 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыКогда речь идет о глобальном тренде сегодняшнего дня — искусственном интеллекте и машинном обучении, то первое, о чем мы говорим — это о данных.
Существование любой модели начинается с данных, и именно высококачественные данные являются секретом ее эффективного обучения. Давайте вместе разберемся, в чем специфика разных видов разметки данных для машинного обучения, какие тенденции в ней есть и какие тонкости нужно учитывать при аннотации в 2025 году.
Для кого этот гайд? Эту подробную статью мы писали для:
- Всех предпринимателей, которым регулярно приходится обрабатывать большие объемы данных.
- Руководителей проектов, стремящихся сократить время вывода на рынок своих продуктов на основе ИИ.
- И для всех технических энтузиастов, которым хочется узнать больше о машинном обучении.
Неважно, новичок вы в разметке данных или профессионал, этот материал будет вам полезен.
Что такое разметка данных
Если в двух словах, то разметка или аннотация данных — это процесс добавления значимых и информативных меток к набору данных, чтобы облегчить машинным алгоритмам понимание и обработку информации. Без нее алгоритмы машинного обучения терялись бы в море неструктурированных данных.
А данными для машинного обучения может выступать почти что угодно. Так, мы можем размечать изображения разных животных, чтобы отличать их между собой, или фото растений, чтобы обучить модель находить сорняки, текст в переписках с виртуальным помощником, чтобы он мог лучше распознавать настроение собеседника, или даже опухоли на медицинских снимках, чтобы позже их могла находить и модель.
Если ответить на этот вопрос очень коротко, то всем. К нам обращались клиенты из совершенно разных индустрий: e‑commerce, тяжелая промышленность, СМИ, агропромышленность и видеоаналитика. Но вот несколько частотных случаев использования:
Разметка данных в здравоохранении
Разметка данных для медицинских изображений играет ключевую роль в разработке инструментов анализа медицинских изображений на основе ИИ. Это очень непростой тип разметки: на проект приходится нанимать только опытных специалистов с профильным образованием.
Разметчики размечают медицинские изображения (такие как рентгеновские снимки, МРТ) для выделения опухолей и заболеваний. Например, разметка данных очень важна для обучения моделей машинного обучения в системах диагностики рака кожи. Уже сейчас такие системы с высокой эффективностью распознают злокачественные новообразования.
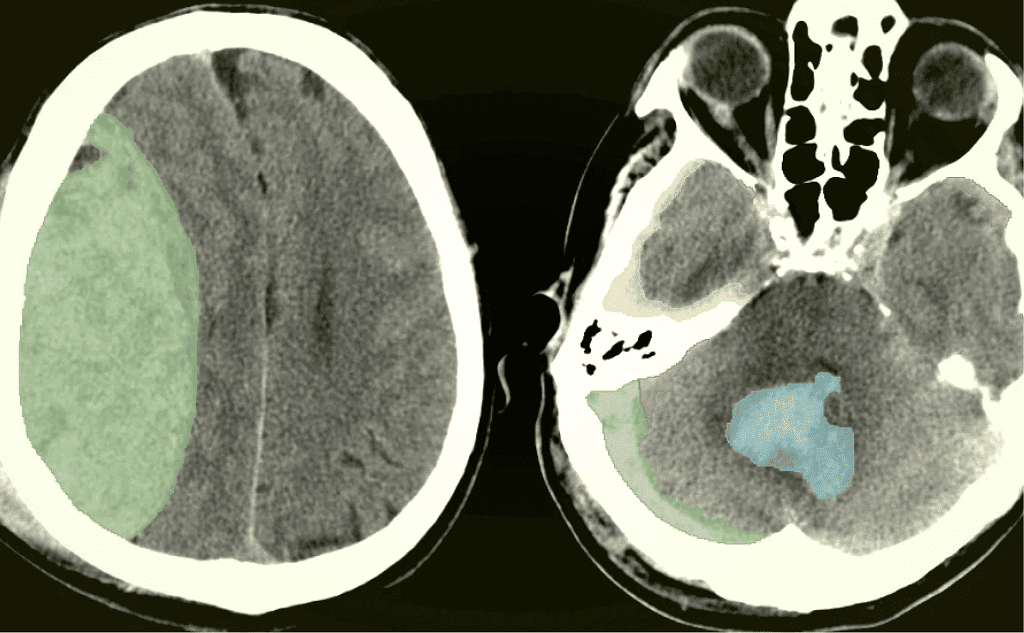
А еще исполнители маркируют электронные медицинские записи (EMR) и клинические заметки, что помогает в разработке систем компьютерного зрения для диагностики заболеваний и автоматизированного анализа медицинских данных.
Разметка данных в финансовом секторе
В финансовом секторе также есть несколько примеров использования разметки: от выявлений мошенничества до анализа настроений в финансовых новостях. Разметчики маркируют транзакции или новостные статьи как мошеннические, обучая модели ИИ автоматически определять подозрительную активность и даже выявлять потенциальные рыночные тренды.
Разметка данных в автомобильной промышленности
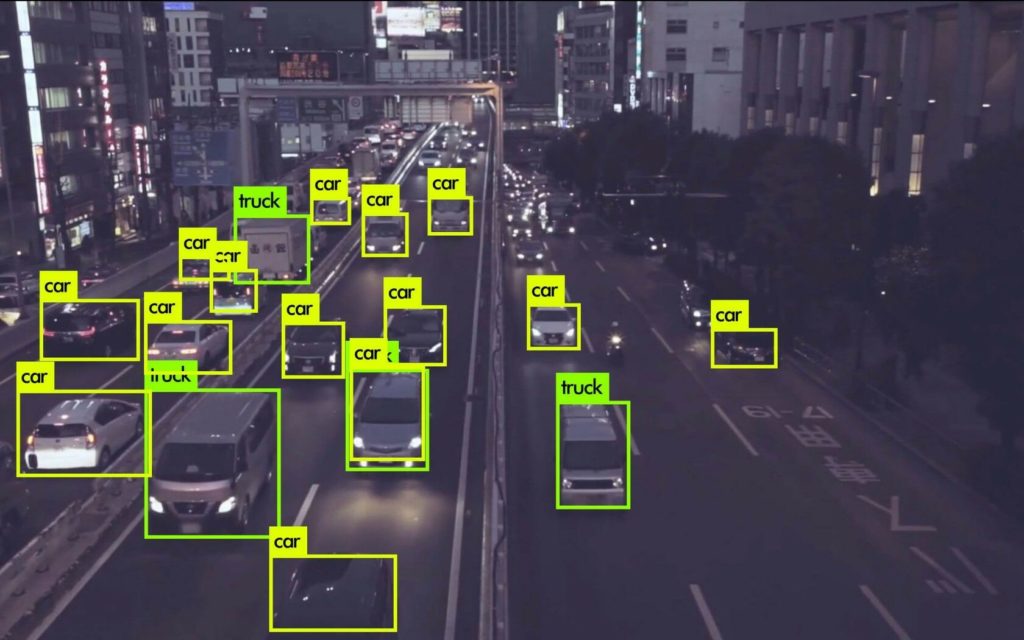
Разметка данных в автомобильной промышленности включает маркировку данных от автономных транспортных средств. Обычно это информация с камер и LiDAR-датчиков. Эта разметка помогает создавать модели для обнаружения объектов в окружающей среде и обработки других критически важных данных для систем автономных транспортных средств.
К примеру, к нам обращались с запросом разметить дорожные знаки, чтобы определять ограничения скорости, предупреждающие знаки и полосы движения. В результате система научилась распознавать и корректно реагировать на знаки (К примеру, “Стоп” или “Уступи дорогу”). Очевидно, насколько это важно для предотвращения аварий.
Кому нужна разметка в 2024? Топ бизнесов и индустрий
Разметка данных на производстве
В последние годы разметка данных все больше используется для развития интеллектуальных роботов и автоматизированных систем на производстве. Так, наши клиенты заказывали разметку, чтобы обучить модели AI выбирать предметы на складе или определять потенциальные неисправности оборудования на основе данных с датчиков.
А еще разметка данных в промышленности используется для маркировки данных из различных промышленных приложений, включая изображения с производства, данные о техническом обслуживании или безопасности и информацию о контроле качества.
Этот тип разметки данных помогает создавать модели, способные обнаруживать аномалии и обеспечивать безопасность работников, к примеру, проверять наличие касок во время работы на производстве.
Разметка данных в e‑commerce
Тут довольно часто используется разметка изображений продуктов и пользовательских отзывов для персонализированных рекомендаций и анализа настроений. Но есть и более необычные кейсы: для наших клиентов мы делали детекцию товаров на полках.

Так заказчик смог упростить инвентаризацию и иметь точные данные о продажах. Для этого мы разметили более 34 тысяч изображений.
Также у нас был кейс, где крупная сеть супермаркетов обратилась к нам с задачей автоматической обработки чеков в своем приложении. Для этого же приложения необходима была возможность считывания штрих-кодов, поэтому мы также разметили их номера и границы. Это позволило заказчику обеспечить корректное считывание данных прямо в приложении.
Разметка данных в строительстве
В строительной индустрии разметка играет ключевую роль, например она используется в задачах, связанных с интерьерами. Один из таких недавних кейсов — сегментация стен интерьеров, где необходимо было размечать все стены, и отличать их от других элементов, таких как полы. Благодаря нашему сотрудничеству клиент смог обучить приложение автоматически рассчитывать площадь и подбирать подходящие интерьеры по фотографии.
3. Как работает разметка данных
Сбор данных
Первый и один из самых важных этапов любого проекта машинного обучения, который предшествует разметке — это сбор достаточного объема необработанных данных. Эти данные могут включать изображения, аудиофайлы, видеозаписи, тексты и другие формы информации, которые будут использованы для обучения модели. Источники данных зависят от специфики компании: одни организации самостоятельно накапливают данные в течение многих лет, собирая информацию из различных внутренних систем, датчиков или пользовательских взаимодействий.
Другие компании полагаются на внешние, публично доступные наборы данных. Также некоторые собирают их благодаря краудсорсингу — процессу, где для выполнения задач по сбору и разметке данных привлекается большое количество исполнителей из интернета.
При этом одна задача разбивается на большое количество маленьких, которые передаются исполнителям.
Примеры заданий на сбор фото через платформу Яндекс Задания:
Однако на этом этапе часто возникает ряд проблем. Сырые данные могут быть разрозненными, неполными или поврежденными, что делает их неподходящими для прямого использования в моделировании. Например, изображения могут быть низкого качества или иметь незначительные различия, аудиофайлы — содержать шумы, а тексты — включать орфографические ошибки и неоднозначные формулировки.
Чтобы обеспечить успешное обучение модели, данные необходимо очистить, удалить дубликаты, устранить ошибки и привести к единому формату. Этот процесс может включать нормализацию данных, удаление шума, заполнение пропусков и устранение некорректных значений.
Разметка данных
После того как данные очищены, наступает этап разметки. Можно сказать, что он является центральным в процессе подготовки данных. Например, на изображениях метки могут указывать на конкретные объекты, такие как автомобили, пешеходы или дорожные знаки.

Также мы можем классифицировать объекты на фото: к примеру, определять, какая комната изображена на снимке.
Разметчики могут отмечать площадь, расстояние, движение на видео. В текстах метки могут определять части речи, намерения или эмоциональный тон.
Разметка выполняется специалистами, которые знают специфику задачи и способны точно идентифицировать и пометить ключевые элементы данных. Точность разметки имеет решающее значение, так как эти метки будут использоваться в качестве эталонных данных (ground truth) для обучения модели. Плохое качество разметки может привести к неверным прогнозам и снижению общей эффективности модели. В сложных проектах могут использоваться полуавтоматические методы аннотирования с последующей ручной проверкой для повышения точности.
Контроль качества
Качество данных играет ключевую роль в успехе проекта машинного обучения. Данные должны быть не только точными и согласованными, но и полноценно отражать реальный мир, который модель должна будет интерпретировать. Контроль качества (QA) данных направлен на обеспечение того, чтобы метки были правильно добавлены к каждому обучающему примеру, а сами данные были целостными и корректными.
К примеру, в Data Light мы имеем специальный отдел, который следит за качеством на проектах. За 5 лет наша команда нашла уникальный подход к оценке контроля качества каждого кейса.

Эффективность работы отдела контролируется через пять ключевых аспектов: тестирование, скорость, согласованность, повторный мониторинг и показатель ошибок при апелляциях. Эти показатели позволяют нам управлять ресурсами: назначать или освобождать валидаторов от проекта и разбирать важные моменты на встречах.
Скорость
Отдел Контроля качества влияет на темпы выполнения проекта, так как валидация данных обязательна. Чем быстрее завершается проверка, тем скорее проект будет готов. Отдел Контроля качества имеет свои метрики по скорости, чтобы обеспечить своевременную сдачу.
Согласованность
Для нас важно, чтобы решения по одинаковым кейсам были единообразными, поэтому мы проверяем согласованность работы команд. Один и тот же кейс дается разным валидаторам для самостоятельного решения. Также в проверке участвуют руководители групп, которые являются экспертами в техническом задании.
Повторный мониторинг
Для контроля качества работы отдела проводится ремониторинг. Мы делаем выборку ответов каждого валидатора, чтобы убедиться в правильности его действий, знании обновлений, и отсутствии повторяющихся ошибок. Это помогает проверить, правильно ли он трактует случаи и корректно ли применяет необходимые изменения.
Показатель ошибок при апелляциях
Нам важно оценить, сколько апелляций по ошибкам, найденным ОКК, было у руководителей групп, и сколько из них оказались обоснованными. Этот показатель помогает отслеживать точность работы и минимизировать затраты времени на апелляции.
За это время мы также определили три ингредиента для обеспечения эффективного контроля качества на проекте. Для начала важно правильно выбрать метрики, которые будут соответствовать его специфике. Стандартные метрики, такие как error rate, не всегда подходят для всех проектов, поэтому важно найти подходящие для каждого случая.
Также необходима репрезентативная выборка, которая должна включать достаточный объем данных и отражать разнообразие кейсов, а не просто ряд доступных примеров, собранных одновременно. Важно и правильно определиться с количеством: зачастую, чтобы проверить миллион размеченных изображений, достаточно сделать выборку из 400.
Кроме того ключевую роль играет работа с экспертами, которые специализируются в узких направлениях, что позволяет им углубленно понимать конкретные задачи. Хотя иногда, чтобы избежать замыливания взгляда, эксперты могут работать над смежными проектами, которые им тоже интересны.
Так что контроль качества — это непрерывный процесс, который требует постоянного мониторинга и корректировок, чтобы избежать ошибок и поддерживать высокую точность модели.
Обучение и тестирование модели
После завершения всех подготовительных этапов начинается обучение модели на размеченных данных. Этот процесс предполагает использование очищенных и аннотированных данных для настройки модели, чтобы она могла выявлять закономерности и делать прогнозы. Важно, чтобы данные, использованные для обучения, представляли собой широкий и разнообразный спектр случаев, охватывая все возможные сценарии, с которыми модель может столкнуться в реальных условиях.
В случае неудовлетворительных результатов модель может быть дообучена с использованием новых данных или более сложных алгоритмов, а еще могут быть введены дополнительные корректировки в процесс аннотирования и очистки данных. Таким образом, обучение и тестирование модели — это итеративный процесс, направленный на достижение наилучших возможных результатов в условиях реального применения.
При этом при сборе, разметке и контроле качества мы можем использовать автоматизацию и разрабатывать пайплайны, которые ускоряют работу на каждом этапе. Кстати, про автоматизацию разметки подробнее мы напишем чуть ниже.
Виды разметки данных
А еще разметка охватывает различные виды данных: изображения, текст, аудио и видео. Для лучшего понимания мы разбили каждый тип на отдельные элементы. Давайте рассмотрим их по отдельности.
Разметка изображений
Обычно этот тип разметки нужен, когда мы говорим о задачах, где важно распознавание лиц, компьютерное зрение, роботизированное зрение ( оно позволяет автономному роботу лучше распознавать предметы, перемещаться и находить объекты). Когда специалисты по искусственному интеллекту обучают такие модели, они добавляют к изображениям атрибуты: подписи, идентификаторы и ключевые слова. Затем алгоритмы определяют и понимают эти параметры и учатся автоматически.
Чтобы лучше понять этот пример, подумайте о масках в социальных сетях или модных раньше приложениях для смены цвета глаз или волос. Благодаря данным, на которых они были обучены, они могут мгновенно определить ваши глаза, нос или брови. Именно поэтому фильтры, которые вы применяете, идеально подходят независимо от формы вашего лица, насколько близко вы находитесь к камере и других факторов. Все это стало возможно благодаря разметке изображений.
Классификация изображений
Классификация изображений включает присвоение заранее определенных категорий или меток изображениям на основе их содержимого. Этот тип разметки используется для обучения моделей ИИ автоматическому распознаванию и классификации изображений.
К примеру, недавно мы завершили проект, где нужно было классифицировать различную строительную технику. Для него по видео мы размечали различные виды машин, которые работали на стройке в разное время.
Благодаря этому клиент смог обучить свои алгоритмы распознавать, какая техника находится на участке в реальном времени. Это позволяет более точно координировать работу, оптимизировать распределение ресурсов, предотвращать простои и улучшать общую производительность на стройке.
Распознавание/обнаружение объектов
Распознавание объектов или их обнаружение – это процесс идентификации и маркировки конкретных объектов на изображении. Этот тип разметки используется для обучения моделей ИИ поиску и распознаванию объектов в реальных изображениях или видео.

Так, в одном из проектов нам нужно было размечать различные типы документов, включая иностранные номера, водительские права и свидетельства о рождении. Задача состояла в выделении ключевых сущностей, таких как имя владельца, дата выдачи, марка автомобиля и другие важные данные, причем документы были на разных языках.
Сегментация
Сегментация изображений включает разделение изображения на несколько сегментов или областей, каждая из которых соответствует конкретному объекту или зоне интереса. Этот тип аннотации используется для обучения моделей ИИ анализу изображений на уровне пикселей, что позволяет более точно распознавать объекты и понимать сцены.
К примеру, у нас было несколько проектов, для которых нам приходилось размечать плоды и ягоды. Мы занимались разметкой виноградников, где нужно было выделить листья, сами виноградные гроздья, лозы и опоры, которые поддерживают растения. Каждая из этих частей размечалась полигонами, чтобы их можно было легко распознать на изображениях.

А еще мы сегментировали машины для каршеринга. Вначале необходимо было выделить контуры всей машины, затем на следующем этапе — каждую деталь кузова, включая фары и другие элементы.
Вы можете почитать гайды о том как использовать Instance Segmentation, Semantic Segmentation в зависимости от типов задач.

В заключительном этапе мы занимались разметкой повреждений на деталях, например, на бампере отмечали царапины. Работа требовала точности, особенно при выделении мельчайших повреждений на фотографиях.
Key Point Annotation
Key Point Annotation — это метод разметки ключевых точек, применяемый для анализа поз, распознавания жестов и мимики.
Важные точки могут быть помечены разными цветами в зависимости от классов. К примеру, правая рука размечается красными точками, левая — желтыми, что помогает модели точнее оценивать движения конечностей. Основная задача состоит в том, чтобы идентифицировать и аннотировать точки, которые имеют значение для анализа движений или структуры объекта.

Такая разметка сейчас используется во множестве индустрий, среди которых и спорт. Так, довольно часто keypoint annotation используется для отслеживания и анализа позы и движений во время тренировки.
Точки на суставах, таких как колени, локти и плечи, аннотируются для изучения техники выполнения упражнений, чтобы предотвратить травмы и улучшить производительность. Анализируя, как спортсмен приземляется после прыжка или выполняет подъем штанги, тренеры могут давать рекомендации по улучшению техники.
Pose Estimation
Pose Estimation — это более сложная задача, которая использует аннотированные ключевые точки для автоматического определения позы объекта или человека. Pose Estimation обычно включает в себя не только обнаружение ключевых точек, но и построение модели, которая отображает относительные положения этих точек друг к другу. Оно позволяет понять, как объект или человек расположен в пространстве.
Human Pose Estimation (оценка поз человека) — это одна из ключевых задач компьютерного зрения, направленная на определение положения человека в пространстве, а также на распознавание различных частей его тела. Этот процесс включает в себя определение и отслеживание семантических ключевых точек (“правое плечо” или “левое колено”). Эти точки представляют собой важные ориентиры на теле человека, которые используются для понимания его позы и движений.
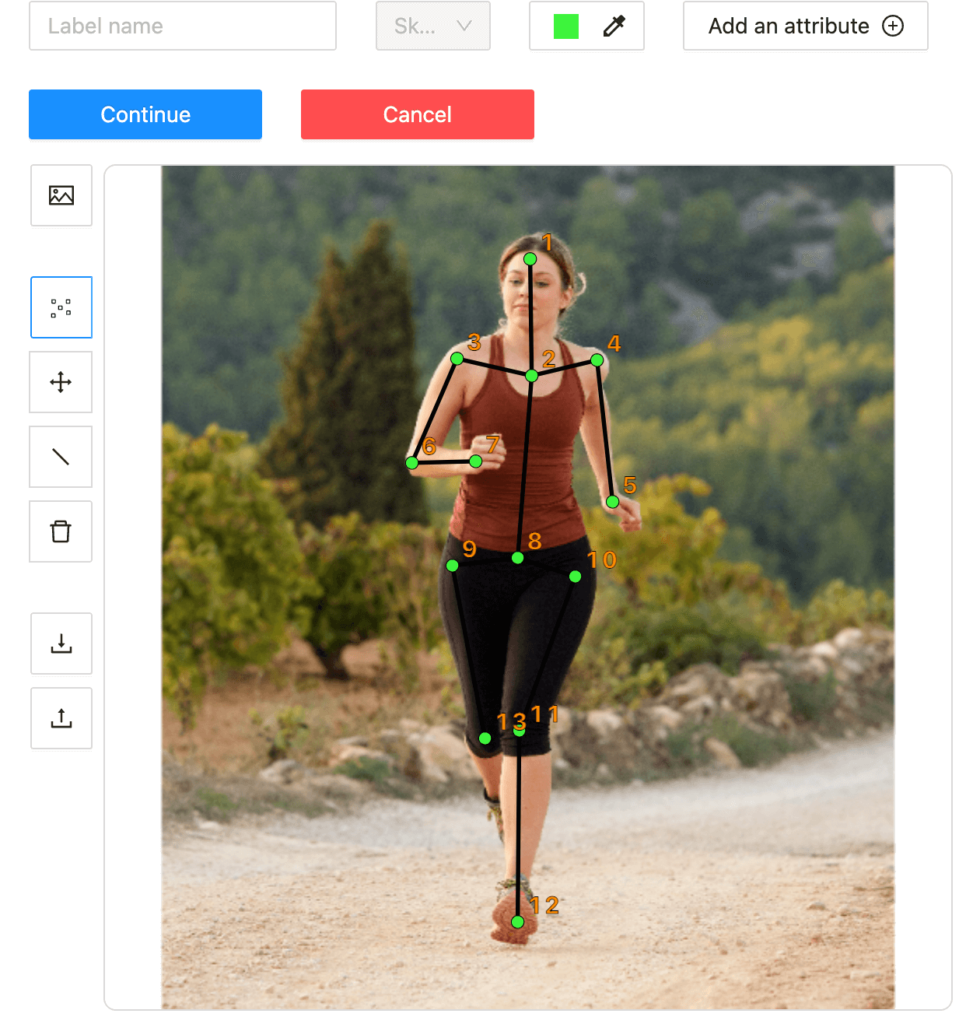
Также “скелетонами” мы можем размечать даже животных. К примеру, недавно клиент попросил нас аннотировать разные части тела и хвостик поросенка, чтобы распознавать его положение на ферме. Такое определение положения и активности свинок позволяет вовремя выявлять отклонения в поведении, которые могут указывать на проблемы со здоровьем.
Разметка аудио
Аудиоданные имеют еще больше динамики по сравнению с изображениями. Несколько факторов связаны с аудиофайлом, включая, но не ограничиваясь ими – язык, демографические данные говорящего, диалекты, настроение, намерение, эмоции, поведение. Чтобы алгоритмы эффективно обрабатывали данные, все эти параметры должны быть идентифицированы и помечены с использованием таких методов, как временная метка, маркировка аудио и другие. Кроме словесных сигналов, такие моменты, такие как тишина, вдохи и даже фоновый шум, могут быть аннотированы для более глубокого понимания системами.
Без разметки аудио, к примеру, виртуальные ассистенты не могли бы реагировать на команды пользователя и распознавать интонации собеседника. Существует несколько типов разметки для различных целей, среди которых:
Классификация аудио
В этом случае исполнители классифицируют аудиозапись по заранее определенным категориям: по эмоциональной окраске, количеству или типу говорящих, языку, фоновым шумам, намерениям или семантической информации.
Классификация музыки по жанрам или инструментам также предполагает разметки звука. Без этого не существовали бы рекомендации треков на основе ваших предпочтений в Spotify или Яндекс Музыке.
Транскрибация аудио
Для этого исполнители преобразуют аудиофайл в текст, затем он аннотируется. Аудиофайлы могут быть разного качества и содержать фоновые шумы или особенности произношения, они также получают соответствующие метки. Транскрибация преобразует звук в текст, что имеет решающее значение для обучения моделей машинного обучения пониманию человеческой речи. Чаще всего сейчас встречаются задачи разметки редких языков.
Сравнение аудио
Иногда исполнителям нужно прослушать два или более аудиофайла, чтобы определить, какой из них лучше соответствует заданным критериям. Например, аннотаторы могут помочь понять, какая из записанных речей звучит наиболее естественно, или совпадают ли голоса нескольких говорящих.
Разметка видео
Как мы знаем, само по себе видео — это набор изображений, создающих эффект движения объектов. Каждое изображение в этом наборе называется кадром. Поэтому во время аннотации видео процесс включает добавление ключевых точек, многоугольников или ограничивающих рамок для аннотирования различных объектов в кадре: к примеру, мы можем по кадрам разметить перемещение машин, отмечать, где автомобиль в кадре, а где он его покидает.
Когда мы соединяем кадры вместе, модели могут изучать движения, поведение и шаблоны, отслеживать объекты или локализовать какие-то предметы.
Разметка текста
Всем компаниям приходится обрабатывать разные вида текста: от отзывов клиентов в приложении до упоминаний в социальных сетях. В отличие от изображений и видео, которые в основном передают четкие намерения, текст сопровождается множеством семантических нюансов.
Большинство людей автоматически понимают контекст фразы, значения слов, предложения или фразы, мы соотносим их с определенной ситуацией или разговором и можем понять общий смысл высказывания. Но машины не способны на это в той же мере: сарказм, юмор и другие абстрактные элементы им неизвестны, поэтому маркировка текстовых данных становится сложнее.
Тут обычно мы выделяем такие задачи:
Семантическая разметка
Объекты, продукты и услуги становятся более релевантными благодаря соответствующей разметке ключевых фраз и параметров идентификации. Чат-боты также имитируют человеческие разговоры благодаря этим аннотациям.

У нас было несколько кейсов для персонализированных рекомендаций в электронной коммерции. Так, к нам пришел крупный интернет-магазин, который хотел улучшить систему рекомендаций для своих пользователей. Семантическая разметка помогла моделям ИИ распознавать ключевые фразы и параметры, которые описывают интересы и предпочтения пользователя, такие как «спортивные товары» или «дизайнерская одежда», чтобы предлагать более релевантные продукты.
Разметка намерений
Намерения пользователя и язык, который он использует, маркируются для того, чтобы машины могли понять контекст. Это позволяет моделям отличать запрос от команды, рекомендацию от бронирования и так далее.
Такие задачи часто используются для улучшения голосовых помощников. К примеру, в проекте по разработке голосового ассистента разметка намерений позволяет модели ИИ различать, когда пользователь просит установить будильник (“поставь будильник на 7 утра”), а когда — предлагает рекомендацию (“что ты посоветуешь на завтрак?”). Это помогает ассистенту лучше интерпретировать команды.
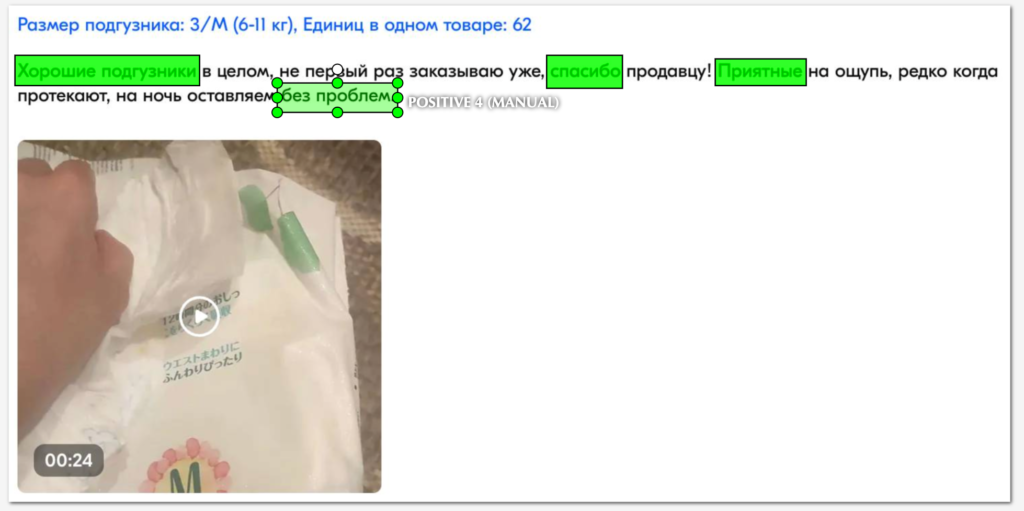
Разметка тональности
Этот вид аннотации включает маркировку текстовых данных в зависимости от выражаемой тональности, такой как положительная, отрицательная или нейтральная. Этот тип аннотации часто используется в анализе тональности, где модели ИИ обучаются понимать и оценивать эмоции, выражаемые в тексте.
В проекте по анализу отзывов о продуктах разметка тональности использовалась для классификации отзывов на положительные, отрицательные и нейтральные. Например, отзыв “Отличное качество, доставили вовремя” будет помечен как положительный, а “Товар не соответствует описанию, доставка задержалась” — как отрицательный. Это позволяет компании оперативно реагировать на проблемы и улучшать качество обслуживания.
Разметка сущностей
Здесь неструктурированные предложения маркируются, чтобы сделать их более значимыми и привести в формат, который может быть понятен машинам. Чтобы это произошло, задействуются два аспекта – распознавание именованных сущностей и связывание сущностей. Распознавание именованных сущностей – это когда имена мест, людей, событий, организаций и других объектов маркируются и идентифицируются. Связывание сущностей – это процесс связывания этих меток с предложениями, фразами, фактами или мнениями, которые их сопровождают. В совокупности эти два процесса устанавливают связь между текстом и окружающим его контекстом.
Так, один раз для нашего заказчика мы занялись проектом, где требовалось размечать различные элементы в документах, таких как договоры и технические паспорта. Задача заключалась в выделении нужных заказчику данных, например, информации о марке автомобиля, владельце или дате выдачи.
А в другом проекте мы занимались разметкой новостей, где нужно было выделять ключевые части текста и удалять лишнюю информацию.
Варианты разметки сущностей включают:
- Распознавание именованных сущностей (NER): Это подтип аннотации сущностей, который включает выделение и маркировку таких элементов, как имена людей, названия компаний и мест. NER используется в различных приложениях NLP, таких как анализ настроений и извлечение информации.
- Извлечение ключевых фраз: Этот метод направлен на выделение ключевых слов или фраз, которые представляют основные идеи или темы текста. Это важно для понимания контекста и содержания текста.
- POS: Так называется присвоение каждой части речи в предложении её грамматической категории. POS-теги помогают моделям ИИ понять структуру предложений и их значение.
- Связывание сущностей: Этот метод включает связывание именованных сущностей в тексте с соответствующими записями в базе данных, что позволяет предоставить дополнительную информацию о сущностях.
Классификация текста
Предложения или абзацы могут быть маркированы и классифицированы на основе тем, тенденций, предметов, мнений, категорий (спорт, развлечения и другие) и других параметров. Тут мы можем выделить:
- Категоризация документов: Автоматическое распределение документов по категориям на основе их содержания. Этот метод широко используется для управления большими объемами текстовых данных.
- Аннотация настроений: Определение и классификация эмоционального тона текста (положительного, отрицательного или нейтрального). Этот метод применяется для анализа отзывов клиентов, мониторинга социальных сетей и управления репутацией брендов.
- Аннотация намерений: Определение и маркировка намерения или цели текста, например, запрос на бронирование авиабилетов. Этот метод важен для разработки систем NLP, таких как чат-боты и виртуальные помощники.
К примеру, на нашем проекте, связанном с разметкой статей в СМИ, одним из ключевых этапов была классификация контента. Для каждой статьи определялась категория, к которой она относится: спорт, бизнес, политика и другие. Это позволяло структурировать контент и улучшить его последующую обработку и использование.
Направления, где используется разметка данных
Разметка данных используется в двух основных направлениях искусственного интеллекта: компьютерном зрении (CV) и обработке естественного языка (NLP). Выбор метода разметки зависит от типа данных, с которыми работают.
- Компьютерное зрение (CV): В компьютерном зрении разметка данных включает разметку визуальных элементов на изображениях и видео. Это необходимо для того, чтобы обучить модели ИИ выполнять задачи, такие как распознавание объектов, лиц, отслеживание движения и автономное вождение. Разметка предоставляет необходимые данные, которые помогают моделям ИИ точно понимать и интерпретировать визуальную информацию.
- Обработка естественного языка (NLP): В NLP разметка данных сосредоточена на текстовой информации и языковых элементах. Это может включать аннотирование текста на изображениях или обработку чисто текстовых данных. Цель разметки в NLP – обучить модели ИИ понимать человеческую речь, распознавать естественный язык и выполнять задачи, такие как классификация текста, анализ настроений, распознавание именованных сущностей и машинный перевод.
Автоматизация разметки
Ручные задачи, такие как очистка данных, аннотирование и маркировка, являются самыми трудоемкими частями любого проекта по компьютерному зрению. По данным Cognilytica, подготовка данных поглощает 80% времени, выделенного на большинство проектов по компьютерному зрению, при этом на разметку уходит 25% этого времени.
Автоматизация задач разметки данных с помощью инструментов и программного обеспечения на базе AI значительно сокращает время, необходимое для подготовки модели к производству. Она имеет свою специфику:
| Полуавтоматическая разметка | Автоматическая разметка | Ручная разметка |
|---|---|---|
| В данном подходе алгоритмы и модели машинного обучения выступают в роли помощников, ускоряя и облегчая процесс разметки.К примеру, системы могут самостоятельно распознавать лица на изображениях, а разметчики занимаются только уточнением и корректировкой этих данных.Такой тип разметки действительно может ускорить работу над проектом: к примеру, недавно с помощью предразметки мы в два раза увеличили скорость на проекте по детекции объектов. | В этом случае алгоритмы самостоятельно выполняют разметку данных.Такой подход иногда используется для обработки текстовых данных с помощью анализа естественного языка. | Этот процесс предполагает, что аннотаторы вручную размечают данные, используя специальные программные инструменты. Например, при разметке изображений исполнители могут выделять объекты и назначать им соответствующие категории.Если вам нужно разметить небольшую выборку данных, к примеру, 10 тысяч изображений, то этот тип разметки отлично вам подойдет. А вот для 10 миллионов лучше воспользоваться предразметкой. |
На самом деле нет идеальной опции для универсальных задач: ручная разметка данных обеспечивает больший контроль и точность, но может быть трудоёмкой и времязатратной. Автоматизация же обеспечивает скорость, но точность ее может быть ниже, поэтому вам все равно понадобится валидация.
Ошибки можно найти как в автоматической, так и в ручной разметке: аннотаторы обычно допускают ошибки случайного типа, а модели будут делать систематические ошибки из-за несовершенности обучения.
Поэтому при выборе между двумя методами можно проанализировать требования проекта, бюджет и желаемый уровень точности.
Советы по разметке данных
Разметка данных имеет ряд неочевидных, но очень важных моментов, о которых мы не можем забывать. Мы собрали несколько главных пунктов, на которые стоит обращать внимание в первую очередь:
Четкое и правильно составленное ТЗ
Наш совет — стандартизируйте каждый шаг процесса постановки и решения задачи, составив краткую, но информативную инструкцию (в идеале — с иллюстрациями). Такой мануал поможет избежать ошибок как у новичков, так и у опытных аннотаторов.
Инструкция должна регулярно обновляться. К примеру, мы в Data Light фиксируем все решения сложных случаев, с которыми аннотаторы сталкиваются в процессе разметки. Еще для всех проектов дольше 14 дней мы обязательно проводим тестирование: от 10 до 20 вопросов. Так мы оцениваем понимания ТЗ по проекту и выявляем пробелы в знаниях команды.
Инструменты
Один из ключевых аспектов успешной разметки данных — правильный подбор инструментов. Под каждую конкретную задачу существует множество специализированных программ и платформ, и их эффективность может значительно различаться в зависимости от типа данных и целей проекта. Например, один инструмент может идеально подходить для разметки изображений, но оказаться менее удобным для обработки текста или аудио.
Кстати, мы подробно сравнивали популярные инструменты и их специфику в нашей статье про CVAT — обязательно ее прочитайте!
Команда
Важно понимать, что подбор команды должен осуществляться с учетом специфики задачи. Например, если проект требует глубокой экспертизы, как это бывает с разметкой медицинских данных или архитектурных объектов, имеет смысл привлекать специалистов с соответствующим опытом. Это может быть дороже, но в таких случаях точность и качество разметки оправдывают затраты.
Но в некоторых случаях стоимость услуг экспертов может превысить выгоду от проекта. Поэтому оценка экономической целесообразности играет ключевую роль при выборе разметчиков для каждого отдельного случая.
Поэтому часто, если задача не требует специфических знаний, можно использовать разметчиков с базовым уровнем подготовки, что позволит оптимизировать затраты без потери качества.
Качество данных
Если количество данных у компании ограничено, что часто случается на русском языке, часто приходится искать «сырые данные». Инженеры часто вынуждены выбирать датасеты, максимально приближенные к целевой теме.
Но такое низкое качество исходных данных может негативно сказаться как на этапе обучения модели, так и в процессе её валидации, где оцениваются метрики точности и эффективности решения задачи. Поэтому гораздо разумнее сосредоточиться на улучшении имеющегося, пусть и ограниченного, датасета, чем “кормить” модель все новыми, но нерепрезентативными данными.
Секреты эффективной валидации
Недостаточно просто разметить данные, для высокого качества важно их правильно провалидировать. В Data Light есть целая система, которая позволяет нам показывать стабильно высокое качество на наших проектах:
Согласованность: Одинаковые решения по кейсам — один из ключевых факторов, влияющих на качество проекта. В Data Light, чтобы поддерживать высокий уровень согласованности среди членов команды, мы оцениваем, насколько слаженно они принимают решения. Для этого разные валидаторы в рамках одного проекта получают один и тот же кейс для решения.
В итоговой оценке согласованности участвуют руководители групп, которые являются экспертами по техническому заданию. Они также размечают аналогичные кейсы, что позволяет нам убедиться в том, что все участники команды следуют единому стандарту и понимают задачи одинаково.
Ремониторинг: Для обеспечения высокого качества работы отдела контроля качества проводится ремониторинг. В каждом проекте мы проводим выборочный анализ ответов каждого валидатора, оценивая, насколько правильно он определяет действия, соответствуют ли его решения актуальным обновлениям, и корректно ли подтверждены кейсы.
Проверка ошибок: После этого мы анализируем работу валидаторов, обращая особое внимание на типичные ошибки, допущенные ранее, а также на те группы ошибок, которые наиболее часто встречаются в проекте. Наша задача — убедиться, что все необходимые корректировки были успешно внедрены и что валидатор правильно интерпретирует и решает кейсы после изменений.