 Разметка данных
Разметка данных Сбор данных
Сбор данных Модерация контента
Модерация контента Тайные проверки
Тайные проверки О нас
О нас Контакты
КонтактыПодготовка датасета — это один из самых важных и трудоемких этапов в процессе разработки моделей машинного обучения. В этой статье мы рассмотрим все ключевые этапы подготовки датасета и дадим рекомендации, как избежать типичных ошибок.
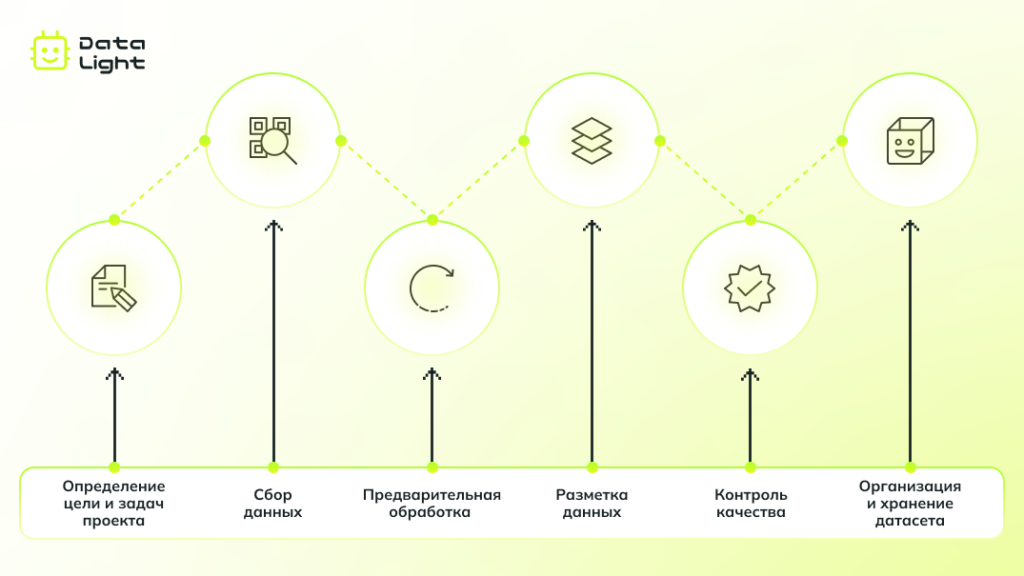
Этап 1: Определение цели и задач проекта
Подготовка датасета начинается с четкого понимания того, зачем вам нужны данные. Чем яснее вы определите цель, тем проще будет двигаться дальше.
Сформулируйте задачу будущей модели
Укажите, какую задачу будет решать модель и каких результатов вы от нее ожидаете, например:
- Классификация — присвоение данным одной или нескольких из заранее заданных категорий (классификация писем по категориям спам / не спам).
- Регрессия — прогнозирование числового значения (предсказание цены недвижимости на основе площади и местоположения).
- Сегментация изображений — разбиение изображения на смысловые части (выделение отдельных органов на медицинском снимке).
- Обработка естественного языка (NLP) — анализ текстовых данных (извлечение названий организаций из юридических документов, определение тональности отзывов).
Установите требования к данным
После того как задача определена, необходимо понять, какие данные понадобятся для ее решения. Это поможет избежать сбора ненужных данных и обеспечить достаточное качество обучающих примеров.
- Тип данных: Уточните, какие форматы данных вам понадобятся, исходя из задачи. Это могут быть изображения, видео, текстовые данные, числовые значения или аудио.
- Необходимые признаки: Определите, какие признаки данных являются наиболее важными для решения задачи. Например, в случае с изображениями важно, чтобы на них были определенные объекты.
- Объем данных: Оцените, сколько данных потребуется для качественного обучения модели. Недостаточное количество данных может привести к тому, что модель не будет достаточно точной. В то же время слишком большое количество данных может усложнить процесс обработки. Важно найти баланс, исходя из сложности проекта и доступных ресурсов.
Этап 2: Сбор данных: источники и методы
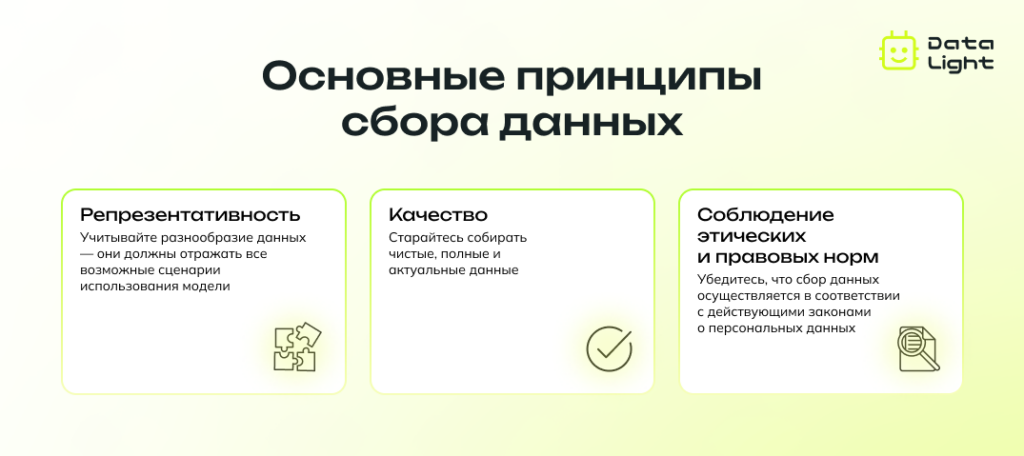
Сбор данных — это основа для создания качественного датасета. В зависимости от задачи, существует несколько типов источников, из которых можно собрать данные:
Внешние данные
К внешним данным относятся сведения, полученные из публичных источников. Это могут быть открытые базы данных, отчеты государственных учреждений, исследования аналитических центров, информация из социальных сетей и других онлайн-ресурсов.
Внутренние данные
Внутренние данные — это информация, которая собирается компанией или организацией в процессе ее деятельности, например, это могут быть логи системы или метрики пользовательского поведения. Такие данные зачастую являются максимально релевантными для специфических задач, поскольку они напрямую связаны с операциями внутри компании.
Сбор реальных данных
Метод, при котором информация собирается самостоятельно и напрямую из окружающей среды с использованием сенсоров, камер, микрофонов или других записывающих устройств. Применяется, когда необходимо контролировать процесс сбора и гарантировать высокую точность данных.
Краудсорсинг
Краудсорсинг — это метод сбора данных с привлечением большого числа участников через онлайн-платформы. Он позволяет быстро и относительно недорого получать большие объемы информации с широким разнообразием примеров. Этот подход особенно полезен, когда важнее количество данных, чем их точность.
Генерация синтетических данных
Синтетические данные — это искусственно созданные данные, которые генерируются с использованием алгоритмов и моделей. Часто применяются как вспомогательный инструмент для расширения существующего набора данных, особенно когда некоторых примеров изначально не хватает или их невозможно собрать из-за требований конфиденциальности.

Услуги по сбору и продаже данных
Если самостоятельный сбор невозможен, можно воспользоваться услугами сторонних организаций, которые предлагают услуги по продаже готовых датасетов или их подготовке под конкретные нужды проекта.
Этап 3: Предварительная обработка данных
После сбора данных следующим этапом является их предварительная обработка. Это важная часть работы, так как данные, даже собранные с использованием самых современных методов, могут содержать ошибки, пропуски или быть представлены в неверном формате. Предварительная обработка помогает устранить эти проблемы, улучшить качество данных и подготовить их для эффективного обучения модели.
Очистка данных
Очистка данных — это процесс удаления или исправления некорректной, неполной или дублированной информации. Процесс очистки может включать:
Обнаружение выбросов (Outlier Detection)
Некоторые значения в данных могут значительно отличаться от остальных. Например, если в наборе данных о доходах сотрудников указана сумма в 10 миллионов долларов, а средний уровень зарплат в компании составляет 5 тысяч долларов, это, скорее всего, ошибка или аномальный случай. Такие выбросы могут сильно повлиять на статистические показатели модели, поэтому их необходимо выявлять и корректировать — исключать, заменять средним значением или обрабатывать иным способом в зависимости от контекста.
Нормализация и масштабирование (Normalization and Scaling)
Когда признаки данных измеряются в разных единицах, имеют разный масштаб и числовой диапазон, модель может воспринимать их как несоразмерные величины. Например, если один признак указывает время в часах, а другой — в минутах. Нормализация и масштабирование позволяют привести все признаки к единому масштабу, чтобы модель могла корректно оценивать их значимость и обучаться более эффективно.
Обработка пропущенных значений (Handling Missing Data)
В реальных данных часто бывают пропуски — отсутствующие значения. Такие пропуски могут создать проблемы для обобщающей способности модели. Существует несколько способов их обработки: можно удалить строки с пропущенными данными, если их мало, заполнить пропущенные значения средним значением по этому столбцу или использовать более сложные методы для восстановления данных.
Анонимизация данных
Если собранные данные содержат персональную информацию, такую как имена, адреса, номера телефонов или другие идентифицирующие сведения, важно провести их анонимизацию, чтобы обеспечить конфиденциальность и соблюдение законодательства (например, GDPR или HIPAA).
Эти шаги важны для того, чтобы данные стали правильными, последовательными и удобными для работы. Чем чище и безопаснее данные, тем более точными и стабильными будут результаты модели.
Этап 4: Разметка данных
Если задача машинного обучения предполагает обучение модели с учителем, то для ее решения потребуются размеченные данные. На этом этапе к исходным данным, будь то изображения, тексты, видео или аудио, добавляются метки, с помощью которых модель учится распознавать закономерности и делать предсказания.
Методы разметки данных
Ручная разметка
Этот метод предполагает, что специалисты вручную присваивают метки каждому элементу в наборе данных. Ручная разметка гарантирует высокую точность аннотаций, но требует значительных временных затрат. Оптимальный вариант для задач, где необходима высокая детализация и точность.
Автоматическая разметка
Для ускорения процесса часто используют алгоритмы, которые автоматически присваивают метки данным. Это экономит время, но качество такой разметки может быть значительно ниже.
Полуавтоматическая разметка
Этот подход сочетает в себе оба метода: алгоритмы выполняют первичную разметку, а специалисты проверяют и корректируют ее, обеспечивая оптимальный баланс между скоростью и точностью.
Выбор метода разметки зависит от нескольких факторов:
- Объем данных: для небольших объемов данных эффективнее использовать ручную разметку, для больших — автоматическую или полуавтоматическую.
- Сложность задачи: если задача требует высокого уровня детализации или работы с редкими, специфическими данными, лучше использовать ручную разметку.
Ресурсы проекта: доступное время, количество специалистов и бюджет также играют ключевую роль в принятии решения. Если ресурсы ограничены, возможно, будет лучше использовать автоматические или полуавтоматические решения, которые позволяют быстрее обработать данные с меньшими затратами.
Обеспечение точности и согласованности разметки
Помимо выбора оптимального метода, также важно обеспечить точность и согласованность разметки:
- Точность разметки означает, что метки, присвоенные данным, должны точно отражать суть объекта или явления, которое они описывают. Например, если задача состоит в классификации изображений, каждый объект должен быть правильно отнесен к своей категории («собака», «машина», «дерево» и т. д.). Ошибочные метки могут запутать модель и снизить ее точность.
- Согласованность разметки означает единообразие в подходе к аннотированию данных. Разные специалисты могут по-разному интерпретировать границы объектов или их характеристики, что приводит к несоответствиям в данных. Чтобы избежать расхождений, необходимо разработать четкие инструкции, которым будут следовать все участники процесса.
Экспорт размеченных данных
После того как разметка данных завершена, полученные результаты сохраняются в формате, который легко интегрировать в систему машинного обучения, например, в CSV, JSON или XML. В некоторых случаях используются специализированные форматы, такие как COCO или Pascal VOC.
Этап 5: Контроль качества
После завершения всех предыдущих этапов важно провести проверку подготовленных данных, так как любые пропущенные ошибки могут негативно сказаться на работе модели.
Проверка случайных выборок
Один из эффективных методов контроля качества — проверка случайных выборок. Специалисты вручную проверяют несколько случайных примеров из набора данных, чтобы убедиться в их правильной разметке и соответствии заданным критериям. Этот подход позволяет выявлять распространенные ошибки без необходимости полной проверки всего датасета.
Автоматическое тестирование
Для более крупных наборов данных часто используются автоматизированные инструменты и скрипты, которые могут анализировать данные на наличие ошибок и аномалий. Например, алгоритмы могут проверять корректность формата данных, наличие дублированных меток или пробелов в разметке, что значительно ускоряет процесс и позволяет минимизировать влияние человеческого фактора.
Этап 6: Организация и хранение датасета
После завершения разметки и проверки качества необходимо правильно организовать данные, чтобы упростить их дальнейшее использование. Грамотная структура хранения облегчает доступ к файлам и ускоряет процесс работы с датасетом.
Структура и организация данных
Включает в себя создание структуры папок, удобной для хранения всех файлов. Структура должна быть логичной и последовательной, чтобы избежать путаницы при дальнейшем использовании. Особенно важно это для сложных датасетов, содержащих несколько типов информации.
Дополнительно уже на этом этапе данные могут быть разделены на три выборки:
- Тренировочная выборка (Training Set): 70–80% данных, которые используются для обучения модели.
- Валидационная выборка (Validation Set): 10–15% данных, применяемых для настройки гиперпараметров и оценки производительности на этапе обучения.
- Тестовая выборка (Test Set): 10–15% данных, которые используются для итоговой проверки качества модели.
Документация и метаданные
Кроме того, важной частью организации данных является создание документации, которая описывает структуру, содержание и особенности датасета. В документации должно быть указано, какие данные содержатся в датасете, как они были собраны, какие методы использовались для разметки, а также описание ограничений на использование. Такая документация облегчает работу разработчиков, позволяя им быстро разобраться в содержимом и понять, как правильно использовать датасет.
Управление доступом
И последнее: важно, чтобы доступ к данным был защищен и только авторизованные пользователи могли вносить изменения или удалять файлы. Для хранения и доступа к данным можно использовать разные инструменты, в зависимости от потребностей проекта. Одним из самых популярных решений является облачное хранилище, например, Amazon S3, Google Cloud Storage или Microsoft Azure Blob Storage. Эти сервисы позволяют безопасно и масштабируемо хранить большие объемы данных.
Ключевые выводы
Подготовка датасета — это многоэтапный процесс, требующий внимательного подхода. Важно не только найти источники информации, но и обработать данные, очистить их от ошибок, разметить и проверить качество. Грамотная организация и хранение данных обеспечивают удобство работы и повышают точность модели. Чем лучше подготовлен датасет, тем надежнее будут результаты машинного обучения.