенные закономерности.
Например, модель по выявлению мошеннических транзакций может идеально распознавать известные схемы, но пропустит любые новые, ранее незнакомые.
Недообучение (Underfitting)
Это обратная ситуация — модель слишком простая и не способна уловить закономерности в данных. Например, использование линейной модели в задаче, где связь между признаками и целевой переменной явно нелинейная, приведет к низкой точности прогнозов как на обучающих, так и на тестовых данных.
Утечка данных (Data Leakage)
Возникает, если во время обучения случайно используется информация, которая на самом деле еще не могла быть известна. Это приводит к тому, что модель показывает завышенные результаты на этапе обучения, но плохо работает в реальной жизни.
Например, если в модель прогнозирования возврата кредита случайно включить признак, отражающий будущее поведение клиента (статус погашения кредита), то ее точность будет искусственно завышена.
Несоответствие между обучающими и реальными данными
Представьте, что вы разработали модель обнаружения мошенничества по данным за прошлый год. Со временем преступники меняют тактику, и старая модель уже не может эффективно распознавать новые схемы обмана. Чтобы избежать этого, необходимо регулярно обновлять данные, следить за качеством модели и периодически ее переобучать.
Решения:
- Регулярно проводите кросс-валидацию — она поможет вовремя выявить переобучение или недообучение.
- Создавайте надежные пайплайны обработки данных — это убережет от случайных утечек информации.
- Проверяйте качество модели в реальных условиях — чтобы вовремя обнаружить ухудшение и переобучить модель, когда это нужно.
Применение обучения с учителем в различных отраслях
Обычно примерами задач обучения с учителем называют фильтрацию спама или прогнозирование цен на акции. Однако в реальности эта технология широко применяется и в других, менее очевидных, но крайне интересных областях.

Сельское хозяйство
Модели машинного обучения прогнозируют урожай, используя спутниковые снимки, данные о погоде и составе почв.
Медицина
С помощью моделей обучения с учителем биологи и фармацевты ускоряют поиск новых лекарств, предсказывая взаимодействие молекулярных соединений, или анализируют геномные данные, выявляя маркеры заболеваний и факторы риска.
Производство
На заводах сенсоры круглосуточно собирают данные о работе оборудования. Алгоритмы обучения с учителем замечают сигналы, указывающие на возможную поломку, и помогают избежать дорогостоящих простоев.
Экология
Модели компьютерного зрения обучают распознавать виды животных по фотографиям с фотоловушек. Экологи получают возможность точнее отслеживать популяции и вовремя реагировать на угрозы.
Кроме того, машинное обучение помогает предсказывать изменение климата, экстремальные погодные явления и стихийные бедствия на основе исторических климатических данных.
Розничная торговля
Компании используют алгоритмы обучения с учителем, чтобы заранее предсказывать спрос на товары, оптимизировать запасы и формировать персонализированные рекомендации для покупателей.
Кибербезопасность
Системы машинного обучения анализируют большие объемы данных и учатся выявлять признаки необычной активности или мошеннических операций, помогая своевременно обнаруживать и предотвращать киберугрозы.
___________________________________________________________________
Эти примеры показывают, насколько разнообразными могут быть задачи обучения с учителем и какую огромную пользу они способны принести, если использовать качественные и специализированные данные.
Плюсы и минусы обучения с учителем
Как и любой метод, обучение с учителем имеет свои сильные и слабые стороны.
| Преимущества | Недостатки |
|---|---|
| Высокая точность. При наличии достаточного количества качественно размеченных данных модели обучения с учителем способны делать очень точные прогнозы. | Необходимость разметки. Создание качественного размеченного датасета — ресурсоемкая задача. Чтобы ее упростить, компании обращаются к услугам специализированных команд по сбору и разметке данных. |
| Интерпретируемость. Многие алгоритмы (например, линейная и логистическая регрессия, деревья решений) позволяют легко понять, почему модель сделала именно такой вывод. | Ограниченная адаптивность. При изменении внешних условий (так называемом «concept drift») модель может быстро устареть. Чтобы поддерживать высокое качество работы, необходимо постоянно отслеживать изменения и регулярно обновлять модель. |
| Универсальность. Почти любые типы данных (текст, изображения, таблицы) можно обрабатывать методами обучения с учителем. Широкий выбор алгоритмов дает возможность решать самые разные задачи. | Предвзятость. Модели могут перенимать и даже усиливать существующие в данных предубеждения. Например, если система оценки резюме обучалась на исторических данных, где чаще нанимали мужчин, она может отдавать предпочтение кандидатам с аналогичным профилем — даже если это не имеет отношения к их реальной квалификации. |
| Простота оценки качества. Так как правильные ответы уже известны, вы можете легко оценивать точность модели и оперативно улучшать ее. |
Устранение недостатков обучения с учителем требует не только технических знаний, но и внимания к этическим аспектам, глубокого понимания предметной области и постоянного мониторинга работы модели.
Ключевые выводы
Обучение с учителем — это надежный способ решать конкретные задачи на основе известных примеров. Его плюсы — предсказуемость, возможность контролировать весь процесс обучения и легко оценивать точность предсказаний.
Этот подход легко адаптируется под бизнес-цели, хорошо работает с разными типами данных и масштабируется по мере развития проекта. Главное условие успеха — качественная подготовка данных и регулярная проверка модели.