 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыДля того чтобы алгоритмы искусственного интеллекта могли обучаться и работать эффективно, им нужны данные — качественные и разнообразные. Процесс сбора таких данных не всегда бывает простым. Он включает в себя не только поиск и сбор информации, но и решение целого ряда дополнительных организационных задач.
В этой статье мы рассмотрим основные особенности и методы сбора данных для машинного обучения, а также трудности и вопросы, с которыми сталкиваются специалисты в этой области.

С чего начинается сбор данных?
Сбор данных — ключевой этап в любом проекте по машинному обучению. От того, насколько продумано вы подойдете к нему, зависит точность и надежность итоговой модели. Поэтому перед тем как приступить к сбору, важно ясно понять, какую задачу будет решать модель и какие данные ей действительно нужны. Это позволит избежать бессистемного накопления ненужной информации и сосредоточиться на других аспектах работы.
На этом предварительном этапе важно:
- Сформулировать задачу будущей модели. Решите, что будет делать ваш алгоритм, например, распознавать объекты на изображениях, выявлять мошеннические транзакции или анализировать тональность текстовых отзывов.
- Определить требования к данным. Когда задача сформулирована, необходимо понять, какие типы данных нужны для ее решения. Также важно определить, сколько данных требуется и какие признаки будут значимыми для обучения модели.
- Выбрать метод сбора данных. Если подходящие данные уже есть (внутри компании или в открытых источниках) — это упрощает задачу сбора нужных данных. Если нет, предстоит организовать самостоятельный сбор, оценив доступные ресурсы (время, бюджет, количество специалистов).
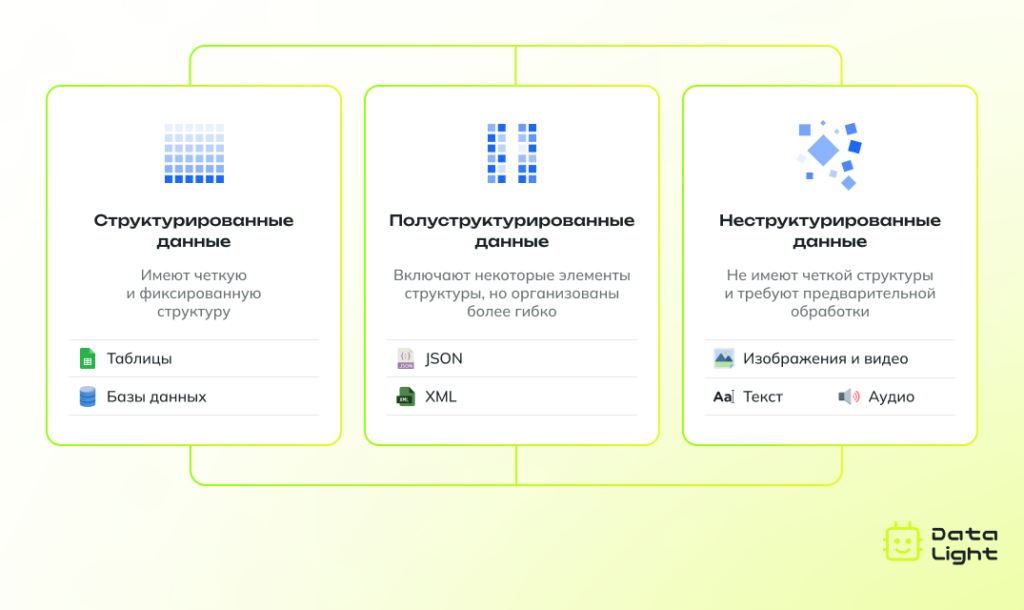
Типы данных в машинном обучении
Как определить количество данных, которое нужно собрать?
Оценка необходимого количества данных нередко вызывает затруднения даже у опытных разработчиков. «Больше — не всегда лучше», но и слишком малый объем данных не позволит алгоритму научиться достаточно хорошо решать задачи. Существует несколько общих подходов, которые помогут определиться с размером датасета:
- Исходите из цели и сложности задачи. Чем сложнее задача, тем больше данных может потребоваться. К примеру, модель, которая должна распознавать десятки разных классов объектов на изображениях, будет нуждаться в существенно большем объеме данных, чем модель, различающая всего пару категорий.
- Учитывайте разнообразие данных. Обучающий набор данных должен охватывать все возможные сценарии, с которыми модель столкнется в реальной работе: разные ракурсы и освещение на изображениях, вариативность фраз в текстах, различные условия записи аудиофайлов и т. д. Чем больше разнообразных ситуаций нужно учесть, тем больше данных потребуется.
- Проведите пробное обучение. Часто полезно начать с небольшого объема данных и посмотреть, каких результатов удастся достичь. Если результаты далеки от желаемых, нужно оценить, действительно ли проблема в недостатке данных, и при необходимости увеличить их количество. Такой подход помогает не тратить сразу все время и бюджет на сбор огромной выборки, которая может оказаться избыточной.
Таким образом, определение оптимального количества данных — это баланс между сложностью задачи, качеством и разнообразием необходимых примеров. Лучший способ убедиться в правильности выбранного пути — итеративно проверять результаты обучения и при необходимости расширять датасет.
Методы сбора данных
Существует множество методов сбора данных и каждый из них имеет свои особенности. Зачастую эффективнее всего использовать комбинированный подход, сочетая несколько методов в зависимости от потребностей проекта.
Краудсорсинг

Краудсорсинг — это метод, при котором данные собираются онлайн с помощью большого количества людей. Инструментами для этого могут послужить:
- Краудсорсинговые платформы;
- Социальные сети;
- Собственная аудитория исполнителей.
В каких случаях используется?
- Когда количество/разнообразие данных важнее качества. Часто этот пункт сопряжен с тем, что для проекта важно получить большое количество данных от разных людей, но организовать сбор на месте очень тяжело, дорого или невозможно.
- Когда задача проста и понятна, не требует специальных знаний или использования профессиональной техники. Это означает, что ее можно передать большому количеству исполнителей, которые точно смогут ее выполнить (например, если нужно просто сфотографировать какой-либо объект на телефон).
- Когда корректность полученных данных легко проверить. Это тесно связано с предыдущим пунктом. Краудсорсинг лучше всего подходит для задач с предсказуемым результатом, точность которого можно легко и однозначно оценить.
На что обратить внимание?
- Ограничения на сбор персональной информации. Записи голоса, изображения лиц, автономера, попавшие в кадр при съемке на улице, — это персональные данные, сбор которых требует соблюдения строгих юридических норм. В связи с этим политика некоторых краудсорсинговых платформ запрещает сбор подобной информации.
- Аудитория крауд-платформ. Разные платформы предоставляют доступ к разным категориям исполнителей. Если данные должны быть разнообразными, имеет смысл комбинировать как платформы, так и сами методы сбора.
- Скорость выплат. Если после выполнения задача долго проверяется и не оплачивается, она будет иметь низкий рейтинг среди других пользователей.
Качество инструкции. Короткая и непонятная инструкция приводит к ошибкам в собранных данных, так как исполнители могут неправильно понять задачу. Слишком длинная — тоже, так как ее не будут читать до конца. Оптимальный вариант — использовать графику и видео для наглядного объяснения задачи.
Сбор реальных данных (инхаус-сбор)
Сбор реальных данных — это метод, при котором информация собирается из окружающего мира самостоятельно (офлайн), чаще всего с помощью различных записывающих устройств. Он обеспечивает высокое качество и релевантность данных, особенно для задач компьютерного зрения или анализа поведения.
В каких случаях используется?
- Когда качество данных важнее количества/разнообразия. Этот метод подходит для задач, где требуется максимально высокое качество данных, которое невозможно обеспечить другим способом из-за сложности выполнения.
- Когда требуется четкое соблюдение сложного технического задания и контроль за исполнителем. Инхаус-сбор подходит для задач, которые требуют соблюдения сложных инструкций и контроля за процессом, что невозможно при краудсорсинге. Например, если нужно сделать фотографию с определенного расстояния или в конкретной позе, важно, чтобы кто-то следил за исполнителем и корректировал действия. Это позволяет гарантировать, что данные будут собраны без ошибок.
- Когда нужно использовать профессиональное оборудование. Это могут быть любые записывающие устройства, камеры, датчики, 3D-сканеры и т. д.
На что обратить внимание?
- Высокая стоимость. Этот метод может быть дорогостоящим, но при этом он обеспечивает более высокое качество данных по сравнению с другими.
Сложная организация процесса. Инхаус-сбор требует четкого планирования на каждом этапе: от поиска подходящего помещения и оборудования до организации контроля за исполнителями. Нужно учитывать юридические аспекты, бюджет, вопросы безопасности и многое другое. Любое упущение в организации может привести к ошибкам или дополнительным расходам.
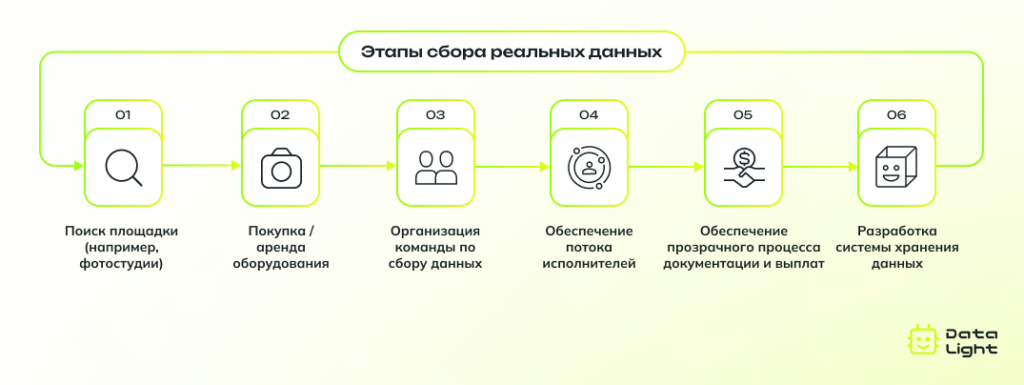
Инхаус-сбор внутри штата: опыт Data Light
Некоторые задачи по сбору данных сложнее стандартных, так как требуют дополнительной обработки информации.
Рассмотрим один пример. Допустим, нужно собрать данные для обучения системы распознавания принт-атак. Принт-атака — это метод обмана биометрических систем, когда злоумышленник использует распечатанное изображение лица, чтобы выдать его за свое.
Для обучения алгоритмов, способных выявлять такие атаки, нам нужно создать один набор данных, но его подготовка проходит в несколько этапов:
- Сбор исходных фотографий лиц
В первую очередь нужно собрать большое количество снимков реальных людей. Чем больше фотографий, тем лучше алгоритм научится различать особенности лиц. Поэтому здесь важен масштаб — требуется собрать сотни или даже тысячи изображений. Для этого можно использовать классический инхаус-сбор или краудсорсинг, если нет юридических ограничений.
- Моделирование принт-атак
После того, как базовый набор фотографий собран, нужно создать изображения, имитирующие принт-атаки. Для этого несколько человек фотографируются, держа в руках распечатанные копии ранее собранных лиц. Так как лица самих исполнителей не видны, достаточно небольшой группы участников. Эту часть мы в Data Light, как правило, выполняем самостоятельно, чтобы контролировать процесс и качество материалов. В каком-то смысле этот опыт можно назвать разновидностью инхаус-сбора — сбором внутри штата компании.
В каких случаях используется?
- Когда не требуется большого количества исполнителей.
- Когда задача простая и понятная.
- Когда основа данных уже собрана.
Генерация синтетических данных

Генерация синтетических данных — это метод, при котором нужные примеры создаются искусственно с помощью алгоритмов. Например, для тренировки моделей по распознаванию паспортных данных могут быть использованы синтетические изображения, созданные с помощью 3D-моделирования.
В каких случаях используется?
- Когда собирать реальные данные очень дорого, долго или невозможно.
- Когда требуется использование персональных данных. В этом состоит главное преимущество синтетических данных. Их использование помогает избежать рисков, связанных с конфиденциальностью, так как в них отсутствует информация о реальных людях.
- Когда необходимо дополнить редкие классы данных. Генерация синтетических данных часто используется как дополнительный инструмент, позволяющий расширить уже собранный набор реальных данных, где некоторых примеров изначально было недостаточно.
На что обратить внимание?
- Необходимость реальных данных. Генеративные алгоритмы требуют исходных данных для обучения. Даже при создании синтетического набора потребуется реальная выборка в качестве шаблона.
- Возможные артефакты. Синтетические данные могут содержать артефакты, незаметные для человека, но влияющие на обучение модели. Это может привести к некорректным предсказаниям, если модель начнет ориентироваться на эти артефакты вместо реальных закономерностей. Поэтому перед использованием важно проверять качество сгенерированных данных.
Рекомендации по сбору данных
- Старайтесь собирать полные и качественные данные. Качество данных напрямую влияет на точность модели, поэтому важно убедиться, что все примеры релевантны задаче, не содержат дубликатов и не устарели. Если информация будет неполной или недостоверной, даже ее большой объем не обеспечит хороших результатов.
- Соблюдайте требования законодательства. Если вы собираете фото, видео, аудиозаписи или другую информацию, которая позволяет установить личность человека, крайне важно соблюдать законы о защите персональных данных. Это может включать подписание юридических соглашений и анонимизацию данных перед использованием.
- Комбинируйте методы. Использование нескольких методов помогает получить более разнообразный и качественный набор и решить проблемы с нехваткой данных.
- Документируйте процесс. Записывайте, какие инструменты и методы вы применяли при сборе, какие требования предъявляли исполнителям и на что ориентировались при проверке качества. Такая документация помогает всей команде понимать, из чего состоит набор и как он создавался, а также упрощает пересмотр подходов к сбору, если результаты окажутся не такими, как ожидалось.
- Актуализируйте данные со временем. В некоторых сферах информация довольно быстро теряет актуальность, поэтому периодически оценивайте, нужно ли дообучить модель на новых, актуальных примерах.
Ключевые выводы
Сбор данных — это важнейший этап в процессе разработки моделей машинного обучения. Он требует тщательной подготовки, внимания к деталям и использования правильных методов и инструментов. Грамотно организованный процесс сбора данных помогает избежать множества проблем в дальнейшем, таких как ошибки модели, ее низкая точность или недостаточная репрезентативность.
Правильный сбор данных — это не просто подготовка информации для модели, но и залог того, что она будет работать качественно и эффективно, помогая решать реальные задачи. Поэтому стоит инвестировать время и ресурсы в организацию этого этапа, обеспечивая баланс между качеством, количеством и актуальностью данных.