 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыДатасет — это совокупность данных, собранных, организованных и подготовленных для решения конкретных задач. В машинном обучении данные являются основным ресурсом для обучения моделей, проверки их работы и оценки точности. Принцип работы датасетов в ML можно описать следующим образом:
- Датасет обеспечивает модель информацией для поиска закономерностей.
- Найденные закономерности используются для предсказания или решения задач на новых данных.
Пример: чтобы создать модель, которая распознает породы собак на изображениях, необходим датасет с большим количеством фотографий собак, где каждой фотографии соответствует метка породы. В процессе обучения модель изучает изображения и их метки, выделяя характерные черты для каждой породы (например, форма ушей, структура шерсти). После завершения обучения модель использует выученные закономерности, чтобы классифицировать новые изображения.

Компоненты датасета
Датасет состоит из нескольких ключевых элементов, которые зависят от его назначения и формата.
- Примеры (samples)
Примеры — это отдельные единицы данных в наборе. Например, в датасете для классификации изображений каждый пример — это индивидуальное изображение.
- Признаки (features)
Признаки представляют собой свойства или атрибуты данных, которые используются для анализа и обучения модели. Например, в задаче прогнозирования стоимости дома признаки могут включать площадь, количество комнат, год постройки или его расположение.
В этом примере столбцы license_plate.rows_count, license_plate.number — признаки для датасета с номерами машин:
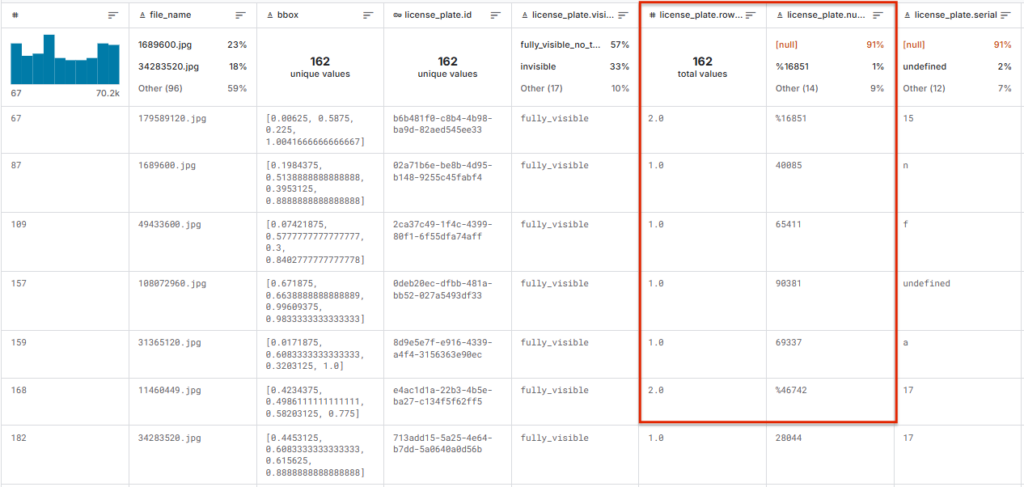
- Метки (labels)
Метки — это данные, связанные с примерами, которые указывают их категорию или целевое значение. В задачах с учителем (supervised learning) метки представляют классы (например, «кошка» или «собака») или числовые значения (например, цена дома). В задачах без учителя (unsupervised learning) метки обычно отсутствуют, а модель анализирует данные для поиска скрытых структур.
Вот как могут выглядеть изображения и метки в датасете с автомобильными номерами:

- Метаданные
Метаданные включают дополнительную информацию о данных, например, источник, дату создания, условия сбора или методы предварительной обработки. Они не используются напрямую для обучения модели, но важны для управления, анализа и документирования датасета. Метаданные могут также включать сведения о лицензировании и форматах данных.
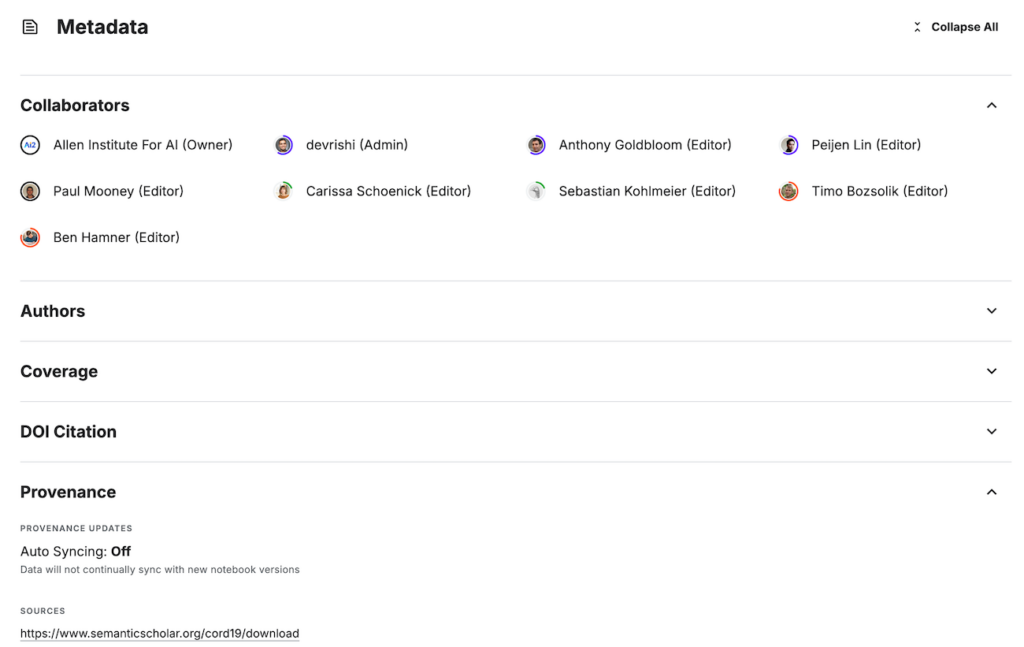
Применение в машинном обучении
Датасеты являются основой для построения и оценки моделей машинного обучения. Они необходимы на всех этапах работы с моделью — от обучения до проверки ее производительности.
1. Обучение модели (Training)
На этапе обучения модель анализирует данные, чтобы выявить закономерности и установить зависимости между признаками и метками. Основная цель этого этапа — обучить модель распознавать шаблоны в данных.
2. Валидация модели (Validation)
Валидационный набор используется для настройки гиперпараметров модели и проверки ее производительности.
3. Тестирование модели (Testing)
Тестовый набор используется для окончательной оценки модели и определения ее способности обобщать знания на новых данных после обучения и валидации.
Основные форматы датасетов
Датасеты для машинного обучения могут храниться в различных форматах, в зависимости от типа данных, объема, сложности и специфики их использования. Формат хранения определяет структуру организации данных и способы их обработки.
Грамотный выбор формата может существенно упростить работу с датасетом, ускорить его обработку и минимизировать ошибки при загрузке в модель.
| Формат | Описание | Пример использования |
|---|---|---|
| CSV | Текстовый формат, в котором данные представлены в виде строк, разделенных запятыми или другими разделителями (например, точкой с запятой). Широко используется из-за простоты и универсальности. | Анализ медицинских данных, предсказание цен на недвижимость, построение моделей для ритейл-прогнозов. |
| JSON | Формат с древовидной структурой, представляющий данные в виде пар “ключ-значение”. Позволяет работать с вложенными данными. | Работа с геоданными для построения карт, анализ отзывов пользователей, разработка NLP-моделей и чат-ботов. |
| Parquet | Колонко-ориентированный двоичный формат, созданный для эффективного хранения больших объемов данных.. | Анализ транзакционных данных в финансовых системах, обработка больших массивов для предсказания трендов. |
| HDF5 | Иерархический двоичный формат, позволяющий хранить массивы, метаданные и сложные структуры данных. Широко используется для научных исследований и обработки многомерных данных. | Анализ изображений, обработка 3D-сканов в компьютерном зрении, работа с медицинскими данными. |
| XML | Формат с четкой структурой данных, использующий теги для организации информации. | Анализ тональности текстов, NLP, работа с метаданными в различных областях (например, данные IoT). |
| COCO | Специализированный формат для хранения аннотированных данных, часто используемый в задачах компьютерного зрения. Поддерживает различные виды аннотаций. | Обучение моделей для детекции объектов, сегментации и анализа позы человека в компьютерном зрении. |
| YOLO | Формат хранения аннотированных данных для задач детекции объектов. | Обнаружение объектов в реальном времени для систем автономного вождения, отслеживание движущихся объектов на видео. |
Как создаются датасеты?
Создание датасета — это многоэтапный процесс, требующий тщательной проработки. Его цель — собрать данные, которые будут релевантны задачам машинного обучения, репрезентативны для реальных ситуаций и достаточно разнообразны для успешного обучения модели. Рассмотрим основные этапы создания датасета.
Этапы создания датасета
- Определение цели и задачи
Первый шаг в создании датасета — это четкое определение его назначения. Для каких задач он нужен? Например, будет ли модель классифицировать изображения, анализировать текст или распознавать объекты? Ответы на эти вопросы определяют требования к типу данных, их объему, формату и способам аннотации.
- Сбор данных
На этом этапе собирается исходный материал. Данные могут быть собраны из различных источников, в зависимости от задач проекта:
- Открытые данные: берутся из публичных баз или репозиториев.
- Собственные данные: собираются с помощью датчиков, камер, опросов.
- Веб-скрейпинг: данные извлекаются с веб-сайтов с использованием инструментов, таких как Beautiful Soup или Scrapy.
- Синтетические данные: создаются искусственно с помощью симуляций, генеративных моделей или алгоритмов. Это особенно полезно в задачах, где сбор реальных данных затруднен.
- Очистка данных
Собранные данные часто содержат ошибки, шум или пропущенные значения. Очистка данных включает:
- Удаление дубликатов.
- Заполнение или удаление пропущенных значений.
- Обнаружение и исправление аномалий.
- Приведение данных к единому формату.
- Аннотация данных
Для задач с учителем (supervised learning) данные должны быть размечены. Разметка связывает примеры с метками, которые определяют их категории или свойства. Процесс разметки может выполняться вручную, с помощью автоматизированных инструментов или при помощи комбинации этих методов.
- Разделение
После сбора и аннотации датасет делится на три части:
- Тренировочная выборка (Training Set): 70–80% данных, которые используются для обучения модели.
- Валидационная выборка (Validation Set): 10–15% данных, применяемых для настройки гиперпараметров и оценки производительности на этапе обучения.
- Тестовая выборка (Test Set): 10–15% данных, которые используются для итоговой проверки качества модели.
- Проверка качества
На этом этапе проводится контроль качества данных, например, этот процесс может включать оценку точности аннотаций и анализ сбалансированности классов.
- Сохранение
Датасет сохраняется в подходящем формате (например, CSV, JSON) и интегрируется в систему управления версиями данных (DVC, MLflow) для удобного использования и отслеживания изменений.
Где искать готовые датасеты?
Создание собственного датасета может быть затратным и трудоемким процессом. Чтобы сэкономить время и усилия, разработчики часто обращаются к платформам, где размещены разнообразные наборы данных. Эти платформы предоставляют доступ к готовым решениям для задач машинного обучения, от обработки текста до компьютерного зрения.
Kaggle — популярная платформа, предоставляющая широкий выбор датасетов для различных задач. Здесь можно найти данные для классификации, регрессии, компьютерного зрения, обработки естественного языка и других направлений.
UCI Machine Learning Repository
UCI — один из старейших репозиториев, в котором содержатся как классические, так и экспериментальные наборы данных. Репозиторий удобен для поиска структурированных данных, которые можно использовать в задачах классификации, кластеризации и регрессии.
Интересный факт: одним из самых популярных датасетов в машинном обучении является датасет Iris, представленный в 1936 году. Он содержит 150 образцов ирисов трех видов и используется для тестирования алгоритмов классификации и анализа данных по сей день.
Google Dataset Search — инструмент, который позволяет искать датасеты по множеству тем: от здравоохранения до финансов. Это универсальная платформа для поиска как открытых, так и коммерческих данных. Подходит для исследователей и разработчиков, которые работают в различных доменах.
OpenML предоставляет не только доступ к множеству наборов данных, но и инструменты для анализа и совместного использования результатов. Платформа активно используется для задач автоматизированного машинного обучения (AutoML).
Платформа от Microsoft, которая предлагает открытые данные для задач анализа временных рядов, геопространственных вычислений и других направлений. Особенность — интеграция с сервисами Azure, что упрощает обработку больших данных.
Zenodo — научный репозиторий, предоставляющий доступ к датасетам, опубликованным исследователями. Отличается строгими стандартами лицензирования и качества, что делает его полезным для академических проектов.
Примеры открытых датасетов
Компьютерное зрение (Computer Vision)
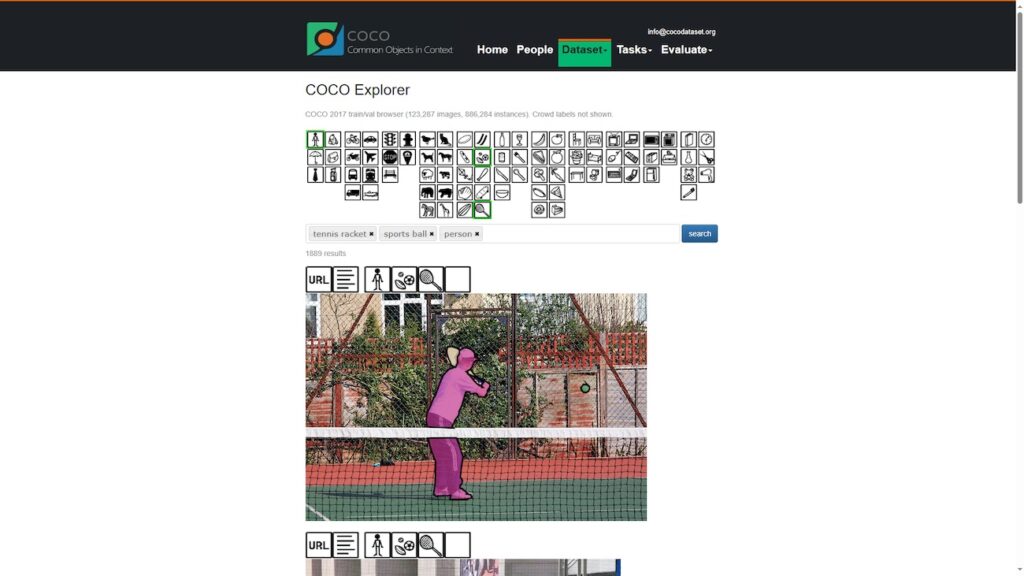
COCO (Common Objects in Context)
Один из самых популярных датасетов для задач детекции и сегментации объектов. Включает множество изображений с аннотациями для десятков классов объектов.
Огромный датасет изображений для задач классификации. Содержит более 14 млн. аннотированных изображений, разделенных на 21 тыс. категорий.
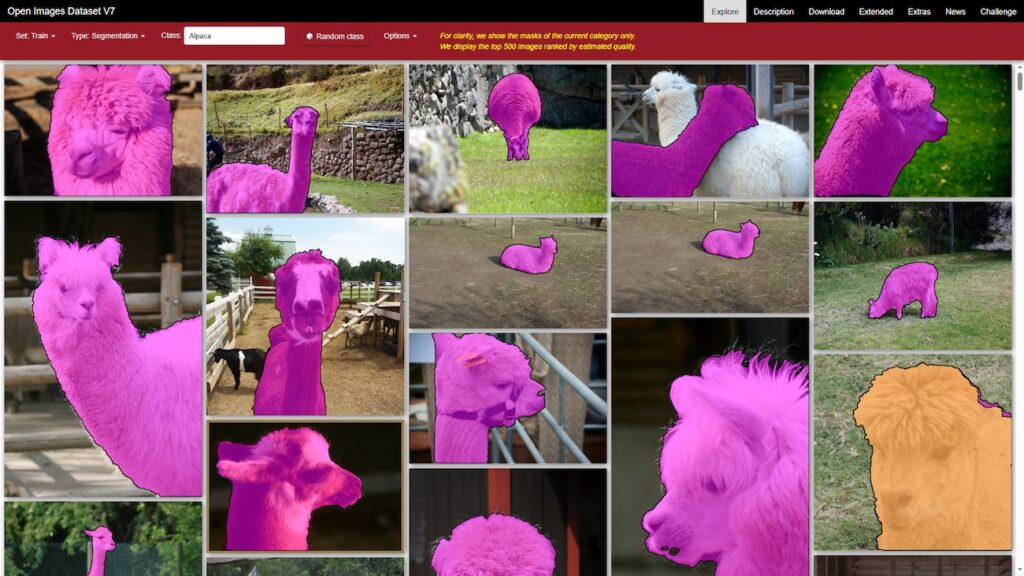
Набор изображений с аннотациями для более чем 600 категорий объектов.
Включает более 15 000 изображений, размеченных для 67 классов объектов, которые могут встречаться в закрытых помещениях, таких как столовые, кухни, библиотеки, спальни и другие. Используется для задач классификации изображений, а также для разработки моделей, которые могут распознавать объекты и сцены в различных интерьерах.
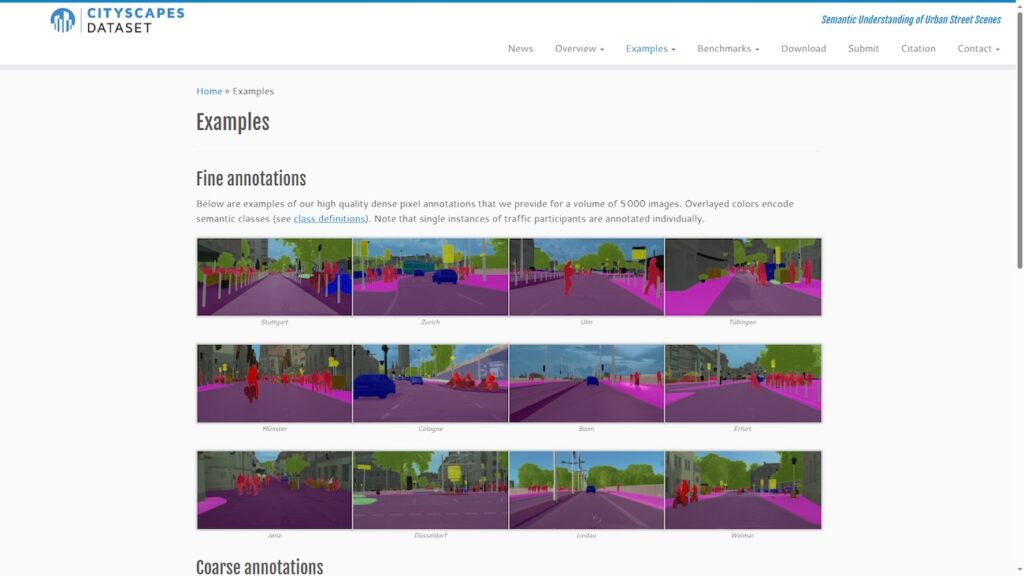
Датасет, предназначенный для научных и исследовательских исследований в области компьютерного зрения, в частности для сегментации и детекции объектов. Включает в себя высококачественные изображения, снятые в городах, с подробными аннотациями для более чем 30 классов объектов, таких как дороги, здания, автомобили, пешеходы и другие.
Обработка естественного языка (NLP) и распознавание речи
SQuAD (Stanford Question Answering Dataset)
Один из самых популярных наборов данных для систем вопросов-ответов (question answering, QA), который используется для разработки систем, способных находить ответы на вопросы в текстах.
Данный датасет содержит более 50 000 отзывов о фильмах с метками (положительные или отрицательные) и используется в задачах анализа тональности и обработки естественного языка.
Открытый датасет, содержащий текстовые данные из книг, опубликованных на платформе Wikibooks. Включает разнообразные жанры и темы, что делает его идеальным для задач обработки естественного языка.
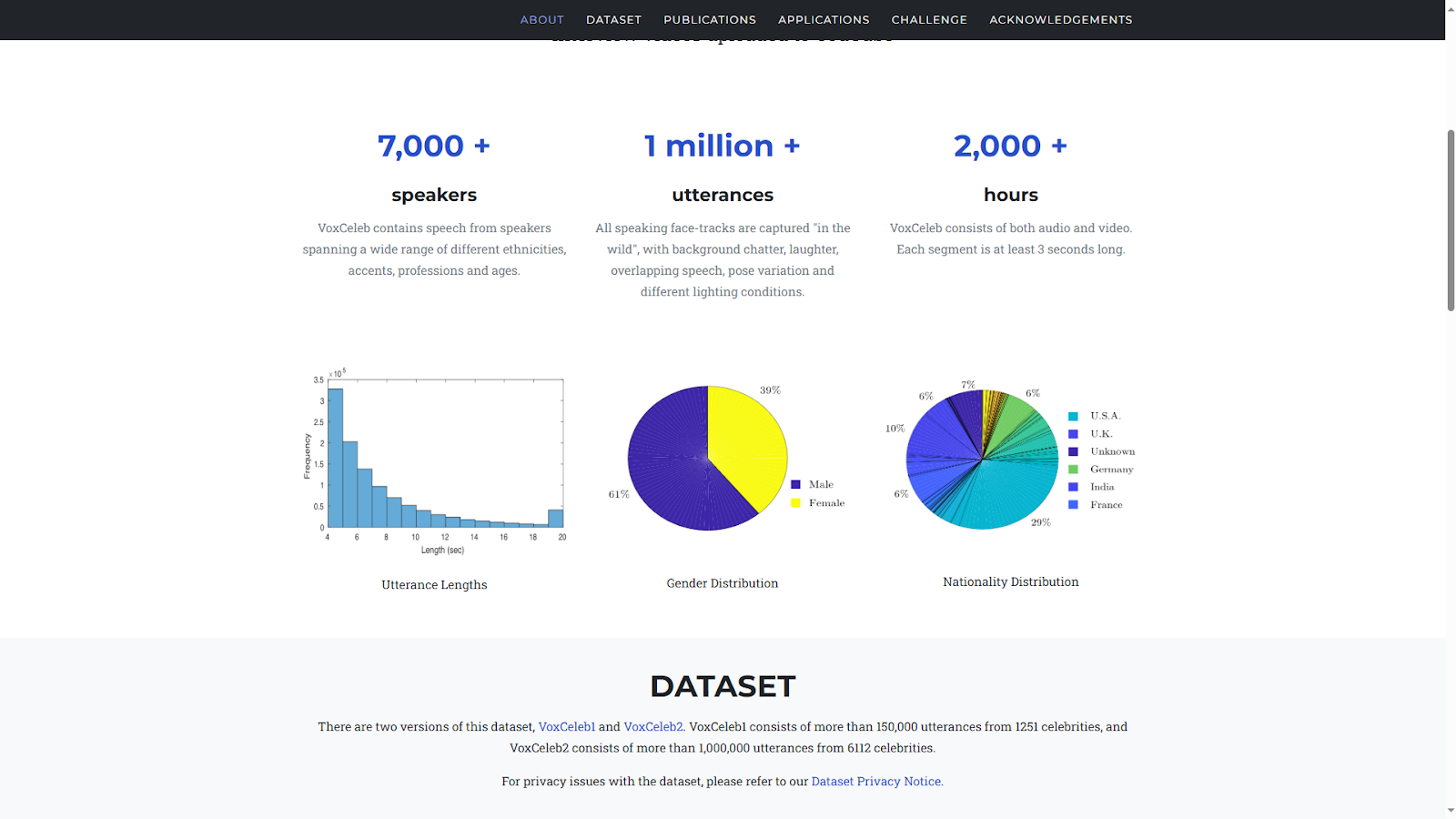
Набор данных для задач глубокого обучения, таких как распознавание и верификация голосов, обработка естественного языка и генерация речи. Включает более 2000 часов записей с участием знаменитостей и публичных личностей, собранных из интервью и видео на YouTube.
Free Spoken Digit Dataset (FSDD)
Содержит аудиозаписи произнесенных цифр в различных условиях. Предназначен для обучения моделей, которые могут распознавать и классифицировать аудиосигналы.
На что обратить внимание при выборе набора данных?
Выбор подходящего датасета для машинного обучения — ключевой этап, который определяет успех проекта. Некорректный или некачественный набор данных может привести к снижению точности модели и ошибкам. Ниже перечислены основные аспекты, которые необходимо учитывать.
Соответствие цели задачи
Каждая задача машинного обучения требует уникального типа данных. Важно определить, какие данные нужны: изображения, текст, аудио, видео или таблицы. Например для анализа тональности текста нужен набор данных с отзывами, помеченными как «положительные» или «отрицательные».
Размер датасета
Объем данных играет ключевую роль. Небольшие датасеты могут привести к недостаточному обучению модели, а слишком большие — потребовать значительных вычислительных ресурсов.
Рекомендации:
- Для простых задач (например, линейной регрессии) достаточно небольшого датасета.
- Для глубокого обучения требуются большие наборы данных.
1. Качество данных
Качество данных напрямую влияет на производительность модели.
На что обратить внимание:
- Наличие шумов: неправильные метки, поврежденные изображения, неоднозначные данные.
- Пропуски данных: пустые значения могут потребовать дополнительной обработки.
- Однородность: данные должны быть согласованы по формату.
2. Репрезентативность
Данные должны отражать все ключевые аспекты реального мира, чтобы модель могла успешно обобщать и применять свои знания. Репрезентативность означает, что данные включают все возможные сценарии использования модели.
Проверьте:
- Покрывает ли датасет возможные сценарии использования?
- Есть ли в данных редкие примеры?
Пример: если вы обучаете модель распознавать лица людей, то в датасете должны быть представлены люди разных возрастных групп и этнических принадлежностей.
3. Баланс классов
В задачах классификации важно обеспечить равномерное распределение данных между классами. Дисбаланс может привести к тому, что модель будет выбирать в качестве предсказаний доминирующий класс.
Решение:
- Проанализируйте распределение данных по классам.
- Убедитесь, что есть достаточное количество примеров для каждого класса
- Используйте методы увеличения данных (data augmentation) или весовые коэффициенты в процессе обучения.
4. Лицензия и доступность
Перед использованием датасета важно убедиться, что вы имеете право использовать данные из выбранного набора. Многие открытые датасеты имеют ограничения по использованию, особенно в коммерческих целях.
Обратите внимание:
- Проверьте лицензию датасета.
- Убедитесь, что вы можете использовать данные в вашем проекте.
5. Формат данных
Данные должны быть представлены в формате, который совместим с вашей рабочей средой и инструментами.
Например:
- Табличные данные (CSV) для численного анализа.
- Полуструктурированные данные (JSON, XML) для обработки текста.
- Аннотированные файлы (например, COCO JSON) для компьютерного зрения.
6. Актуальность данных
В некоторых задачах, таких как прогнозирование или обработка временных рядов, важно, чтобы данные соответствовали текущим реалиям.
Проверьте:
- Насколько актуальна информация в датасете?
- Есть ли в датасете устаревшая информация, которая может повлиять на точность модели?
Ключевые выводы
Датасеты — это структурированные наборы данных, которые служат основой для обучения, тестирования и оценки моделей машинного обучения. Они содержат информацию, необходимую для анализа и построения алгоритмов, и играют ключевую роль в развитии искусственного интеллекта.
Качество и структура датасетов определяют эффективность моделей машинного обучения. Репрезентативные и хорошо подготовленные данные позволяют алгоритмам с большой точностью выявлять закономерности, обобщать знания и делать прогнозы. Однако ошибки, пропуски или дисбаланс классов в данных могут негативно сказаться на результатах, снизить точность модели и вызвать искажения.
Поэтому подготовка датасетов или выбор готового решения требует внимательной оценки качества данных и их соответствия поставленной задаче. Использование подходящего датасета является важным условием для успешной работы модели и достижения точных, надежных результатов.