 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыВ мире машинного обучения тренировочные данные — это своего рода топливо, которое питает процесс обучения моделей. Но что именно они из себя представляют? Как и с помощью чего создаются?
В этой статье мы разберем ключевые аспекты подготовки тренировочных данных и их роль в создании эффективных моделей.

Что такое тренировочные данные?
Тренировочные данные — это набор примеров, который используется для того, чтобы научить модель машинного обучения решать конкретную задачу. Эти примеры включают входные данные, такие как изображения, тексты или аудиофайлы, и присвоенные им описания, то есть метки. Обучаясь на больших наборах данных, модели учатся находить закономерности между входными данными и метками, а затем применять свои знания на практике.
Например, если модель обучается распознавать объекты на уличных фотографиях, тренировочные данные могут состоять из изображений с метками «автомобиль», «пешеход», «светофор». Модель анализирует эти изображения, выделяет ключевые характеристики, такие как форма, цвет и положение объектов на изображении, и учится различать их. После завершения обучения модель будет способна определять объекты на новых фотографиях улиц, с которыми раньше не сталкивалась.

Как качество тренировочных данных влияет на обучение модели машинного обучения?
Качество тренировочных данных напрямую влияет на то, насколько успешно модель машинного обучения сможет предсказывать результаты на новых данных. Это можно сравнить с обучением студента: чем лучше подобран учебный материал, тем легче и точнее усваиваются знания. Аналогично, модель обучается лучше, если тренировочные данные качественные и разнообразные.
Если же тренировочные данные содержат ошибки, неполные сведения или плохо структурированы, модель может начать неправильно их интерпретировать. Примером может быть ситуация, когда в тренировочных данных, используемых для распознавания лиц, отсутствуют определенные этнические или возрастные группы. В этом случае модель может оказаться неспособной корректно распознавать лица представителей этих групп, что приведет к предвзятости и ошибкам в результатах ее работы.
Таким образом, качественные тренировочные данные — это фундамент для построения эффективной модели.
Как связаны тренировочные, валидационные и тестовые данные?
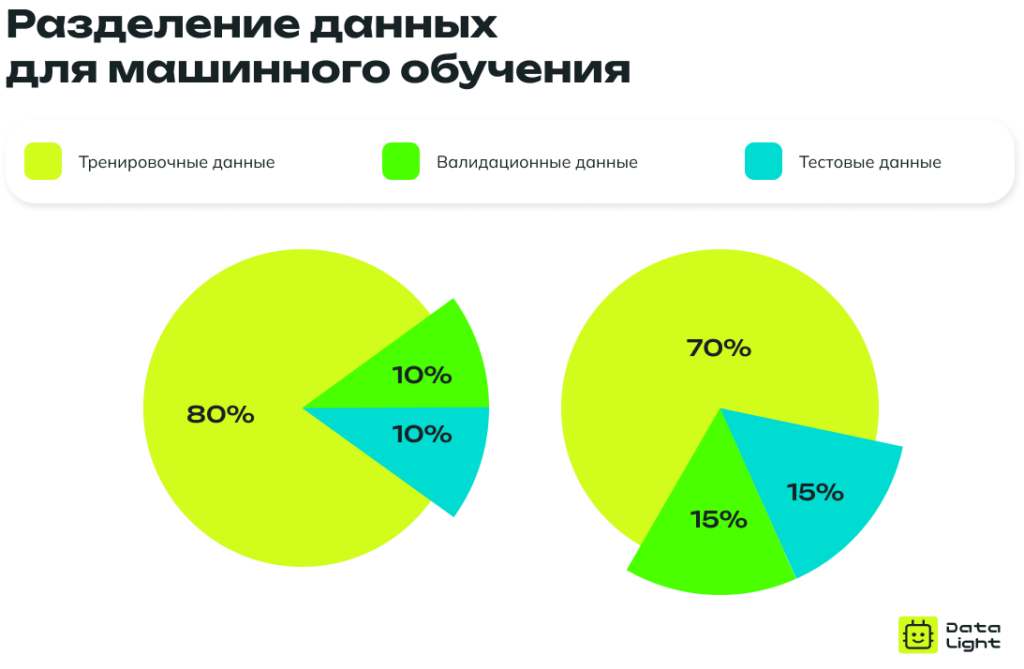
Однако для того чтобы построить модель машинного обучения, недостаточно использовать только тренировочные данные. В процессе разработки модели данные разделяются на три разных набора:
- Тренировочные данные — данные, которые используются для непосредственного обучения модели. Они предоставляют модели примеры, на которых она учится находить закономерности и делать собственные прогнозы.
- Валидационные данные используются на промежуточных этапах обучения для настройки параметров модели и оценки того, как хорошо модель обучается, не «запоминая» тренировочные данные слишком точно. Это помогает избежать проблемы переобучения (overfitting), когда модель становится слишком зависимой от конкретных тренировочных примеров и плохо справляется с новыми данными.
- Тестовые данные — набор данных, который используется в самом конце, после завершения обучения, для окончательной проверки производительности модели. Он нужен для того, чтобы объективно оценить, насколько хорошо модель справляется с новыми задачами.
Все типы тренировочных данных
Типы тренировочных данных можно классифицировать по нескольким критериям:
Структурированные и неструктурированные данные
| Тип данных | Описание |
|---|---|
| Структурированные данные | Имеют четко организованную структуру (таблицы, базы данных). |
| Полуструктурированные данные | Содержат некоторые элементы структуры, но в целом имеют менее строгую организацию по сравнению со структурированными данными (XML, JSON). |
| Неструктурированные данные | Не имеют четкой структуры и требуют предварительной обработки перед использованием (изображения, текст, аудио- и видеозаписи). |
Реальные и синтетические данные
| Тип данных | Описание |
|---|---|
| Реальные данные (Real Data) | Представляют собой естественные примеры, полученные из реального мира. |
| Синтетические данные (Synthetic Data) | Создаются при помощи алгоритмов или моделей для имитации реальных данных. Используются, когда реальные данные трудно получить или их недостаточно. |
Размеченные и неразмеченные данные
| Тип данных | Описание |
|---|---|
| Размеченные данные (Labeled Data) | Содержат примеры с известными метками. Используются в задачах обучения с учителем. |
| Неразмеченные данные (Unlabeled Data) | Не имеют заранее подготовленных меток. Используются в задачах обучения без учителя. |
Этапы подготовки тренировочных данных
Подготовка тренировочных данных — это многогранный процесс, включающий в себя несколько ключевых этапов, каждый из которых играет важную роль в будущем успехе модели.
Этап 1: Сбор данных
Сбор данных — это основа, с которой начинается подготовка данных для любого проекта. На этом этапе важно собрать разнообразные и репрезентативные данные, чтобы модель могла обучаться на разных примерах и справляться с широким спектром задач.
Источники данных
Для успешного сбора данных можно использовать несколько источников:
Внешние данные
Внешние данные включают информацию, которая доступна из открытых, публичных источников. Это могут быть данные, опубликованные правительственными учреждениями, исследовательскими организациями, аналитическими центрами, а также данные из публичных баз, социальных сетей и других ресурсов.
Пример: для задач, связанных с обработкой естественного языка (NLP), источниками данных могут стать новостные веб-сайты и онлайн-форумы.
Внутренние данные
Внутренние данные — это те данные, которые компания самостоятельно собирает в ходе своей деятельности. Зачастую они являются максимально релевантными для конкретных и узконаправленных задач бизнеса.
Пример: платформа онлайн-торговли может использовать данные об истории покупок для анализа предпочтений своих клиентов и создания рекомендательных систем.
Услуги по сбору и продаже данных
Иногда для успешной разработки модели требуются более специализированные наборы данных, чем те, которые можно найти в открытом доступе или собрать самостоятельно. В таких случаях можно обратиться к сторонним организациям, которые предоставляют услуги по сбору и продаже данных.
Пример: брокеры данных предоставляют финансовые данные, которые можно использовать для построения моделей прогнозирования кредитных рисков.
Краудсорсинговые платформы
Еще один эффективный механизм сбора данных — краудсорсинговые платформы. Они позволяют создавать разнообразные датасеты, привлекая к участию большое число людей.
Пример: краудсорсинг может быть использован для сбора голосовых записей при создании систем речевой биометрии.
Этап 2: Предварительная обработка данных
После того как данные собраны, следующим этапом является их предварительная обработка. Зачем это нужно? Дело в том, что реальные данные часто содержат ошибки и неточности, которые могут повлиять на обучение модели. Чтобы получить качественные результаты, необходимо минимизировать их наличие. Предварительная обработка включает в себя несколько подэтапов:
- Очистка данных
Очистка данных — это процесс выявления и исправления некорректной, неполной или дублированной информации в наборе данных. В свою очередь она может включать в себя один или несколько дополнительных шагов:
- Обнаружение выбросов (Outlier Detection). Выбросы — это значения, которые резко отличаются от остальных данных и мешают модели выявлять закономерности. Например, если в данных о покупках имеются несколько очень крупных транзакций, это может повлиять на обучение модели и исказить ее работу. Чтобы избежать этого, следует либо удалить выбросы, либо скорректировать их влияние.
- Нормализация и масштабирование (Normalization and Scaling). Эти методы направлены на устранение искажений, связанных с различиями в масштабах признаков. Например, если в одном наборе данных значения варьируются от 1 до 1000, а в другом — от 0.01 до 1, это может привести к тому, что алгоритмы будут неправильно оценивать значимость этих признаков. Нормализация приводит значения признаков к диапазону от 0 до 1, что помогает избежать доминирования признаков с большими значениями. А масштабирование (стандартизация) преобразует данные так, чтобы они имели нулевое среднее и единичное стандартное отклонение
- Обработка пропущенных данных (Handling Missing Data). Пропущенные данные возникают по разным причинам, но они также влияют на эффективность работы модели. Существует несколько подходов к их обработке: удаление записей, замена пропусков средними, медианными или модальными значениями, а также использование более сложных методов, таких как интерполяция или модели предсказания.
2. Снижение размерности данных (Data Reduction):
Снижение размерности помогает работать с большими наборами данных, уменьшая их сложность без значительной потери полезной информации. Для этой задачи часто применяются такие методы как отбор признаков и анализ главных компонент (PCA).
3. Конструирование признаков (Feature Engineering):
Конструирование признаков подразумевает создание новых признаков или преобразование существующих для повышения производительности модели. Например, в данных о транзакциях клиентов временные метки могут быть преобразованы в полезные признаки, такие как «время суток» или «день недели», позволяющие лучше понять поведение покупателей.
Этап 3: Разметка данных
Следующим этапом подготовки данных является их разметка. На этом этапе к исходным данным, будь то изображения, тексты, видео или аудио, добавляются метки, которые помогают моделям машинного обучения лучше интерпретировать информацию.

Разметку данных можно осуществлять различными способами:
Ручная разметка
Этот метод подразумевает, что специалисты вручную добавляют метки к каждому элементу в наборе данных. Ручная разметка обеспечивает высокую точность аннотаций, однако требует значительных временных ресурсов.
Автоматическая разметка
Для ускорения процесса разметки часто используют алгоритмы, которые автоматически присваивают метки данным. Это экономит время, но качество такой разметки может быть значительно ниже.
Полуавтоматическая разметка
Полуавтоматическая разметка сочетает в себе оба подхода: алгоритмы выполняют первоначальную разметку, а специалисты затем проверяют и корректируют ее, что позволяет находить баланс между скоростью и точностью.
Каждое из этих решений имеет свои преимущества и недостатки, поэтому при выборе метода разметки важно учитывать цели, задачи и доступные ресурсы проекта.
Этап 4: Контроль качества
После завершения всех предыдущих этапов важно провести проверку подготовленных данных, так как любые пропущенные ошибки могут негативно сказаться на работе модели.
- Проверка случайных выборок. Часто используется метод случайной выборки: специалисты выбирают несколько примеров из набора данных и проверяют их вручную на соответствие правильной разметке.
- Автоматическое тестирование. Для больших объемов данных применяются автоматизированные скрипты, которые анализируют набор данных на наличие ошибок или аномалий. Например, алгоритмы могут проверять, соответствуют ли все данные нужному формату, есть ли дублирование меток или пробелы в аннотациях.
Возможные проблемы при подготовке тренировочных данных и их решения
При подготовке данных для машинного обучения часто возникают различные проблемы, которые могут существенно повлиять на качество моделей. Рассмотрим наиболее распространенные из них и возможные пути решения.
Проблема 1: Дисбаланс классов
Дисбаланс классов возникает, когда один или несколько классов в наборе данных значительно преобладают над другими. Это приводит к тому, что модель обучается лучше распознавать преобладающие классы, игнорируя редкие.
Решение: балансировка классов
Для решения проблемы дисбаланса классов можно использовать несколько подходов. Один из них — oversampling, когда количество примеров редких классов увеличивается за счет дублирования существующих данных. Другой вариант — undersampling, при котором сокращается количество примеров доминирующих классов для выравнивания соотношения. Также можно применять метод взвешенных потерь, задавая более высокий вес редким классам, что позволяет компенсировать их недостаток и улучшить качество обучения модели.
Проблема 2: Недостаток данных
Недостаток данных возникает, когда объем доступного набора данных слишком мал для успешного обучения модели. Это ограничивает ее способность обобщать полученные знания, что приводит к снижению точности при обработке новых примеров.
Решение: увеличение объема данных
Для увеличения объема данных можно использовать несколько подходов. Один из них — аугментация данных. Это метод искусственного увеличения объема данных за счет модификации существующих примеров, например, когда изображение изменяется с помощью вращения, изменения яркости или масштабирования. Другой способ — создание синтетических данных с помощью генеративных моделей. Также можно объединять данные из разных источников, расширяя обучающую выборку за счет комбинирования небольших наборов данных.

Ключевые выводы
Тренировочные данные являются основополагающим элементом в процессе обучения моделей машинного обучения. Они представляют собой набор примеров, которые используются для обучения модели решать конкретные задачи. Эти примеры могут включать различные виды информации, такие как изображения, тексты и аудиофайлы, а также соответствующие метки, которые помогают модели распознавать и классифицировать входные данные. Обучаясь на больших объемах данных, модели выявляют закономерности и связи между входными данными и метками, что позволяет им применять эти знания на практике.
Качество тренировочных данных критически важно, так как ошибки или недостатки в них могут привести к снижению точности модели и искажению результатов. Например, если данные недостаточно разнообразны или содержат предвзятости, модель может не справляться с задачами, выходящими за рамки тех примеров, на которых она обучалась. Поэтому тщательная подготовка данных, включающая сбор, разметку и проверку на наличие ошибок, является неотъемлемой частью успешного обучения.
Кроме того, важно учитывать, что тренировочные данные должны отражать реальную среду, в которой модель будет использоваться. Это означает, что необходимо стремиться к созданию репрезентативного набора данных, который охватывает все возможные сценарии. В конечном итоге, хорошо подготовленные тренировочные данные обеспечивают не только высокую точность модели, но и ее устойчивость к изменяющимся условиям, что делает ее практическое применение более эффективным.