 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыЧто такое компьютерное зрение?
Компьютерное зрение — это междисциплинарная область, находящаяся на стыке искусственного интеллекта, обработки сигналов и распознавания образов. В отличие от традиционной обработки изображений, которая фокусируется на низкоуровневых операциях (фильтрация, изменение контраста), компьютерное зрение стремится к высокоуровневому пониманию визуальной сцены, подобно тому, как это делает человек. Основная цель этой технологии — научить машины распознавать и понимать объекты, сцены и события на изображениях, а затем использовать эту информацию для принятия решений и автоматизации процессов.
По данным Grand View Research, в 2024 году мировой рынок компьютерного зрения оценивался в 19,8 миллиардов долларов. Прогнозируется, что к 2030 году этот показатель достигнет 58,29 миллиардов долларов при среднегодовом темпе роста (CAGR) в 19,8%.
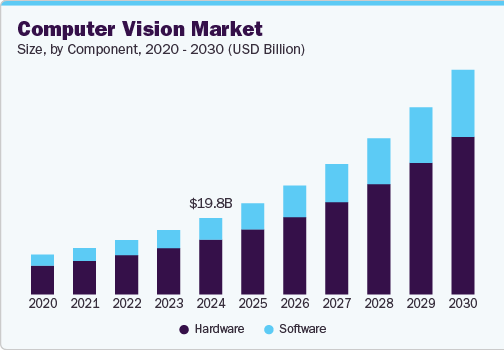
Подобный рост связан с тем, что все больше отраслей внедряют компьютерное зрение для решения реальных задач:
- Промышленность: Автоматизация контроля качества, роботизированные манипуляторы, управление складскими запасами.
- Торговля: Анализ покупательского поведения, персонализированные рекомендации, автоматизированные кассы.
- Медицина: Помощь в диагностике заболеваний (анализ рентгеновских снимков, МРТ, КТ), роботизированная хирургия.
- Безопасность: Интеллектуальное видеонаблюдение, распознавание лиц, обнаружение аномального поведения.
- Автомобилестроение: Беспилотные автомобили, системы помощи водителю (ADAS).
- Сельское хозяйство: Мониторинг состояния посевов, автоматизированный сбор урожая.
История развития компьютерного зрения: от традиционных методов до нейросетей
Идея обучить машины «видеть» зародилась еще в 1960‑х годах, когда ученые начали экспериментировать с анализом изображений и видео. Ранние исследования были связаны с попытками научить компьютер распознавать геометрические фигуры и простейшие объекты. В то время разработчики полагались на жестко заданные правила: они описывали, какие признаки характерны для определенного объекта (края, углы, силуэты), а алгоритмы сопоставляли эти признаки с пикселями изображения.
Однако такой подход имел серьезные ограничения:
- Трудоемкость: Создание правил для распознавания сложных объектов требовало огромных усилий и времени.
- Низкая устойчивость: Даже небольшие изменения освещения, ракурса или фона могли привести к сбою в работе алгоритма.
- Ограниченная обобщающая способность: Правила, разработанные для одних объектов, часто не работали для других.
- Проблема извлечения признаков: Необходимо было вручную определять, какие признаки являются важными для распознавания, что было сложной задачей, особенно для неструктурированных объектов (лица, деревья и т. д.).
Переломным периодом стали 2000‑е годы, когда компьютерное зрение начало быстро развиваться благодаря нескольким важным изменениям:
- Появление больших наборов данных: С развитием интернета и цифровых технологий стали доступны огромные массивы размеченных изображений (например, ImageNet), необходимые для обучения сложных моделей.
- Увеличение вычислительных мощностей: Появление мощных графических процессоров (GPU) позволило значительно ускорить процесс обучения нейронных сетей.
- Развитие алгоритмов глубокого обучения: Были разработаны новые архитектуры нейронных сетей (в первую очередь, сверточные нейронные сети), способные автоматически извлекать иерархические признаки из изображений без необходимости ручного программирования.
Этот технологический скачок привел к революции в компьютерном зрении, позволив создавать модели, значительно превосходящие по точности и надежности традиционные алгоритмы обработки изображений. С тех пор глубокое обучение стало основой для большинства современных систем компьютерного зрения.
Что такое глубокое обучение?
Глубокое обучение — это подобласть машинного обучения, вдохновленная структурой и функцией человеческого мозга. В его основе лежат искусственные нейронные сети — математические модели, состоящие из множества взаимосвязанных узлов (нейронов), организованных в слои.
Вместо того чтобы использовать фиксированные правила, такие модели обучаются на конкретных примерах, анализируя большие объемы размеченных данных (изображения, видео). В процессе обучения данные проходят через последовательность слоев нейронной сети, где на каждом этапе выделяются все более сложные и абстрактные признаки. Это позволяет модели постепенно формировать представление о том, что она видит, и эффективно решать задачи распознавания, классификации и генерации изображений.
Существует множество различных архитектур нейронных сетей, каждая из которых лучше подходит для решения определенных задач. Например, рекуррентные сети (RNN) хорошо работают с последовательными данными (речь, текст), а генеративно-состязательные сети (GAN) создают новые изображения на основе имеющихся примеров. Для компьютерного зрения наиболее важными являются сверточные нейронные сети (Convolutional Neural Networks, CNN).
Сверточные нейронные сети: принцип работы
1. Входные данные
На вход сети подается изображение в виде трехмерного тензора. Для цветного изображения (например, в формате RGB) это трехмерный тензор, где первое измерение соответствует высоте изображения, второе — ширине, а третье — количеству цветовых каналов (обычно 3: красный, зеленый, синий).
2. Сверточные слои
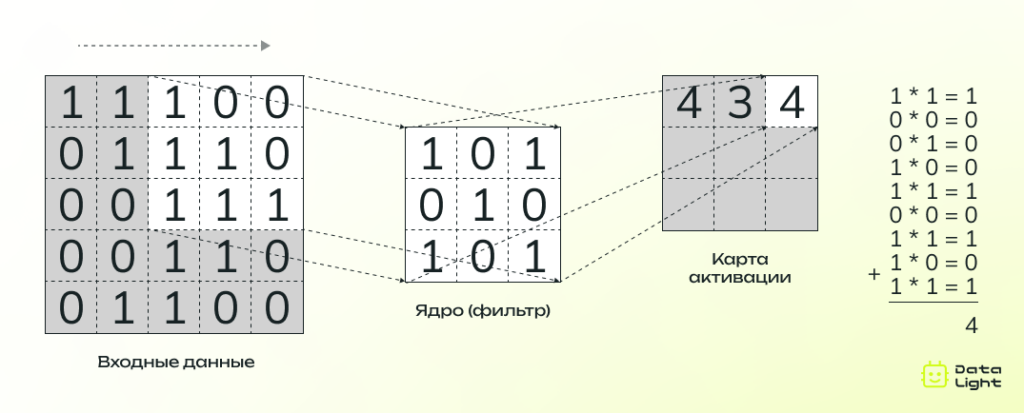
В каждом сверточном слое к изображению (или результату предыдущего слоя) применяются специальные фильтры (ядра свертки) — небольшие многомерные массивы (обычно 3×3, 5×5 или 7×7), содержащие весовые коэффициенты, которые обучаются в процессе тренировки. Они «скользят» по всей области изображения или выходу предыдущего слоя, выполняя операцию свертки: в каждой позиции ядро поэлементно умножает свои веса на соответствующие значения пикселей входных данных, а затем суммирует результаты. Полученное число становится элементом карты признаков.
- Карты признаков (Feature Maps): Каждый фильтр генерирует свою карту признаков. Разные фильтры обучаются обнаруживать разные признаки: одни — горизонтальные линии, другие — вертикальные, третьи — диагональные, четвертые — углы и т. д. На более глубоких слоях фильтры учатся обнаруживать более сложные и абстрактные признаки, являющиеся комбинациями признаков с предыдущих слоев.
- Нелинейность (ReLU): После каждого сверточного слоя обычно применяется функция активации, чаще всего ReLU (Rectified Linear Unit).
3. Уплотняющие слои (Pooling)
После свертки часто следует операция пулинга (Pooling) — сжатие карты признаков, которое уменьшает ее размерность, убирая избыточные детали и повышая устойчивость модели к небольшим сдвигам, искажениям и шуму.
- Max Pooling: Выбирает максимальное значение из небольшой области (обычно 2x2) карты признаков.
- Average Pooling: Вычисляет среднее значение из небольшой области карты признаков.
4. Полносвязные слои (Fully Connected Layer)
В финале сети несколько полносвязных слоев интегрируют информацию из предыдущих слоев и выдают итоговое решение — например, вероятность принадлежности к определенному классу («собака», «кошка», «автомобиль» и т. д.).
5. Выходной слой (Output Layer)
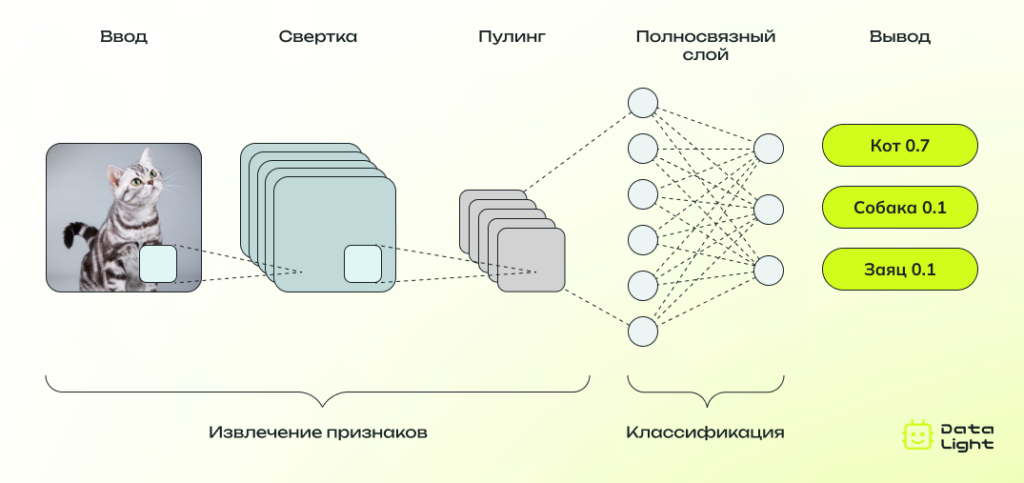
Результат CNN — набор вероятностей для всех возможных классов или иные параметры (например, координаты найденных объектов). Модель обучается корректировать эти вероятности, чтобы ошибки становилось меньше после каждой итерации.
В зависимости от задачи, выходной слой может иметь разную структуру:
- Классификация: Для задачи классификации выходной слой обычно содержит столько нейронов, сколько классов, и использует функцию активации softmax, которая преобразует выходы нейронов в вероятности принадлежности к каждому классу.
- Регрессия: Для задачи регрессии (например, предсказание координат объекта) выходной слой может иметь один или несколько нейронов, представляющих собой предсказываемые значения.
Другие задачи: Для других задач, например, детекции объектов, выходной слой имеет более сложную структуру, специфичную для каждой конкретной задачи.
Типы задач и примеры архитектур в компьютерном зрении
Компьютерное зрение охватывает широкий спектр задач, от простых (классификация изображений) до чрезвычайно сложных (понимание сцены в реальном времени). Выбор архитектуры нейронной сети во многом определяется конкретной задачей и требованиями к точности, скорости и вычислительным ресурсам. Рассмотрим основные типы задач и примеры архитектур, которые часто используются для их решения, а также критические соображения при выборе архитектуры.
Классификация изображений
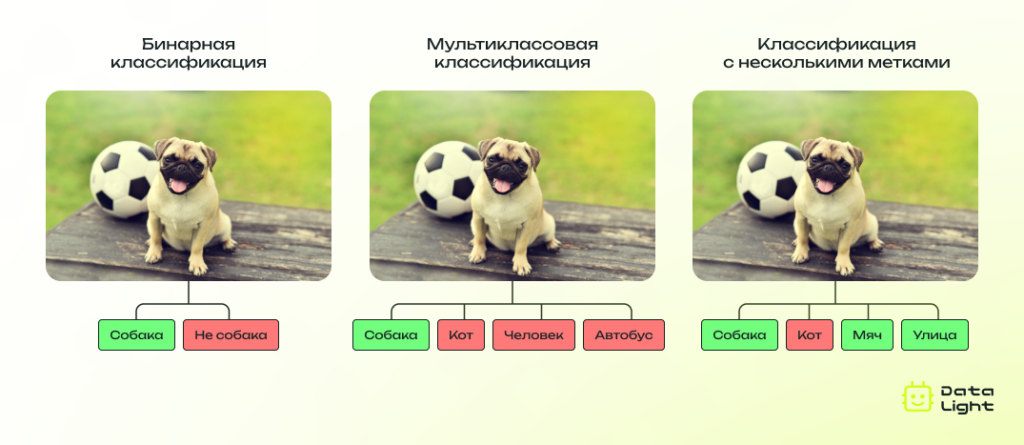
Классификация изображений часто рассматривается как базовая задача в компьютерном зрении. Цель состоит в том, чтобы определить к какому классу (или классам) относится содержимое изображения. Например, определить, изображена ли на фотографии кошка, собака, автомобиль или что-то другое.
Примеры архитектур:
- VGG: Простая и глубокая архитектура, хорошо подходит для базовой классификации.
- Inception (GoogLeNet): Более эффективная архитектура, чем VGG, за счет использования Inception-модулей.
- ResNet: Позволяет строить очень глубокие сети за счет использования skip connections, что часто приводит к более высокой точности.
- EfficientNet: Семейство архитектур, оптимизированных для достижения высокой точности при ограниченных вычислительных ресурсах.
- MobileNet: Архитектура, специально разработанная для мобильных и встраиваемых устройств.
Критические соображения:
- Для простых задач (например, классификация небольшого числа четко различимых классов) может быть достаточно VGG или даже более простой архитектуры.
- Для сложных задач (например, классификация тысяч классов с тонкими различиями) требуется более глубокая и сложная архитектура, такая как ResNet или EfficientNet.
- Если важна скорость работы, а не максимальная точность, можно использовать EfficientNet или MobileNet.
Детекция объектов

Детекция объектов позволяет не только классифицировать объекты на изображении, но и указать их местоположение. Для этого используются ограничивающие рамки (bounding boxes).
Примеры архитектур:
- YOLO (You Only Look Once): Быстрая одноэтапная архитектура, обрабатывающая все изображение целиком.
- SSD (Single Shot MultiBox Detector): Одноэтапная архитектура, похожая на YOLO, но использующая несколько масштабов для обнаружения объектов разных размеров.
- Faster R‑CNN: Двухэтапная архитектура. Сначала генерируются предложения регионов (region proposals), а затем каждый регион классифицируется и уточняются его границы. Обычно работает более точно, но и медленнее, чем YOLO или SSD.
- Mask R‑CNN: Расширение Faster R‑CNN, которое дополнительно выполняет сегментацию объектов (определяет пиксели, принадлежащие каждому объекту).
Критические соображения:
- Если важна скорость работы в реальном времени (например, для беспилотных автомобилей), предпочтительнее YOLO или SSD.
- Если важна максимальная точность, а скорость не так критична, можно использовать Faster R‑CNN.
- Если требуется не только детекция, но и сегментация объектов, используется Mask R‑CNN.
Сегментация изображений

Сегментация подразумевает разделение изображения на области с точным определением границ каждого объекта. Существует несколько подходов к сегментации:
- Семантическая сегментация (Semantic Segmentation): Каждому пикселю изображения присваивается метка класса. Все пиксели, принадлежащие одному классу, объединяются в один сегмент.
- Инстанс-сегментация (Instance Segmentation): Каждому пикселю присваивается метка класса и идентификатор экземпляра объекта. Например, два объекта на изображении будут иметь разные метки, даже если они принадлежат одному классу.
- Паноптическая сегментация (Panoptic Segmentation): Объединяет в себе два подхода: семантическую и инстанс-сегментацию, позволяя одновременно разделять изображение на классы объектов и различать их экземпляры.
Примеры архитектур:
- U‑Net: Архитектура, изначально разработанная для сегментации медицинских изображений, но широко используемая и в других областях. Имеет U‑образную форму, со «сжимающим» (encoder) и «расширяющим» путем (decoder).
- DeepLab: Семейство архитектур, использующих atrous convolution (dilated convolution) для увеличения receptive field без потери разрешения.
- Mask R‑CNN: (Уже упоминалась в разделе про детекцию объектов). Позволяет выполнять как сегментацию, так и детекцию объектов.
- PSPNet (Pyramid Scene Parsing Network): Использует пирамидное представление признаков для учета контекста на разных масштабах.
Критические соображения:
- Выбор архитектуры зависит от типа сегментации (семантическая, инстанс, паноптическая) и требований к точности и скорости.
- Для медицинских изображений часто используется U‑Net из-за ее способности эффективно работать с небольшими наборами данных.
Роль данных в обучении моделей
Данные являются фундаментом любой модели компьютерного зрения. Без качественного набора обучающих данных даже самая современная архитектура нейросети не сможет научиться хорошо решать поставленную задачу. Ниже перечислены ключевые аспекты, связанные с данными и их подготовкой:
Объем
Для обучения сложных моделей глубокого обучения, как правило, требуются очень большие наборы данных (сотни тысяч, миллионы или даже миллиарды изображений). Чем больше данных, тем лучше модель сможет обобщить знания и научиться распознавать объекты в различных условиях.
Разнообразие
Данные должны быть разнообразными и охватывать все возможные сценарии использования. Например, для обучения системы распознавания дорожных знаков необходимо собрать изображения знаков, снятых в разное время суток, при разной погоде, с разных ракурсов, с разным освещением, с разной степенью загрязнения и т. д.
Качество разметки
Точность распознавания напрямую зависит от качества разметки. Если в датасете есть ошибки (неправильные метки или неверно выделены границы объектов), нейросеть учится на искаженных примерах и впоследствии будет выдавать некорректные результаты. Кроме того, разметка должна быть согласованной. Если разные разметчики размечают одни и те же данные по-разному, это также приводит к ухудшению качества модели.
Баланс классов
Несбалансированный датасет, в котором, например, 90% данных относятся к одному классу, а лишь 10% — к другому, может привести к тому, что модель начнет игнорировать редкий класс и всегда выбирать доминирующий. Решить эту проблему можно несколькими способами:
- Сбор дополнительных данных: Для редких классов.
- SMOTE (Synthetic Minority Oversampling Technique): Генерация синтетических примеров редких классов на основе существующих.
- Oversampling: Дублирование примеров редких классов.
- Undersampling: Удаление части примеров доминирующего класса.
- Взвешенные функции потерь (Weighted Loss Functions): Присвоение большего веса редким классам, чтобы модель учитывала их наравне с доминирующими.
Еще один способ уменьшить дисбаланс — аугментация данных (Data Augmentation), то есть искусственное увеличение размера обучающего набора за счет изменения существующих примеров. В компьютерном зрении это достигается с помощью различных преобразований изображений.
Основные типы преобразований:
- Геометрические преобразования: Повороты, сдвиги, отражения, масштабирование, кадрирование.
- Цветовые изменения: Корректировка яркости, контрастности, насыщенности, цветового тона.
- Добавление шума: Например, гауссовского шума.
- Mixup: Создание новых примеров путем смешивания двух случайных изображений и их меток.
- Cutout: Случайное удаление части изображения.
- CutMix: Комбинация Mixup и Cutout.
Конфиденциальность
Персональные данные должны собираться с согласия пользователей и обрабатываться в соответствии с локальными законами о защите информации. Чтобы минимизировать риски утечки и неправомерного использования, применяются различные методы защиты данных:
- Анонимизация данных: Удаление или изменение персональной информации (например, размытие лиц на изображениях).
- Федеративное обучение (Federated Learning): Обучение модели на децентрализованных данных, без необходимости передачи данных на центральный сервер.
- Дифференциальная приватность (Differential Privacy): Добавление шума к данным таким образом, чтобы затруднить идентификацию отдельных лиц, но при этом сохранить возможность обучения модели.
Таким образом, сбор и подготовка качественных данных — это не менее важная часть проекта, чем разработка самой архитектуры нейросети. Часто именно грамотно сформированный датасет обеспечивает реальный «скачок» в качестве решений компьютерного зрения. Компании и исследователи уделяют все больше внимания сбору и разметке больших, разнообразных датасетов, а также вопросам надежности и точности разметки.
Ключевые выводы
Компьютерное зрение — это технология, которая позволяет машинам анализировать и интерпретировать визуальную информацию. Развитие этой области прошло путь от простых алгоритмов, основанных на жестких правилах, до мощных нейросетевых моделей, которые способны автоматически извлекать и обрабатывать сложные признаки изображений. Благодаря растущему объему доступных данных и увеличению вычислительных мощностей компьютерное зрение продолжает стремительно развиваться, расширяя границы своего применения — от медицины и беспилотных автомобилей до розничной торговли и промышленности.